Perl修炼秘籍
这是一本Perl的学习秘籍,从入门到深入,本书假设读者已经具有最基本的编程知识,比如关于什么是变量、什么是字面量、什么是数组、什么是函数等等,本书不会从零开始介绍这些基本概念,而是直接介绍Perl中这些概念的表现形式、语法、用法和内部细节,有时候也会在尚未介绍这些概念时就简单使用它们。
Perl入门第一堂课
本章简单介绍Perl的一些特性以及Perl最基本的入门语法。
Perl简介
Perl简介
Perl是一门通用语言,其他语言能做的,Perl基本上也都能做。但Perl在文本处理方面、正则表达式方面一骑绝尘。
如果不使用Perl写通用程序或大型程序,可以将Perl基础部分看作高级Shell脚本语言,很多方面和Shell有相似之处。所以熟悉Linux命令行或Shell脚本的人,对Perl是很有亲切感的。
例如:
# 下面是一段perl代码
$name = "junmajinlong.com"; # 和shell一样,变量也是$开头
print "my name is: $name"; # 和shell一样,双引号里也可以变量替换
# 和shell一样,调用函数(命令)可以不加括号
其实,学习过Shell的人应该都会觉得,Shell的语法和特性比较零散,学习过程中基本上是靠强行记忆,它的知识点不够密集,导致不太容易系统性地学好Shell,或者学过之后很容易忘记它的语法和特性。相比于Shell,Perl的通用语法更规范、更密集且更语言化(注:在遵循通用语法的情况下,Perl有非常多的技巧性语法),只要根据Perl的语法规则去学习,就可以系统性地学好Perl。因此,可能让很多人难以置信的是,学习Perl实际上比学习Shell更容易。
Perl还支持一行式命令(one-liner),它方便到离谱。在熟悉Perl基础部分以及它的一行式命令写法之后,基本上可以通过一个perl命令取代Linux命令行下的grep、sed、awk、sort、uniq、cut等等一大堆命令。即使你更熟悉、更喜欢这些已经用习惯了的命令,也可以把perl一行式当作和它们一样的通用命令并结合使用。例如:
# 学会perl一行式以前
$ grep aaa | sed bbb | cut ccc | awk ddd | sort
# 学会perl一行式以后
$ perl -e 'xxxx'
# 也可以将perl命令结合其他命令参与到文本处理中
$ sed aaa | perl -e 'xxx' | awk 'yyy'
Perl语言还是一门非常灵活的语言,解决同样一种需求,Perl可能比其他编程语言多很多种解法,即一题多解,或【There’s more than one way to do it】。这使得其他编程语言的一些使用者以此为由发起对Perl的语言之战,特别是Python(因为现在用Python的人多),和Perl的灵活相反,Python要规范的多,多数时候是一题一解,即【There is only one way to do it】。有的人喜欢规规矩矩的写代码完成需求,简单轻松,而有的人则喜欢放飞思维写灵活的代码,有趣。
另外,Perl语言大量使用各种各样的符号(如$@{}%_/等),这又使得其他编程语言的一些使用者以此为由发起对Perl的语言之战:丑陋、难读难写难记。其实,这些符号熟悉了之后都一样,甚至有些人(特别是熟悉Shell的人)会认为这些符号很亲切可爱。就像全世界有各种各样的文字,对于语种A,不以之为母语的人都会觉得其他文字符号丑陋、难读难写难记,但以A为母语或喜欢研究A的人不大可能会有这样的想法。
也许在一个团队中用Perl写大型程序不太友好,但是作为个人语言,Perl非常合适。
最后总结一下,只要不带着跟风的偏见去学习Perl,Perl的基础部分很容易掌握,仅靠基础知识,就足够在文本处理任务上大放异彩。
Perl试手
Perl试手
在开始正式介绍Perl的内容之前,先对Perl最基本的一些用法混个眼熟。
-
Unix系统下,Perl脚本第一行使用
#!。Perl脚本的后缀名一般为【.plx】或【.pl】,运行时使用perl NAME.plx即可例如,1.pl内容如下:
#!/usr/bin/perl print "hello world\n"执行该脚本:
$ perl 1.plWindows系统下,不要加
#!,因为Windows是通过关联打开.pl文件类型的应用程序来运行的。 -
Perl脚本中,除了注释行和代码块的最后一行,每行都需要以
;结尾 -
Perl使用#作为注释符号,所以只支持单行注释、行尾注释
# 这是单行注释 print "hello world\n"; # 行尾注释 -
Perl中变量有三种数据类型:标量、数组、hash
-
标量是存放单个数据的类型,标量使用
$符号前缀来表示,如$name -
数组是存放一系列数据的类型,数组使用
@符号前缀,如@names -
hash是存放键值对(key-value)的数据类型,hash通常也称为映射、字典、关联数组,hash使用
%符号前缀,如%person -
其实上面关于前缀的说法是不准确的,但暂时这样理解,以免还未入门就放弃Perl
# 变量name是一个标量类型,只保存了一个字符串数据 $name = "junmajinlong"; # 变量language是一个数组类型,可保存多个数据 @languages = ("Perl", "Ruby", "Shell", "Rust"); # 变量person是一个hash类型,可保存key-value键值对数据 %person = (name => "junmajinlong", age => 23,); -
-
Perl常使用print()、say()、和printf()进行输出
- print()输出时不加尾部换行符
- printf()用于格式化输出
- say()和print()类似,但输出时自动加尾部换行符,但使用say()时要求至少使用perl v5.10版本或开启say特性
print "hello world", "\n"; # 手动加上行尾换行符 print "hello world\n"; # 效果同上 printf "name: %s\n", "junmajinlong"; use 5.010; # 指定使用Perl v5.10版本 say "hello world"; # 自动在行尾加上换行符 -
use关键字可用于指定使用哪个包、哪个特性、哪个版本的perl,等
# 指定使用Time::HiRes包中的time函数 use Time::Hires qw(time); # 指定使用say特性 use features 'say'; # 指定使用Perl 5.10版本 use 5.010;注意,上面use指定版本的版本值是5.010而不是5.10,
use 5.10会被perl认为是5.100版如果指定更细致的小版本号,如5.10.1版,则:use 5.010001;。也可以以如下方式指定版本号:
use v5.10; -
Perl中调用自带的内置函数时,可以使用括号传递参数,也可以省略括号。但省略括号时,有时候需要注意陷阱
例如,调用print函数:
print("hello world\n"); print "hello world\n"; -
Perl中的双引号字符串内,可以使用变量替换、表达式替换。这种行为称为字符串的变量内插(interpolation)和表达式内插
# 变量内插 $name = "junmajinlong"; print "name: $name\n"; # 表达式内插,直接强记表达式内插语法:@{[EXPR]} print "10 + 10 = @{[10+10]}"; -
Perl中不需要对变量进行声明,可以直接赋值、使用
# 全局变量 $var=12; # 或者使用my、our等关键字定义有作用域的变量 my $var = 23; print $var; -
可以在每个Perl脚本中加上
use strict语句,这是写稍大一点的Perl程序时的一种规范strict模式使得Perl编译器以严格的态度对待Perl程序,比如不允许使用未定义的变量、不允许直接定义全局变量。
use strict; # strict模式 $var = "hello"; # 错,不允许直接定义全局变量 print "$x"; # 错,不允许使用未定义的变量当指定使用的perl版本为
v5.12或更高,则自动进入strict模式,因此可以省略use strict;。 -
可以加上warning信息进行调试,perl将在需要提示的地方发出警告
use warnings;或者
perl -w,或者在Perl脚本中:#!/usr/bin/perl -w -
如果Perl脚本中使用了中文(或其他多字节字符),建议加上
use utf8;,否则结果可能会偏离期待 -
为变量、函数取名时,应符合标识符规范:由大小写字母、下划线、数字组成,且不是数字开头。但注意,Perl自身使用了大量特殊字符,有很多内置变量不符合标识符规范,例如
$!、@_等变量 -
Perl中可以通过反引号来执行操作系统中的命令
$var=`date +"%F %T"` print $var
Perl变量和字面量
本章介绍Perl中变量的基础内容、数值字面量、字符串字面量。
Perl中这些内容可以非常简单,只了解它们的基本用法即可,但这些内容也可以非常深入,它们可能涉及到很多Perl的语法解析规则。
无论是掌握简单用法还是要去深入理解,都需要明确一件事:Perl中的这些内容比想象中更为灵活,也更为复杂,意味着也更容易出错。比如,一个变量赋值的需求可能有多种实现方式。对熟悉Perl语法解析规则的人来说,这可能会少写很多冗余代码,但不熟悉Perl解析规则的人,很可能会写出四不像的错误代码,从而抱怨甚至攻击Perl为何如此不按常理出牌。
不要抱怨,因为你所写的代码和你掌握Perl解析规则的程度是正相关的。换个角度来看,随着你掌握的解析规则越多,写出来的代码就越具有Perl风格,代码可能就会越短小精悍。
如果不能确保自己真的知道自己所写代码的含义,那么就按照最严格、最规矩的方式去编写代码,以保证代码的正确性,多写几行代码或写规规矩矩的代码,并不会因此而显得更low。
Perl变量基础
Perl变量基础
Perl中的变量可以是标量类型、数组类型或hash类型的,标量类型的变量在变量名前使用$前缀,数组类型的变量在变量名前使用@前缀,hash类型的变量在变量名前使用%前缀。
Perl严格区分标量、数组、hash这三种类型,因为这决定了perl如何划分内存空间来保存数据:
- 标量类型意味着只保存单个数据,perl会为这样的变量分配用于保存单个数据的内存空间
- 数组类型意味着可保存多个数据,perl会为这样的变量分配用于保存多个数据的连续内存空间
- hash类型意味着可保存多个key-value键值对数据,perl会为这样的变量分配用于保存多个键值对数据的内存空间
参考下面的简图:
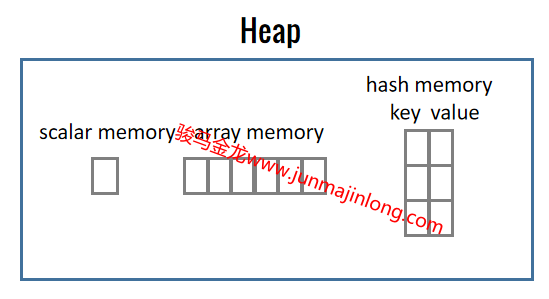
由于数组和hash要留在后面的章节中介绍,加之变量的使用也比较灵活,因此这里仅介绍一些标量类型的变量的基础用法。
变量声明和变量赋值
声明全局变量并为变量赋值:
$name = "junmajinlong";
print $name, "\n";
使用变量时,可以使用$name的方式,也可以使用更安全更标准的${name}方式。有时候必须使用${name}这个形式来使用变量name,否则会产生歧义。
例如,假如声明并赋值了变量name,如果在双引号字符串中使用变量内插,那么"$namehello"很可能是错误的写法(但不一定会报错),因为这会寻找名为namehello的变量而不是名为name的变量,因此,写成"${name}hello"可能才是正确的。
Perl也允许直接使用未声明、未赋值的变量,此时将根据上下文来决定该变量(这里暂且只考虑标量变量)的值是undef还是空字符串还是数值0。
use 5.010;
say "name: $name"; # 未声明变量在字符串上下文中当作空字符串使用
say "age: ", $age + 20; # 未声明变量在数值上下文中当作数值0使用
但是注意,在strict模式下,不允许声明全局变量,也不允许使用未声明的变量。
在strict模式下,需要使用my来声明变量,此时可以先声明,后赋值。已声明但未手动赋值的变量,默认被初始化赋值为undef值。
use strict;
my $age; # 先声明,默认被初始化赋值为undef
$age = 23; # 再赋值
my $name = "junmajinlong"; # 声明并赋值
print "$name, $age\n";
Perl中的变量可以重复声明,后声明的变量将掩盖(mask)已声明的变量。如果开启了warning,将给出变量掩盖的警告信息。
my $name = "junmajinlong";
my $name = "gaoxiaofang";
实际上,变量保存的是指向内存中数据的引用(指针),重新声明或重新赋值变量只是改变了变量中保存的指针所指向的内存位置。上例中,name标量中保存的是指向堆内存中字符串junmajinlong的指针,随后重新声明并赋值,表示让name保存指向堆内存中字符串gaoxiaofang的指针。但是,之前的变量name和它指向的数据junmajinlong并没有消失,它只是被掩盖了而无法再被使用,这意味着这部分内存数据将无法被回收。
Perl中的变量只区分是标量、数组还是hash,这决定了perl如何为它们划分内存空间。但是,它们所保存的实际数据不区分数据类型。比如,标量可以保存字符串,也可以保存数值。
my $name = "junmajinlong"; # name标量中保存字符串类型的数据
$name = 233; # name标量中保存数值类型的数据
$name = 2.3; # name标量中保存浮点数类型的数据
Perl中的变量赋值自身也有返回值,它的返回值是变量自身(或者说是左值lvalue)。多数时候,也可以将变量赋值看作是返回变量所保存的值。
# 先执行my $y = "hello",它返回$y
# 再执行赋值操作$x = $y
# 使得$x和$y都保存了"hello"
my $x = my $y = "hello";
因为变量赋值返回变量自身,因此,可以直接在赋值语句上执行那些会原地修改的操作,这会直接修改变量:
use v5.12;
my $y = "hello";
# 先执行赋值,使得$x也保存字符串数据"hello"
# 然后返回变量自身$x作为左值,参与s///替换
# 因此替换后,$x已被修改
( my $x = $y ) =~ s/.*/12345/;
say $x; // 12345
say $y; // hello
Perl中可以一次性为多个变量赋值。
# 下面两条语句等价,但显然第一条语句更简洁
my ($x, $y, $z) = (11, 22, 33);
my $x = 11, my $y = 22, my $z = 33;
对于Perl来说,这两条等价的赋值语句很有研究意义,但是在这里却无法展开介绍。因此,留待后续章节再述。
Perl中执行赋值语句时,总是先计算赋值操作符(即等号=)右边的表达式,然后将表达式的结果赋值给左边的变量(严格来说是左值lvalue)。
# 先计算第一个`=`右边的表达式,即`my $y = 22`,
# 发现该表达式还是一个赋值表达式,于是再计算
# 第二个`=`右边的表达式,即数值22,于是将22赋值
# 给$y,而$y = 22返回$y自身,于是将$y的值赋值给$x
my $x = my $y = 22;
将一次性为多个变量赋值的特性和先计算赋值操作符右边表达式的特性结合起来,使得交换变量变得非常轻松:
my $x = 22;
my $y = 33;
($x, $y) = ($y, $x); # 赋值之后,$x=33,$y=22
甚至,允许保存外部作用域中的同名变量的值:
my $x = 22;
{
# 将大括号外面的$x的值赋值给当前作用域内的$x
my $x = $x;
$x = $x + 1; # 修改当前作用域内的$x
say $x; # 23
}
say $x; # 22
关于my和局部变量
不使用my声明的变量是全局变量,my声明的变量是局部变量,它有自己生效的作用域范围。关于作用域规则,在后面会详细介绍。这里只需要知道,大括号是一个独立的作用域。
my $out = 11;
$global_out = 111; # 全局变量
{
my $in = 22;
$global_in = 222; # 全局变量
}
print $global_in; # 222
除了使用my声明变量,还可以使用our、local、state声明变量,它们都有自己的变量作用域规则,但目前无需深究它们的用法。
那么是直接声明全局变量还是使用my声明局部变量?几乎任何一种语言,任何一个有编程经验的人,都建议尽量使用局部变量,且少用全局变量。
但是,在Perl里面可以忽略这样的建议,至少需要看情况来决定是否使用局部变量:
- 写行数较多的Perl脚本时(功能相对复杂),尽量使用my声明局部变量
- 写涉及多个Perl文件(即使用了package时)的Perl程序时,尽量使用my声明局部变量,甚至要合理使用out、local
- 写较小的Perl脚本、写一个简单的Perl命令工具时,请随意,因为这时即使使用全局变量出问题也很容易调试
- 写Perl一行式命令时,全部使用全局变量,尽可能地缩减命令行的字符数量,如非必须,否则不要使用my声明局部变量,因为没有必要
undef和defined()
在Perl中,如果一个变量未声明,那么这个变量会被当作undef来使用,如果声明了变量,但未手动赋值,那么这个变量会被初始化赋值为undef。也可以将undef赋值给某个变量,使得这个变量回到未赋值状态。
say $name; # 使用未声明变量
my $age; # 声明变量但未手动赋值
my $gender = undef; # 手动赋值为undef
在strict模式下,不允许使用未声明变量,但可以使用undef值,而在warnings模式下,某些地方使用未声明值(undef)将给出警告。
实际上,undef是一个函数,但几乎总是可以将它当作一种表示未定义的值来看待。
undef作为值,表示的含义是此处缺失或没有,例如$age=undef(这里调用了undef函数)表示age变量缺失数据、没有数据。
undef作为函数,如果不给任何参数,将直接返回未定义值,如果undef一个变量(如undef $name),则取消变量的声明。
undef可以当作数值0或空字符串使用,它自身也代表布尔假。例如:
my $age;
say $age + 1; # 1
say "age: $age"; # age: 空字符串
很多场景下需要判断一个值是否是undef,Perl提供了defined()函数,当测试的值为undef时,返回undef,否则返回1(Perl中使用1代表布尔真值)。
my $name = "junmajinlong";
say defined($name); # 1
if(defined($age)){
say "defined";
} else {
say "undefined";
}
深入理解Perl的变量
深入理解Perl的变量
建议先看理解变量、数据类型、引用和内存https://junmajinlong.com/coding/variable_datatype_reference_memory/,了解一些有关于变量本质的内容之后,再看本文Perl中变量的行为,收获将更大。
Perl变量是一个引用
对于下面的变量赋值代码,这表示将内存中的字符串数据"junmajinlong"保存到变量name中去。
my $name = "junmajinlong";
注意,这里的变量名是name,而不是$name,前缀$符号具有特殊意义。不仅如此,数组变量的前缀@、hash变量的前缀%也一样如此。这些前缀的意义将在后文详细解释。
# 下面两个变量的变量名分别为names和person,而不是@names、%person
my @names = ("junmajinlong", "gaoxiaofang", "fairy");
my %person = (name => "junmajinlong", age => 23, );
Perl变量完全使用引用的方式去存储数据。这意味着,对于上面的name变量,它保存的是指向字符串数据"junmajinlong"的引用,而不是直接保存该字符串,或者干脆说变量name就是一个指向字符串数据的引用。
严格来说,perl会在堆内存中存放好字符串数据"junmajinlong",然后将该内存空间的地址保存在栈中某个位置,变量name就是这个栈中数据。
如下图所示:
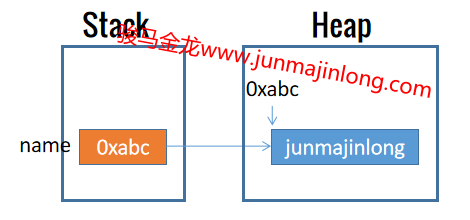
Perl允许原地修改内存数据
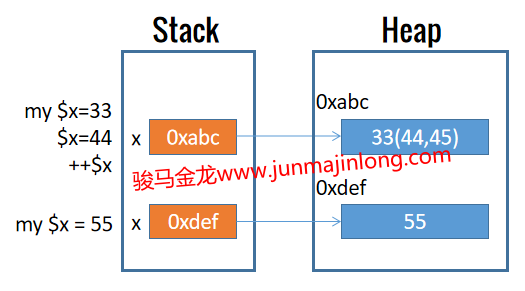
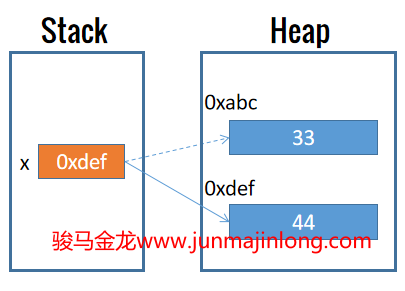
Perl允许原地修改内存数据。这意味着修改变量的数据或为变量重新赋值时,修改后的数据或新数据直接保存在原内存中,变量保存在栈中的引用地址不会发生改变,也即它所指向的内存仍然是原来的内存。
但注意,重新声明同名变量时,会创建新的变量并掩盖(mask)原有的同名变量,它们的内存地址是不一样的。
如图:
在Perl中,可以在某个变量前加上反斜线来获取该变量所保存实际数据的内存地址,例如\$name将获取变量name所保存堆内存数据的地址。
my $name = "junmajinlong";
print \$name; # 输出:SCALAR(0x685bf8)
因此,只要\$x和\$y获取到的地址是相同的,那么就可以说明变量x和变量y指向了同一个内存位置,反之,如果地址不同,则说明它们是不同变量。
因此,也可以用代码验证Perl是否真的是在原地修改内存数据的。
use v5.12;
my $x = 33;
say "x: $x, ", "addr: ", \$x;
# 为变量重新赋值,变量指向的内存地址不变
$x = 44;
say "x: $x, ", "addr: ", \$x;
# 修改变量数据,变量指向的内存地址不变
++$x;
say "x: $x, ", "addr: ", \$x;
# 但重新声明同名变量,原有变量将被掩盖,新变量指向新内存地址
my $x = 55;
say "x: $x, ", "addr: ", \$x;
输出结果:
x: 33, addr: SCALAR(0x6a05c0)
x: 44, addr: SCALAR(0x6a05c0)
x: 45, addr: SCALAR(0x6a05c0)
x: 55, addr: SCALAR(0x6a0bd8)
注意,其他有些语言,不允许原地修改数据,这意味着修改变量数据时,会申请一个新的内存空间来存放修改后的数据,然后让变量指向新的内存空间。这种方式会让变量所保存的地址发生改变。如图:
理解Perl的变量前缀:Sigil
熟悉Shell的人,肯定知道变量赋值和使用变量的方式。例如,对于bash来说:
# 变量赋值
blog_url="www.junmajinlong.com"
# 访问变量:变量替换,将变量的值替换到命令行上
echo $blog_url # 输出www.junmajinlong.com
# 修改变量(变量扩展)并访问修改后的值
echo ${blog_url#*.} # 输出junmajinlong.com
对于bash来说,上面的变量名为blog_url,在变量前加上$符号,表示访问该变量的值。
Perl和Shell非常相似,理解了上面Shell的变量使用方式,也就理解了Perl的变量使用方式。
下面的Perl代码声明了name变量并为其赋值,然后在print中使用了该变量:
my $name = "junmajinlong";
print "$name\n";
需要注意的是,尽管声明变量的时候加上了$前缀,但变量名为name,而不是$name。$前缀表示去访问变量对应的内存地址。
Perl在做变量赋值时、在使用变量时,都会在变量前加上变量前缀。对于标量标量,它的前缀是$符号,对于数组变量,它的前缀是@符号,对于hash变量,它的前缀是%。这些特殊的前缀,在Perl中称为Sigil。
Sigil前缀隐含了多种含义,其中之二是:
- (1).根据变量所保存的内存地址去访问该地址所指向的内存空间
- (2).根据Sigil类型决定如何划分以及如何访问内存空间:
$前缀表示标量,只划分或只访问一个内存数据空间(chunk)@前缀表示数组,划分或访问多个内存数据空间%前缀表示hash,划分或访问多个用于存放key-value的内存数据空间
下面将详细介绍Sigil的这两种含义,更多的含义要在以后遇到了再做解释。
对于含义(1):根据变量所保存的内存地址去访问该地址所指向的内存空间。
也就是说,Sigil前缀的作用类似于导航的功能,根据变量名导航到该变量对应的内存空间处。至于导航到那里之后,是读取内存数据还是向该内存写入数据,由上下文决定。
例如,print "$name";语句中使用了$name,perl将根据变量name在栈中所保存的地址找到对应的内存空间。由于该语句中的"$name"是print参数的一部分,因此perl会将该内存地址处的数据"junmajinlong"读取出来并进行变量内插。
当带有Sigil前缀的变量放在赋值操作符=的左边时,表示将数据保存到该变量所指向的内存中。例如$name = "junmajinlong",perl解析该语句时,发现$name出现在左边,perl就知道这是为变量name赋值,perl会找到name变量并将字符串数据放进变量name所指向的内存空间处。如果找不到name变量,则声明name变量并为其初始化赋值为undef。
也就是说,变量初始化之后就在它的栈中保存了一个指向堆内存中某块空间的地址,由于Perl允许原地修改内存,因此栈中的这个地址在perl程序运行期间将永不改变。
use v5.12;
my $x;
say "addr x: ", \$x;
$x = "hello";
say "addr x: ", \$x;
$x = 33;
say "addr x: ", \$x;
# 输出结果:
# addr x: SCALAR(0x26169b8)
# addr x: SCALAR(0x26169b8)
# addr x: SCALAR(0x26169b8)
此处需要注意,虽然重新声明同名变量会掩盖已有变量使之不可用,但原有变量并未失效,它仍然指向某个堆内存地址,并将持续到程序退出。
对于含义(2):根据Sigil类型决定如何划分以及如何访问内存空间。
例如,当perl发现赋值操作符左边的是$name,由于前缀$表示标量,perl就知道要为变量name划分一个内存数据空间用来保存单个标量数据。因此,$前缀的意思是:要访问或要保存单份数据,而不是多份数据。
当perl发现赋值操作符左边的是@names,由于前缀@表示数组,perl就知道要为变量names划分多个内存数据空间,至于具体要划分多少个内存数据空间,perl将自己决定。@前缀的意思是:要访问或者要保存多份数据,而不是单独的一份标量数据。
%前缀的意思是:要访问或者要保存多份key/value键值对数据,而不是单独的一份标量数据,也不是多份没有键值对映射关系的数据。
如果理解了以上结论,那么就很容易理解下面这两个Perl中令人感觉别扭的用法:
- 访问数组、hash的某个元素时,使用
$前缀,而不是@或%前缀,这是因为访问单个元素时,是要访问单个内存数据空间 - 要进行切片时,使用的是@前缀,因为访问多个元素时,是要访问多个内存数据空间
my @arr = (11, 22, 33);
my %person = (name => "junmajinlong", age => 23,);
# 访问数组单个元素
say $arr[1];
# 访问hash单个元素的值
say $person{name};
# 数组切片,保存到数组slice_arr中
my @slice_arr = @arr[0, 2];
say "@slice_arr";
# hash切片,保存到数组slice_hash中
my @slice_hash = @person{"name", "age"};
say "@slice_hash";
关于数组、hash和切片,后面的文章将会详细介绍。
理解标量的内部类型
Perl区分三种类型的变量:标量、数组和hash。对于标量来说,它表示单个数据,站在内存的角度来看,它意味着单个内存数据空间(chunk)。
实际上,Perl的标量类型有三种基本类型:数值(整数、浮点数)、字符串、引用。虽然它们都是标量,都存放在单个内存chunk中,但perl内部会区分它们的类型,不同的标量类型,存储到内存chunk中的方式不一样,同样的,读取它们的方式也不一样。
例如,引用是一串代表内存地址的数值,假如以十六进制来表示。那么,对于十六进制数值0x123abc,显然它是标量类型,它可以看作一个内存地址,也可以看作一个十六进制数值,但perl如何知道这个是普通数值还是内存地址呢?其实,perl在存储这个标量数据的时候,就会根据其所属类型,以不同方式去存储。
初步理解Perl的引用
由于可以通过$前缀加变量名取得变量所指向的堆内存数据,而变量本身是一个引用,因此,可以换一个角度来思考,只要获取到一个堆数据的引用并将其保存到变量中,就可以在这个变量前面加上$前缀来取得它所指向的堆内存数据。
在Perl中,获取变量的引用的方式是在字面量数据前或变量前加上反斜线(如\42 \$x)。例如\$name得到变量name所保存堆数据的引用。
# 变量name是一个引用,指向堆数据"junmajinlong"
# 即:(name)0xabc -> "junmajinlong"
my $name = "junmajinlong";
# 获取堆数据的引用,即它的地址,将地址保存到另一个变量中
my $name_ref = \$name;
现在变量name_ref保存的实际数据是指向"junmajinlong"的地址。
注意,变量name_ref本身是一个标量变量,而每个变量都是一个引用,它在栈中保存一个指向实际数据的地址。因此,既然name_ref保存的实际数据是指向"junmajinlong"的地址,那么name_ref变量在栈中保存的是一个指向该地址的地址。即:
(name_ref)0xdef -> 0xabc
0xabc -> "junmajinlong"
看图更容易理解:
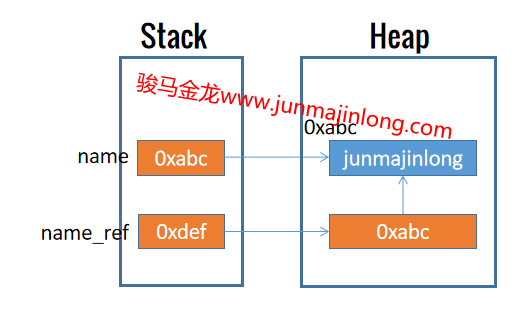
因此,$name_ref等价于变量name,它们都是指向堆中字符串数据的地址。
既然可以使用$name获取堆中字符串数据,当然也可以使用$$name_ref获取这份堆中字符串数据。或者换个写法会更清晰:${name}和${$name_ref}是等价的,因为name和$name_ref是等价的。
my $name = "junmajinlong";
my $name_ref = \$name;
print "$name\n"; # ${name}
print "$$name_ref\n"; # ${$name_ref}
输出:
junmajinlong
junmajinlong
Perl按值拷贝还是按引用拷贝?
先给结论:
- b变量赋值给a变量时,按值拷贝
- 函数(或子程序)调用时,参数传递的规则要复杂一些,这部分传值规则要留在子程序章节再详述
对于变量赋值时按值拷贝其实很容易理解。对于如下赋值代码:
my $b = "junmajinlong";
my $a = $b;
将$b赋值给$a时,根据Sigil的规则,出现在赋值操作符左边的$a表示写内存,出现在赋值操作符右边的$b表示读内存数据。也就是说,读取$b保存在堆内存中的数据,并将其写入$a对应的内存空间。因此,内存中将存在两份值相同但地址不同的数据。
可查看它们的地址:
use v5.12;
my $b = "junmajinlong";
my $a = $b;
say \$a;
say \$b;
输出:
SCALAR(0x2550130)
SCALAR(0x25503d0)
理解Perl的赋值:左值lvalue
当Sigil出现在赋值操作符左边时,表示对变量进行赋值。例如:
my $name = "junmajinlong";
这个赋值过程实际上是找到name变量的内存地址,然后将字符串数据写入该内存。
但是,Perl并不仅仅只允许为变量赋值,还可以为数组的元素赋值,为hash的元素赋值,甚至还可以为某些函数调用后的返回结果进行赋值。
# 变量赋值
my $name = "junmajinlong";
# 为数组元素赋值
my @arr;
$arr[0] = "junmajinlong";
# 为hash元素赋值
my %person;
$person{name} = "junmajinlong";
# 对某些函数调用的返回结果赋值
my $name = 'jun';
substr($name, 3) = 'ma';
实际上,所有可以进行赋值的目标都出现在赋值操作符的左边,它们有一个更为通用的称呼:左值(lvalue)。
与左值对应的概念是右值。左值和右值并非是Perl独有的概念,而是编程领域中的通用概念:左值用来向内存中保存数据,右值用来从内存读取数据(即从内存返回数据)。
当我们说某个东西是左值或表现为左值的时候,就代表可以通过它写入数据从而将数据保存到内存中。
例如,Perl中的变量是一种左值,Perl的substr函数也可以表现为左值,Perl中赋值操作的返回值也可以作为左值。
(my $name = "junmajinlong") =~ s/j/J/;
say "$name"; # 输出:Junmajinlong
数值字面量
数值字面量
Perl中的数值有三种保存方式:整数方式、双精度浮点数方式和十进制字符串方式。
并且,Perl允许如下几种方式的数值字面量:
- 允许使用下划线作为分隔符(主要用作千分位分隔符)
- 允许定义二进制(前缀0b)、八进制(前缀0)、十六进制整数(前缀0x)
- 允许使用指数形式定义数值
- 允许定义为字符串格式的数值,这一点需要特别注意,因为其他语言几乎都不认为字符串格式的数值是数值类型
- 允许有任意前缀空白
- 不考虑前缀空白和前缀负号,从第一个数字开始到第一个非数字字符,中间的部分被当作该字符串的数值,但如果有非数字字符,在开启了warnings时将给出警告
$n = 1234; # 十进制整数
$n = 34_123_456;
$n = 33_22_56;
$n = 0b1110011; # 二进制整数
$n = 01234; # 八进制整数
$n = 0x1234; # 十六进制整数
$n = 12.34e-56; # 指数定义方式
$n = "-12.34e56"; # 字符串方式定义的数值
$n = "1234"; # 字符串方式定义的数值
$n = " 1234"; # 有前缀空白的字符串数值
$n = " 123a"; # 可以当数值123使用,但warnings时会警告
有必要多提一句,Perl可以将字符串格式的数值当作数值来使用,是perl在内部做了很多工作之后的成果。字符串格式的数值仍然是按照字符串方式存储的(因为它本身就是字符串),但在需要将它当作数值使用时,perl会将它转换为合理的数值并将转换后的数值在该字符串的内存中缓存下来,下次再需要使用它的数值格式时,直接从缓存字段中取出数值来。也就是说,转换之后,在内存中同时保存了这份字符串数据以及它的数值格式。
算数运算和类型转换
数值支持多种算术运算方式,其中几种如下:
+ - * / % 加、减、乘、除、取模
++ -- 自增、自减
- 加负号
** 幂运算
abs 取绝对值
对于这些算术操作,有以下几点需要注意:
-
perl会尝试将它们的运算结果转换为整数,但如果运算结果会丢失精度,结果将转换为浮点数以避免丢失精度
5 / 2.5 # 结果为2,而不是浮点数的2.0 -
+ - * / % < > <= >= == != -(负号) ++ -- abs,会尝试将操作数转换为整数"33" + 1 # 结果为34,因为字符串数值也是数值 -
**做幂运算时,运算顺序是从右向左,并且会强制将其右边的数转换为浮点数后进行运算2 ** 3 ** 2 # 结果是512而不是64,等价于2 ** (3 ** 2) -
++ --,不仅会对整数值进行自增自减,还可以对浮点数进行自增自减,但不能直接对数值字面量进行运算,它们只能对变量(左值)进行操作。另外,++还可以对由[a-zA-Z0-9]组成的字符串进行自增,但--没有该功能my $x = 1.2; ++$x; # 2.2,会尝试转换为整数, # 但会丢失精度,因此保留浮点数 # 对字符或字符串自增,但不能自减 my $str = "abc"; ++$str; # abd
判断变量是否是数值
由于Perl的变量只区分标量、数组、hash三种类型,其中数值、字符串等都属于标量,而Perl没有内置的用于检测变量是否是数值的方案。
但有时候确实需要判断一个变量是否是数值,此时可以通过算术运算时的隐式类型转换判断,也可以通过Regexp::Common正则库来判断。
例如,下面是通过隐式类型转换的方式进行的简单判断:
my $a; # undef
my $b = ""; # 空字符串
my $c = 33; # 数值
my $d = "33"; # 字符串数值
my $e = "3a"; # 字符串
if($a + 0 ne $a){ say "a not numeric"; }
if($b + 0 ne $b){ say "b not numeric"; }
if($c + 0 ne $c){ say "c not numeric"; }
if($d + 0 ne $d){ say "d not numeric"; }
if($e + 0 ne $e){ say "e not numeric"; }
将输出:
a not numeric
b not numeric
e not numeric
有时候,undef和空字符串也可以当作数值0来使用,如果把它们也当作数值来看待,则加上条件:
if($a + 0 ne $a && $a + 0 != 0){ say "a not numeric"; }
if($b + 0 ne $b && $b + 0 != 0){ say "b not numeric"; }
if($c + 0 ne $c && $c + 0 != 0){ say "c not numeric"; }
if($d + 0 ne $d && $d + 0 != 0){ say "d not numeric"; }
if($e + 0 ne $e && $e + 0 != 0){ say "e not numeric"; }
将输出:
e not numeric
字符串字面量
字符串字面量
Perl中的字符串和Shell类似,可以使用双引号或单引号包围。它们的区别是:
- 双引号:双引号包围的是字符串字面量,但允许在双引号内使用变量内插(Interpolate)、表达式内插、反斜线转义、反斜线字符序列
- 单引号:单引号包围的字符串字面量不允许使用变量内插、表达式内插、反斜线序列,也禁止几乎所有的反斜线转义,只允许对单引号自身和反斜线自身进行反斜线转义
例如,下面是一些字符串字面量:
use v5.12;
use warnings;
my $name = "junma";
my $age = 23;
say "hello"; # hello,普通字符串
say 'hello'; # hello,普通字符串
# 双引号内可以使用反斜线转义,可以使用单引号
# 单引号内只能转义单引号和反斜线,可以使用双引号
say "hello\"world, hello'world"; # hello"world, hello'world
say 'hello\'world, hello"world'; # hello'world, hello"world
say "hello\\world"; # hello\world
say 'hello\\world'; # hello\world
# 双引号内可以变量内插,单引号内不能变量内插
say "hello $name"; # hello junma
say 'hello $name'; # hello $name
# 双引号内可以表达式内插,单引号内不能表达式内插
say "age: @{[$age+2]}"; # age: 25
say 'age: @{[$age+2]}'; # age: @{[$age+2]}
# 双引号内转义变量内插、转义表达式内插
say "hello \$name"; # hello $name
say "age: \@{[$age+2]}"; # age: @{[23+2]}
# 双引号内可以使用反斜线字符序列,单引号内不允许使用
say "hello\tworld"; # hello_TAB_world
say 'hello\tworld'; # hello\tworld
变量内插不仅可以内插标量标量,还可以内插数组变量,但不能内插hash变量。
my @arr = (11, 22, 33);
say "@arr"; # 输出:11 22 33
my %person = (name=>"junma", age=>23);
say "%person"; # 输出:%person,hash变量不内插
反斜线字符序列
Perl除了支持换行符\n、制表符\t等ASCII的特殊字符外,还支持几个具有特殊意义的反斜线序列。
\u 修改下一个字符为大写
\l 修改下一个字符小写
\U 修改后面所有字符大写
\L 修改后面所有字符小写
\Q 使后面的所有字符都成为字面符号
\E 结束\U \L或\Q的效果
例如:
print "\uabc"; # 输出Abc
print "\Uabc"; # 输出ABC
print "ab\Ucxyz"; # 输出abCXYZ
print "ab\Ucx\Eyz"; # 输出abCXyz
这些反斜线序列有时候非常实用,特别是在使用函数修改数据不方便时。例如,在正则的s替换语法s///中,replacement部分可以使用这些反斜线字符序列。
# 将匹配的字符换成大写
my $name = "junmajinlong";
$name =~ s/([j-n])/\U\1\E/g;
say $name; # 输出:JuNMaJiNLoNg
使用q()和qq()替代单双引号
如果一个字符串比较复杂,使用单双引号包围字符串可能会非常麻烦。
Perl中可以使用q实现单引号相同的引用功能,使用qq实现双引号相同的引用功能。
例如:
q(abc) # 等价于'abc'
qq(abc) # 等价于"abc"
qq(hello"world) # 等价于"hello\"world"
注意上面q()和qq()的括号,它们是引用的起始符和终止符,它们可以被替换为其他成对的符号:要么是前后相同的单个标点字符,要么是对称的括号(大括号、小括号、尖括号、中括号都可以)。
say q!abc!;
say q<abc>;
say qq{abc};
甚至,还可以使用数值、字母作为起始符和终止符,但要求将起始符和q或qq使用空白分隔开。
say qq 1def1; # 等价于qq(def)
say qq adefa; # 等价于qq(def)
注意,如果字符串中出现了起始符或终止符,则需要对其反斜线转义。
say qq{abc\}def}; # 转义终止符
say qq{abc\{def}; # 转义起始符
say qq ad\aefa; # 转义起始符a,输出daef
但是,在起始符和终止符之间,可以嵌套成对的起始符号和终止符号。
say qq{ab{cd}e}; # ab{cd}e
bareword
虽然觉得很诡异,但不用任何引号包围的字符也被Perl当作字符串,这种字符串称为Bareword(裸字符串)。如果开启了warnings功能,使用Bareword时,perl会警告。
$s = abc; ## bareword字符串abc
say $s; # abc
注意,不要直接在say/print/printf的第一个参数处使用bareword,因为第一个bareword会被它们当作输出文件句柄。
# 将bareword字符串hello写入标准输出
# 这里的STDOUT也是bareword,但会被say解析为输出文件句柄
say STDOUT hello;
不建议使用bareword。
v-str
Perl还支持一种称为v字符串的字面量,v字符串多用来表示版本号。例如use v5.12。
v字符串有时候也能用在其他方面,例如保存点分十进制的IP地址,这里不深究v字符串,除了用在版本号上,多数时候也用不到它。
here doc
所谓heredoc,即表示此处内容是文档,即将文档内容当作字符串来处理。
既然是文档,就需要有文档起始符和文档结束符,分别标识文档从哪里起始,到哪里结束。一般来说,所有支持heredoc的语言,文档起始符和文档结束符必须相同(一般使用EOF或eof作为起始符和结束符),且结束符必须单独占行且顶格书写。
Perl中支持的heredoc格式如下,以print为例:
print <<EOF;
line1
line2
line3
EOF
# 输出结果:
# line1
# line2
# line3
这里以EOF作为文档起始符和结束符,起始符EOF后面加上分号结尾表示print语句结束。结束符EOF单独占用一行,且顶格书写。起始符和结束符中间是怎样的数据,输出时就是怎样的数据。
只要需要字符串的地方,都可以使用heredoc来表示这部分字符串。例如,将heredoc字符串赋值给变量、作为函数字符串实参,等等。
# heredoc作为字符串赋值给变量
$msg = <<EOF;
HELLO
WORLD
EOF
print $msg;
还可以为heredoc的起始符加上单引号、双引号以及反引号。它们的效果和普通的单、双、反引号的效果一样:
- 单引号内只允许
\\ \'这两种转义 - 双引号内允许变量内插、表达式内插、反斜线转义、反斜线字符序列
- 加反引号
` `,表示将字符串放进Shell环境执行(和Shell的命令替换效果差不多) - 不加引号等价于加双引号,加反斜线前缀
\EOF等价于加单引号
加单双引号:
$name="malongshuai";
print <<'EOF';
haha
\$name # 反斜线转义功能失效
$name # 变量无法替换
EOF
print <<"EOF";
haha
\$name # 反斜线成功转义
$name # 变量成功替换
EOF
加反引号:
print <<`EOF`;
date +"%F %T"
EOF
另外,从Perl v5.26开始,可以在heredoc的起始符EOF或被引用的EOF前加上波浪号:
<<~EOF <<~"EOF"<<~'EOF' <<~\EOF<<~`EOF`
加上前缀波浪号,使得heredoc允许终止符被缩进,且会将起始符和终止符之间的heredoc内容的空白前缀进行修剪,使之与终止符的缩进进行对齐。看示例理解。
print <<~EOF;
line1
line2
line3
EOF
print <<~\eof;
LINE1
LINE2
LINE3
eof
输出:
line1
line2
line3
LINE1
LINE2
LINE3
使用波浪号前缀时,要求heredoc的内容必须不能出现在终止符之前,否则报错。例如下面代码会报错。
print <<~\eof;
LINE1
LINE2
LINE3
eof
可以同时在一个语句中使用多个heredoc,它们互不影响。例如:
print <<~EOF, <<~\eof;
line1
line2
line3
EOF
LINE1
LINE2
LINE3
eof
输出:
line1
line2
line3
LINE1
LINE2
LINE3
由于heredoc的内容带有尾部换行符,如果想去掉这个尾部换行符,可:
chomp(my $str = <<STR);
line1
line2
STR
print $str;
字符串串联和重复
Perl使用点.来串联字符串。
例如:
my $name = "junmajinlong";
say "www.".$name.".com"; # 输出:www.junmajinlong.com
Perl使用x(字母xyz的x)来重复字符串指定次数:
say '-' x 5; # 重复5次,输出:-----
需注意,如果x重复次数是小数,则截断为整数,如果x是0,则清空字符串。
say '-' x 5.6; # 输出-----
say '-' x 0; # 输出空字符串
数值和字符串的类型自动转换
在前一面介绍数值字面量的小节中曾提到过,当使用运算符+ - * / % -(负号) ++ -- abs以及< <= > >= == !=时,都会将操作数强制转换为数值。
对于字符串来说,当使用.串联字符串或使用x来重复字符串时,会将操作对象强制转换为字符串。
# 字符串转换为数值
"0333" + 22 # 返回355
"12abc" * 3 # 36
"abc12" * 4 # 0
" 12abc" * 3 # 36
# 数值转换为字符串
"033".22 # 返回03322
033.22 # 返回2722,033表示8进制,转换为十进制为27(3*8+3)
注意,当字符串操作符和数值操作符混用时,注意它们的优先级。如果不确定优先级,使用括号强制改变优先级:
"abc".5*3 # 返回abc15,乘法先运算
"abc".5 + 3 # 返回3,"."先运算
"abc".(5+3) # 返回abc8
数值和字符串常用操作函数
数值和字符串常见操作函数
数值类的常用函数比较少,包括:
- int():截断为整数
- rand():返回指定范围内的随机数,不指定范围,则返回
[0,1)之间的随机数
例如:
say int(3.78); # 3
say rand(); # 返回0到1之间的随机数:0.25324216212994
say rand(1.5); # 返回0到1.5之间的随机数:1.21238530987939
say rand(10); # 返回0到10之间的随机数:9.61505077404098
# 要获取随机整数,加上int()
say int(rand(10)); # 返回0到10之间的随机整数:8
字符串类的常用函数较多,包括但不限于如下所列函数:
# 大小写转换类函数
lc:(lower case)将后面的字母转换为小写,是\L的实现
uc:(uppercase)将后面的字母转换为大写,是\U的实现
fc:(foldcase)和lc基本等价,但fc可以处理UTF-8类的字母
lcfirst:将后面第一个字母转换为小写,是\l的实现
ucfirst:将后面第一个字母转换为大写,是\u的实现
# 进制、编码转换类函数
chr:ASCII码(或unicode码点)转换为对应字符
ord:字符转换为ASCII码(或unicode码点)
hex:十六进制字符串转换为十进制数值
oct:八进制字符串转换为十进制数值
# 字符串处理类函数
chomp:去除行尾换行符
chop:去除行尾字符
substr:从字符串中取子串
split:根据指定分隔符将字符串划分为列表
# 字符索引类函数
index:获取字符所在索引位置
rindex:从后向前搜索,获取字符所在索引位置
# 其他函数
length:字符串字符数
sprintf:返回格式化的字符串(自行查阅perldoc -f sprintf)
crypt:加密字符串(实际上是计算MD5摘要信息)
下面举一些示例简单演示其中一部分函数的用法。
大小写转换和编码、进制转换
字符串大小写转化类函数:
say lc("HELLO"); # hello
say ucfirst("hello"); # Hello
chr和ord:
say chr(65); # A
say ord('A'); # 65
say ord('AB'); # 65
hex:将十六进制字符串转换为十进制数值。注意,如果给定的不是字符串,而是数值本身,则数值转换为十进制后被当作十六进制字符串进行处理。
say hex '0x32'; # 50
# 没有前缀0x,32也当作十六进制字符串
say hex '32'; # 50
# 给定数值作为参数
# 0x32对应数值50,hex将50当作待处理字符串
# 等价于hex '0x50'
say hex 0x32; # 80
oct:进制字符串转换为十进制数值的通用函数。可以处理八进制、十六进制、二进制:
- 当给定字符串以0x或0X开头,等价于hex函数
- 当给定字符串以0b或0B开头,将字符串当作二进制字符串转换为十进制数值
- 当给定字符串以0开头或没有特殊前缀开头,将字符串当作八进制字符串转换为十进制数值
- 当给定的是数值参数而非字符串,则数值转换为十进制后被当作八进制字符串处理
say oct '0x32'; # 50,等价于hex '0x32'
say oct '0b11'; # 3
say oct '050'; # 40
say oct '50'; # 40
say oct 0x32; # 40,0x32转换为十进制50,等价于oct '50'
如果想要将十进制数值转换为指定的进制字符串,使用printf或sprintf:
printf "%#o\n", 420; # 0644
printf "%#b\n", 3; # 0b11
printf "%#x\n", 50; # 0x32
printf "%#B\n", 3; # 0B11
printf "%#X\n", 50; # 0X32
printf "%o\n", 420; # 644
printf "%b\n", 3; # 11
printf "%x\n", 50; # 32
字符串处理函数
chomp:移除尾部换行符,如果尾部没有换行符,则不做任何事。
实际上,chomp移除的是$/变量值对应的字符,该变量表示输入记录分隔符,默认为换行符,因此默认移除字符串尾部换行符。注意:
- chomp不能对字符串字面量进行操作
- chomp可以对左值进行操作
- chomp可以操作列表,表示移除列表每项元素的尾部换行符
- chomp也可以操作hash,表示移除每项value的为尾部换行符
- chomp返回成功移除的总次数
- 对于字符串,如果有换行符,则返回1,否则返回0,因此可通过该返回值判断字符串是否有结尾换行符
- 对于列表,可以通过返回值来判断总共操作了多少行数据
my $name = "junmajinlong\n";
chomp $name; # name变为"junmajinlong"
chomp $name; # name仍然是"junmajinlong"
chomp(my $tmp = "junmajinlong\n"); # 对左值变量进行操作
# chomp操作数组或列表
my @arr = ("junma\n","gaoxiao\n");
chomp @arr; # @arr=("junma","gaoxiao")
# chomp操作hash
my %lines = (
line1 => "abc\n",
line2 => "def\n",
);
chomp %lines;
say "$lines{line1}, $lines{line2}"; # abc def
chop:是chomp的通用版,移除尾部单个字符,等价于s/.$//s,但效率更高。
my $name1 = "junmajinlong\n";
my $name2 = "junmajinlong";
chop $name1; # $name1 = "junmajinlong"
chop $name2; # $name2 = "junmajinlon"
substr:从给定字符串中提取并返回一段子串。用法:
substr STRING,OFFSET,LENGTH,REPLACEMENT
substr STRING,OFFSET,LENGTH
substr STRING,OFFSET
其中:
- offset从0开始计算
- offset为负数时,表示从尾部位移(从-1开始计算)往前位移
- length如果忽略,则从offset处开始取到最尾部
- length为正数时,从offset处开始取length个字符
- length为负数时,length则表示从后往前的位移位置,所以将从offset开始提取,直到尾部保留-length个的字符
- replacement替换string中提取出来的字串。需注意:加了replacement,将返回提取的子串,同时会修改源字符串STRING
$str="love your everything";
say substr $str,5; # 输出:your everything
say substr $str,-10; # 从后往前取:everything
say substr $str,5,4; # 从前往后取4个字符:your
say substr $str,5,-3; # 从位移5取到位移-3(从后往前算):your everyth
say substr $str,5,4,"fairy's"; # 替换源字符串,但返回提取子串:your
say $str; # 源字符串已被替换:love fairy's everything
substr函数可以作为左值,这样可以修改源变量,就像给了replacement参数一样:
$str="love your everything";
substr($str,5,4) = "fairy's";
say $str; # 源字符串已被替换:love fairy's everything
index和rindex:用来找出给定字符串中某个子串或某个字符的索引位置。
(r)index STRING,SUBSTR,POSITION
(r)index STRDING,SUBSTR
- index搜索STRING中第一次出现SUBSTR的位置,rindex则从后向前搜索第一次出现的位置,也就是从前向后最后一次出现的位置
- 如果省略position,则从起始位置(从0开始计算)开始搜索第一次出现的子串
- 给定position,则从position处开始搜索,如果是rindex,则是找position左边的
- 如果STRING中找不到SUBSTR,则返回-1
$str="love you and your everything";
say index $str,"you"; # 输出:5
say index $str,"yours"; # 输出:-1
say index $str,"you",136; # 输出:-1
say index $str,"you",6; # 从offset=6之后搜索,输出:13
say rindex $str,"you"; # 输出:13
say rindex $str,"you",10; # 找出offset=10左边的最后一个you,输出:5
length:返回字符串字符数。不能用于数组和hash。注意,如果包含多字节字符,要加上use utf8才能计算出字符数量。
say length("abc"); # 3
say length("我爱你"); # 9
# 加上use utf8
use utf8;
say length("我爱你啊a"); # 5
crypt:加密字符串,实际上是计算MD5摘要值:第一个参数是待计算摘要的字符串,第二个参数是salt字符串,salt至少两个字符且只取前两个字符(salt允许使用的字符为[0-9a-zA-Z./]共64个字符)。
如果待计算的字符串相同,且salt相同,那么计算出来的摘要信息一定相同。计算的结果中,前两位是salt的前两位字符,后面11位是计算结果。
say crypt("hello", "world"); # woglQSsVNh3SM
say crypt("hello", "wo"); # woglQSsVNh3SM
say crypt("hello", "wx"); # wxNrzGG7p9cyw
和openssl命令计算的md5值是一样的:
$ echo "hello" | openssl passwd -stdin -salt "wo"
woglQSsVNh3SM
split:根据指定分隔符,将字符串划分为列表形式,参考Perl split。
Perl列表、数组和上下文
Perl中最重要的概念之二是列表和上下文,它们都贯穿于整个Perl。实际上,任何一条Perl代码都存在一个或多个上下文,理解上下文是深入理解Perl和编写Perl风格代码的第一步也是至关重要的一步。
本章将先介绍数组的基本使用,然后再解释有关于列表和列表上下文的一些细节,从而加深对Perl的理解。
数组的基本使用
数组的基本使用
数组是包含一系列标量数据的容器,或者说数组由零个、一个或多个标量数据组成,数组在内存中的体现,则是由多个内存数据空间组合在一起。
创建数组时,perl可能要为它划分多个内存chunk,因此数组变量要求使用@前缀。
例如,可通过下面这种方式创建数组,这表示创建一个名为arr的数组变量,它保存了4个数值标量数据。
my @arr = (11, 22, 33, 44); # 只包含数值的数组
Perl数组是动态的,不限制数组的长度(元素个数),可以在任何时候往数组中增加任意多的元素。例如可以使用push函数向数组中追加元素。
my @arr = (); # 声明空数组
push @arr, 11;
push @arr, 22;
say "@arr"; # 别忘了,双引号允许内插数组
# 输出:11 22
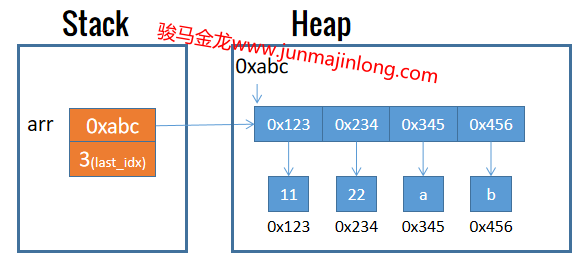
Perl数组也不限制所存放元素的数据类型。例如:
# 数组中同时保存数值、字符串
my @arr = (11,22,'a','b');
实际上,数组中保存的是这些元素的引用,而引用地址是一种标量。例如,上例数组的内存布局大致如下图所示:
qw创建数组
当创建只包含字符串元素的数组时,每个元素都要使用单引号或双引号引用起来,这在书写上比较麻烦。
Perl提供了类似于q和qq的qw字面量表示法,qw的全称是quote words,即自动引用单词。perl会在编译期间将qw所引用的单词自动替换为单引号。
例如,下面的两行赋值语句是等价的。
my @arr1 = ('a', 'b', 'c', 'd');
my @arr2 = qw(a b c d);
注意,qw中使用空格分隔各元素,如果某个元素包含空格,则无法使用qw字面量语法。
另外,上面示例使用的是qw(),其中括号可以替换为其他成对的符号,这一点和q或qq的用法完全一致。
qw()
qw[]
qw!!
qw%%
索引数组
可通过数值下标来索引数组的元素,下标从0开始。注意,索引数组元素时使用前缀$加数组标量名加索引下标值,使用$前缀的原因是要访问数组中这个元素的单个内存chunk。例如:
my @arr = (11,22,33,44);
# 读取index=0位置处也就是第一个元素
say $arr[0];
Perl还支持负数索引,表示从数组尾部开始计算元素的位置。index=-1表示倒数第一个也就是最后一个元素的位置,index=-2表示倒数第二个元素的位置。
my @arr = (11,22,33,44);
say $arr[-1]; # 44
say $arr[-2]; # 33
对数组进行索引时,它也可以作为左值被赋值,这表示将所赋值数据写入该元素对应的内存空间。
my @arr = (11,22,33,44);
# 作为左值被赋值
$arr[1] = 222;
$arr[-1] = 444;
say "@arr"; # 输出:11 222 33 444
数组越界访问时,perl不会报错,而是返回undef。数组通过正数索引越界赋值时,将使用undef填充中间缺失的元素。
my @arr = (11,22,33,44);
say $arr[10]; # 输出空字符串,数组不变
# 数组长度为11,最后一个索引为index=10
# 中间index=4到index=9的元素都被填充为undef
$arr[10] = 9999;
扩展数组
在Perl中,当需要多个数据的时候,都是将多个数据放进列表。
要扩展数组,Perl中的逻辑是将数组放进小括号中,这会将数组转变成列表格式,然后在列表上扩展更多元素。
例如:
my @arr = (11,22,33);
@arr = (@arr, 44, 55); # 扩展数组
say "@arr"; # 11 22 33 44 55
换句话说,当数组放进小括号时,数组会被压平后放进小括号。
my @arr = (11,22,33);
# 数组先展开,得到(11,22,33),然后赋值给@arr1
my @arr1 = (@arr);
数组长度
数组长度表示数组当前存储了多少个元素。Perl并未像其他语言一样提供相关函数来获取数组长度,Perl获取数组长度的方式是将数组放进标量上下文。
标量上下文表示被需求的是一个标量数据。如果这个位置放置的本就是标量数据,则直接使用该数据,如果该位置放置的是数组、hash类型的数据,perl内部会自动将它们转换为标量类型。它们按照如下规则进行转换:
- 数组转换为标量得到的是数组的长度
- hash转换为标量得到的是
M/N格式的字符串,N表示hash的容量,M表示hash当前的键值对数量
除了知道数组、hash转换为标量时的转换规则,更重要的是需要知道何时处于标量上下文,只有在标量上下文,它们才会转换。但Perl有很多种情况会进入标量上下文,Perl并没有一种完整的规则来描述何时处于标量上下文,一切皆凭感觉。但总是可以使用scalar来强制进入标量上下文。
例如:
my @arr = (11,22,33,44);
my %p = (
name => "junmajinlong",
age => 23,
gender => "male",
);
# scalar使其参数强制进入标量上下文
say scalar @arr; # 输出:4
say scalar %p; # 输出:3/8
有时候会使用数组长度作为索引,来向数组尾部追加一个元素:
my @arr = (11,22,33);
$arr[scalar @arr] = 44;
say "@arr"; # 输出:11 22 33 44
数组最大索引
数组最大索引,即数组最后一个元素的索引。
知道数组长度后,就知道了最后一个元素的索引:长度减一。
my @arr = (11, 22, 33, 44);
my $arr_max_idx = scalar @arr - 1; # 3
实际上,Perl为每个数组都保存了最大索引值。甚至,Perl单独为获取数组最大索引提供了一种语法:$#arr。其中#arr表示获取数组最大索引值,因为索引是一个标量数值,所以加上$前缀来访问该标量值。
例如:
my @arr = (11, 22, 33, 44);
say $#arr; # 3
因此,可以通过$arr[$#arr]表示数组最后一个元素数据。通过下面这种方式,可以向数组尾部追加一个元素:
my @arr = (11,22,33);
$arr[++$#arr] = 44;
say "@arr"; # 输出:11 22 33 44
实际上,$#arr的值总是长度减一,例如空数组的$#arr值为负一。
注意,最大索引值和长度会相互影响,修改最大索引值会同步修改数组长度,这会导致数组的扩展或截断。
例如:
my @arr = (11,22,33,44);
$#arr = 10; # 将修改长度为11,缺失元素使用undef填充
$#arr = 2; # 将长度修改为3,截断元素44和后面的空元素
字符串内插数组
双引号字符串中可以直接内插数组变量,内插时,默认将各元素使用空格分隔然后替换到内插表达式位置处。
例如:
my @arr = (11, 22, 33);
# 内插后,得到字符串:"arr: 11 22 33"
my $str = "arr: @arr";
实际上,双引号内插数组时,是使用内置变量$"的值作为数组元素分隔符的,该变量默认值为空格:
say qq(x${"}x); # 输出: x x
因此修改$"的值,可以改变数组元素的分隔符。
my @arr = (11, 22, 33, 44);
$" = "-";
say "@arr"; # 11-22-33-44
print/say输出数组
实际上,print、say是能够直接输出数组的。
my @arr = (11, 22, 33);
say @arr; # 输出:112233
当未将数组内插进双引号字符串时,print/say默认会将数组各元素紧密相连,正如上面输出的结果是112233一样。
实际上,print/say的参数处于列表上下文,当未将数组内插至双引号中时,数组各元素被展开,这些元素和print/say中逗号分隔的其他参数一起组成一个新的列表。例如:
my @arr = (11, 22, 33);
# 11 22 33 a b共5个元素共同组成一个列表
say @arr,'a','b';
print/say输出时,默认使用内置变量$,来分隔列表各元素,该内置变量默认值为undef,因此默认情况下各元素被输出时紧密相连。
my @arr = (11, 22, 33);
say @arr,'a','b'; # 112233ab
$, = "_"; # 将其修改为下划线
say @arr,'a','b'; # 11_22_33_a_b
理解列表
理解列表
当使用下面的语法创建数组时:
my @arr = (11,22,33);
实际上,左边的@arr表示arr是一个数组变量,右边括号包围的(11,22,33)是一个列表,整个代码表示将列表中的所有元素保存到数组arr中。
列表还可以使用qw来表示:
my @arr = qw(11,22,33);
也可以直接对列表进行索引取值:
my $a = (11,22,33)[2]; # $a=33
要注意,Perl中的列表不是数据类型,而是Perl在内部用来临时存放数据的一种方式,只能由Perl自行维护。
实际上,列表临时保存在栈中,当使用了列表数据后,这些列表数据就会出栈。根据使用列表的不同使用环境,列表数据可能是被复制到了堆内存中保存起来(比如赋值给数组),也可能是用完直接消失(比如一次性使用的列表)。
区分列表和数组
学习Perl的时候,需要区分列表和数组。如果了解过其他编程语言,可以将Perl列表看作是一种特殊的底层可迭代对象,它看起来像数组,但不是数组。
数组是列表最直观的一种体现形式,是暴露给编程人员的一种数据类型。创建数组时,初始化数组元素很可能来自于列表:
my @arr = (11,22,33); # 数组arr的元素来自于列表
上面的赋值语句,其内部过程大致为:在栈中存储好列表元素,当开始赋值时,perl将栈内列表各元素拷贝到堆内存,并在数组变量arr的各内存中保存这些堆内存数据的引用地址。拷贝完成后,栈中的列表数据全部出栈。
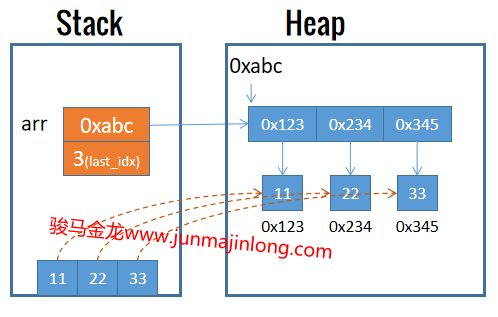
编程人员可以直接操作数组,比如可以将元素push到一个数组,可以pop弹出数组最后一个元素,等等,这些操作无法用于列表。而元素排序、元素筛选、迭代遍历等操作,都可以用于列表。
理解上下文
理解上下文
上下文是Perl中最重要的概念之一,不理解上下文,就谈不上Perl风格的代码和Perl的技巧。
Perl有很多种上下文,但不幸的是没有一种规范去概括描述什么情况下处于什么上下文,学习和使用Perl的时候,需要记住几种常见的上下文环境,剩下的需要自己推理上下文。
最常见也是最重要的两种上下文是标量上下文和列表上下文:
- 标量上下文表示此处需要的是一个标量数据
- 列表上下文表示此处需要的是列表,即可能需要零个、一个或多个数据
常见的标量上下文包括:
- 标量变量作为左值,例如
$arr = xxx,赋值操作符左边的$表明这是一个标量上下文,赋值操作符右边需要提供标量数据 - 加减乘除等算术运算符、大小比较、等值比较、字符串串联、字符串重复,等等,这些操作符要求标量上下文,需要标量数据
- if、while的条件表达式部分,是标量上下文,严格来说是布尔标量上下文,要求布尔值
- 操作数值、操作字符串的环境,需要标量上下文,例如正则匹配、正则替换、abs()取绝对值,等等
常见的列表上下文包括:
- 数组变量作为左值,例如
@arr = xxx,赋值操作符左边的@表明这是一个列表上下文,赋值操作符右边需要提供列表数据 - hash变量作为左值,例如
%p = xxx,其中%表明这是一个列表上下文,赋值操作符右边需要提供列表数据 - print/say的参数,例如
say 11,22,33;,各参数组成一个列表 - for、foreach、each等迭代语句,需要列表上下文
- 用于操作列表的函数,其某个参数需要列表上下文,例如grep、sort、map等列表类函数
当需要列表上下文时,如果提供的是非列表数据,则尽可能地转换为列表数据;同理,当需要标量上下文时,如果提供的是非标量数据,则尽可能地转换为标量数据。
Perl有时候会自动隐式地将数据转换为符合上下文环境的数据,但如果无法进行隐式转换,那么需要显式强制转换。
为列表上下文提供列表数据
提供列表数据的一种方式是使用列表字面量:小括号包围或者qw()都可以。
my @arr = (11,22,33); # 右边的括号是一个列表
my @arr = qw(a b c); # 右边的qw()是一个列表
my ($a, $b, $c) = (11, 22, 33); # 两边的括号都是列表
如果没有使用列表字面量作为列表数据,那么Perl会自动隐式地将所提供的数据转换为列表。转换规则如下:
- 标量转换为列表,并且标量数据作为列表的元素
- 数组各元素直接作为列表各元素,即相当于数组压平后放入列表
- hash的key和value都作为列表元素,但注意,转换时的元素顺序是未知的
例如,print/say函数的参数是一个列表上下文:
my @arr = (11,22,33);
my %person = (name=>"junma", age=>23,gen=>"male");
say 11,22,33; # 各标量转换为列表 [11 22 33]
say @arr; # 数组转换为列表 [11 22 33]
say %person; # hash转换成列表 [name junma age 23 gen male]
# print/say使用标量$,的值作为分隔符输出各列表元素
# 输出结果:
# 112233
# 112233
# genmaleage23namejunma
以上这些转换为列表的方式是隐式的,还可以使用小括号包围它们来显式地、强制地转换为列表。例如:
my @arr = 33; # 隐式转换
my @arr = (33); # 显式转换
my @arr = @arr0; # 隐式转换
my @arr = (@arr0); # 显式转换
my @arr = %p; # 隐式转换
my @arr = (%p); # 显式转换
有些场景下,必须使用小括号显式地转换为列表,否则会产生歧义。例如:
# 改成qw(@arr,44,55)也可以
# 但如果去掉小括号,将报错
foreach $i (@arr,44,55) {
say $i;
}
在这里需要理解一种比较特殊的用法:括号里放空括号或者括号里放空数组,不会产生任何效果。这种现象的原因很容易理解,因为列表上下文中,内部列表或内部数组的元素直接作为外部列表的元素,内部使用空列表或空数组,没有为外部列表提供任何元素。
(()) # 等价于()
((),(),()) # 等价于()
my @arr = ();
(@arr,(),@arr); # 等价于()
my @a = ((),(),()); # 等价于@a = ()
say scalar @a; # 输出:0
为标量上下文提供标量数据
如果在标量上下文处提供的是字符串、数值、引用等本就是标量的数据,则直接使用它们。
如果提供的是数组或者hash,则perl会尝试自动隐式地将它们转换为标量类型。转换规则如下:
- 数组转换为标量得到的是数组的长度
- hash转换为标量得到的是
M/N格式的字符串,N表示hash的容量,M表示hash当前的键值对数量
例如,加法运算要求标量上下文,如果加法操作的两个操作数不是标量,则会隐式转换成标量。
my @arr = (11,22,33,44);
# 下面的加法操作会将操作数@arr转换为标量
# 得到arr数组的长度4
say 1+@arr; # 5,等价于1+4
转换为标量数据是非常常见的需求,如果当前身处非标量上下文,但却需要标量数据,那么可以采取一些简短的技巧改变上下文环境,或者使用scalar显式地、强制地转换为标量。例如:
my @arr = (11,22,33,44);
# 使用加0操作得到标量环境且不影响标量结果
say @arr+0;
# 使用双波浪号 ~~ 转换为标量上下文,
# 单个~是位取反操作,要求标量数据,两次位取反得到原数据的标量形式
say ~~@arr;
# 使用scalar强制转换为标量数据
say scalar @arr;
标量上下文中的列表
上面介绍了在标量上下文中,数组和hash会按照怎样的规则转换成标量数据。但是,标量上下文中,列表如何转换成标量数据呢?
例如:
# 左边表示标量上下文,右边给了列表数据
my $a = (11,22,33);
my $b = qw(11 22 33);
say $a, "-", $b; # 输出:33-33
从输出结果来看,变量a和b的值都是33,它们正好都是列表的最后一个元素。
也就是说,标量上下文中的列表,会返回最后一个列表元素作为标量数据,其他元素被丢弃。
say "h".(1,2,3,4); # 输出:h4
say ~~(11,22,33); # 输出:33
my @arr = (11,22,33);
@arr = @arr + (55,66); # 等价于@arr=3+66
say "@arr"; # 输出69
实际上,当遇到标量上下文中的列表时,会从前向后逐步评估每一个元素,然后丢弃这个元素的评估结果,直到评估完最后一个元素返回它。
# ($a = 3, $b = 4)先为a赋值3,丢弃它,再为b赋值4
# 返回$b,并将$b赋值给c
my $c = ($a = 3, $b = 4);
say "$a-$b-$c"; # 输出:3-4-4
另外,在一些书籍、文档(包括官方手册)上,将标量上下文中的列表解释为逗号操作符的效果,这也可以。这是因为列表总是表现为逗号分隔各元素、必要的时候使用一个小括号包围的形式(qw列表字面量在编译后也会转换成这种小括号形式),而逗号是一个操作符,它的作用是评估左边的表达式,然后丢弃,继续评估右边的表达式,直到评估完最后一个表达式,返回它的结果。
# 右边先丢弃1,再丢弃2,返回3
my $a = (1,2,3);
my $a=3,$b=4;
在这里也有一个比较特殊的用法需要理解:括号里(或列表中)使用连续逗号,不会产生任何效果。
my $a=3,$b=4,,,,; # 等价于$a=3,$b=4
my @a = (1,,,,3,2,,); # 等价于(1,3,2)
((3,,),,); # 等价于((3)),等价于(3)
空上下文
当表达式或语句的返回结果不被使用时,它们就处于空上下文(void context)。换句话说,空上下文会丢弃表达式或语句的结果。
例如,下面几种情况都在空上下文中:
# 直接写字面量、变量、表达式等,
# 这些数据不被使用,直接丢弃而不会报错
333;
"abc";
3+3;
$name;
# 赋值语句的返回结果被丢弃
my $a = 33;
# 函数调用的结果被丢弃
abs(-1);
理解上下文后的一些赋值技巧
将Perl的赋值操作和其他编程语言的赋值操作进行对比,会发现其他语言的赋值操作都规规矩矩的,就是简简单单的赋值语句。
但是Perl的赋值语句非常灵活,灵活到我学习的时候感觉很苦恼,因为初学Perl的时候,这些赋值语句都是像黑科技一样的技巧,没有【规律】可言,也不知道到底还有多少种赋值技巧没有被发现。这些技巧几乎是Perl独有的技巧,不适用于其他语言。这可能是某些人攻击Perl的其中一个理由:Perl太过灵活,而且缺乏规范。
当我对Perl的细节理解逐渐深入后,我才明白,这些技巧都有理可依,且是对语法规则的深入应用。以前不理解这些技巧,只是因为像学其他语言的赋值语句一样,简简单单地学了基本赋值规则。
下面是一些结合上下文后的赋值技巧,我无法总结全部,只能总结一些常见的技巧。
## 1.标量上下文中的列表:得到最后一个元素
## 赋值语句返回标量左值
$a = (11,22); # a=22,赋值语句返回22
$a = $b = (11,22); # a和b都等于22
# 下面func()最后返回空列表,标量上下文的赋值返回0,布尔假
while (($a, $b) = func()){}
# 赋值语句返回的标量左值可被修改
chomp ($str = "hello\n"); # 将会去除$str中的换行符
($a = $b) =~ s/xxx/yyy/; # 将会修改变量a
($a += 2) *= 2; # 将会对a加2后乘2
## 2.列表上下文中的列表:逐个赋值
## 左边多的变量被赋值为undef,右边多的元素被丢弃
## 赋值语句本身的返回值:
## 在标量上下文:返回右边列表的长度
## 在列表上下文:返回左边列表
($a, $b) = (11,22); # 赋值语句返回2或(11,22)
($a) = (11,22); # 赋值语句返回2或(11)
() = (11,22); # 赋值语句返回2或()
($a,$b,$c) = (11,22); # 赋值语句返回2或(11,22,undef)
($a,undef,$c) = (11,22,33); # 赋值语句返回3或(11,undef,33)
$num = () = <>; # 将已读取的行数赋值给num
$num = @arr = <>; # 同上
@arr=($a,$b)=(11,22,33); # @arr=(11,22),$a=11,$b=22
Perl切片
切片(Slice)
Slice指的是从列表、数组、hash中根据指定的索引取一个或多个元素。
在列表上下文,切片返回一个包含所取得元素值的列表。在标量上下文,返回所取得的最后一个元素值。
例如,列表切片:
# 取列表中index=0、1和3的元素,
# 列表上下文中返回所取得元素的列表,赋值给数组
my @arr = (11, 22, 33, 44)[0,1,3]; # 11 22 44
数组切片:
my @arr = (11, 22, 33, 44, 55);
my @arr = @arr[1,2,3] # 22 33 44
切片时中括号里提供的索引是一个列表,索引可以重复,可以用负数索引,可以用范围表达式(如1..3表示1 2 3)。但要注意,索引越界将取得undef值。
(11, 22, 33, 44)[0,1,1,-1]; # 11 22 22 44
(11, 22, 33, 44)[0..2]; # 11 22 33
(11, 22, 33, 44)[0, 2..3]; # 11 33 44
(11, 22, 33, 44)[0, 1, 30]; # 11 22 undef
有时候需要从列表或数组中随机取一个或多个元素,可以将rand()的结果作为切片的索引值:
my @arr = ('a'..'z', 'A'..'Z');
say "@arr[rand 52, rand 52]"; # 取两个随机元素
有时候需要取得数组的最后几个元素值(例如perl一行式命令中经常需要取最后几个字段的值),这时可利用数组的最大索引来转换计算:
my @arr = (11,22,33,44,55,66);
# 取最后一个元素
my @arr[$#arr]; # 或:@arr[-1]
# 取最后四个元素
my @arr[$#arr-3..$#arr];
数组切片和列表切片在使用上有一些区别:
- 数组切片可以内插到双引号中,而列表切片不能内插到双引号
- 数组切片可以作为左值,列表切片则不行
例如:
# 内插数组切片
my @arr = (11,22,33,44);
say "@arr[0,1,1]";
# 数组切片作为左值
my @langs = qw(perl python shell php);
@langs[1,2]=qw(ruby bash); # 将python改为ruby,shell改为bash
say "@langs"; # perl ruby bash php
遍历列表和数组,默认变量$_
遍历列表和数组,默认变量$_
对于数组来说,可以使用while循环或for循环的方式来遍历所有元素:
my @arr = qw(a b c d e f);
# while
my $i = 0;
while($i <= $#arr){
say "index: $i, value: $arr[$i]";
$i++;
}
# for
for(my $i=0;$i<=$#arr;$i++){
say "index: $i, value: $arr[$i]";
}
上面的while和for循环利用的是数组的最大索引$#arr,使用数组的长度作为条件也一样。
一般来说,使用迭代的方式来遍历数组或遍历列表会更方便。Perl中可以使用for或foreach进行迭代,foreach是for的语法糖,foreach能做的,for都能做。
for或foreach的迭代数组或列表的方式如下。
my @arr = qw(a b c d e f);
# for
for my $v (@arr) {
say "value: $v";
}
# foreach
foreach my $v (@arr) {
say "value: $v";
}
for或foreach迭代时,会从列表中逐个取元素,取一个元素,赋值给迭代控制变量$v,然后执行一次循环体,再继续取下一个元素。
注意,迭代每个列表元素时,元素是按引用传递给控制变量的,控制变量在栈中保存了元素的内存地址,每次迭代时控制变量的地址都发生改变。因此可以推断,每次迭代时,Perl都会重新声明控制变量,每次声明的控制变量仅在本次迭代过程中有效。
my @arr = (11, 22, 33, 44);
my $v = 3333;
say \$v;
say '---- before ----';
for my $v (@arr) { say \$v; }
say '---- after ----';
say \$v;
say "$v";
# 输出:
# SCALAR(0x22f3d10)
# ---- before ----
# SCALAR(0x2277ab0)
# SCALAR(0x2277a98)
# SCALAR(0x2277b40)
# SCALAR(0x2277b58)
# ---- after ----
# SCALAR(0x22f3d10)
# 3333
因此,for或foreach迭代时,赋值过程大致如下图:
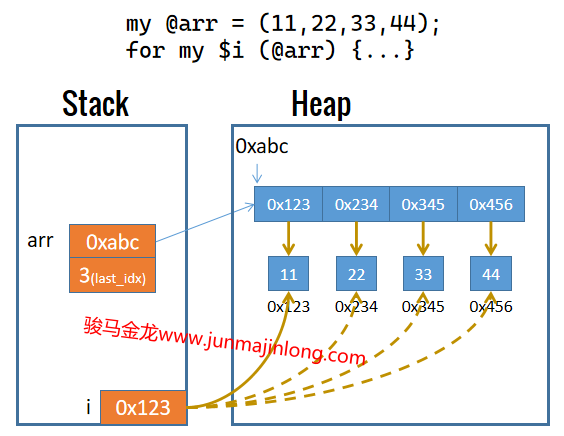
因此,如果在循环体内修改控制变量,也将直接修改列表中该元素的值。
my @arr = (11, 22, 33, 44);
for my $v (@arr) {
$v++;
}
say "@arr"; # 输出:12 23 34 45
在使用for/foreach迭代数组时要注意,修改数组大小会影响迭代。
my @arr = (11,22,33,44,55,66);
for my $i (@arr){
shift @arr;
say $i; # 11 33 55
}
默认标量变量$_
for和foreach迭代时需指定控制变量,例如for $i (...)。
控制变量是可以省略的,此时将使用Perl的默认标量变量$_。
下面两条for迭代语句完全等价:
for(11,22,33){ say $_; }
for $_ (11,22,33) { say $_; }
Perl的很多操作都允许省略操作目标,此时将使用默认变量$_作为这些操作的操作目标。以后在使用Perl的过程中,自然会发现这一点。
例如,chomp函数用来去除字符串变量尾部的换行符,它可以省略操作目标,此时将操作$_变量。因此,下面两条语句是等价的。
chomp;
chomp $_;
print/say也可以省略参数,这时表示输出$_的值。下面等价:
print;
print $_;
小心使用each
使用while循环或for循环遍历列表时可以获得各元素的索引,但使用for迭代或foreach迭代列表各元素时,无法获取迭代时元素的索引。
Perl提供了一个名为each的函数,它可用于迭代数组和hash。在列表上下文,each会返回数组的(index, value)或hash的(key, value),在标量上下文,each会返回当前所处的index或key。
将while结合each一起使用,会非常方便。例如:
my @arr = (11,22,33,44);
# 列表上下文,each返回(index, value)
while(my ($idx, $v) = each @arr) {
say "index: $idx, value: $v";
}
也可以单独使用for迭代,然后在循环体中使用each获取索引:
my @arr = (11,22,33,44);
for my $v (@arr){
# 标量上下文,each返回index
say "index: ".(each @arr).", value: $v";
}
但是,each是有问题的:each @arr取完最后一个元素后,不会重置迭代指针,下次再执行each @arr,在列表上下文将返回空列表,在标量上下文将返回undef,再之后才继续从索引0、1、2开始。
each取完最后一个元素后返回空列表或undef,其好处是可以直接在while循环中表示布尔假,使得取完所有元素后终止while循环。但如果不是each取完最后一个元素触发while循环的终止,那么任何使用each的地方都将出现不符合期待的结果。
例如,下面使用while+each两次循环遍历数组arr,并在第一个while中使用last提前退出while循环。
my @arr = (11,22,33,44);
while(my ($idx, $v) = each @arr) {
say "index: $idx, value: $v";
last if $idx == 2;
}
while(my ($idx, $v) = each @arr) {
say "index: $idx, value: $v";
}
输出结果:
index: 0, value: 11
index: 1, value: 22
index: 2, value: 33
index: 3, value: 44
再比如,下面的两次for迭代,都在循环体中使用each取索引,将出现问题:
my @arr = (11,22,33,44);
for my $v (@arr){
say "index: ".(each @arr).", value: $v";
}
for my $v (@arr){
say "index: ".(each @arr).", value: $v";
}
输出结果:
index: 0, value: 11
index: 1, value: 22
index: 2, value: 33
index: 3, value: 44
index: , value: 11
index: 0, value: 22
index: 1, value: 33
index: 2, value: 44
因此,each唯一安全的使用方式是:while + each,但while循环内不能改变while的循环流程且不能使用keys、values重置迭代指针。例如,while…each内最好不要使用last、next等。
事实上,Perl官方手册(perldoc -f each)建议尽量使用foreach迭代取代while each。
操作数组
操作数组
在Perl中,数组、列表应用非常广泛,也经常需要对数组和列表进行一些操作。
列表常见操作包括:grep、join、map、reverse、sort、unpack、x操作符执行列表重复,等等。另外,标准库List::Utils中也提供了很多常见的列表操作,如reduce、first、any、sum、uniq、shuffle等。
多数时候,数组可以当作列表来使用,原因是操作列表的地方期待一个列表,即处在列表上下文,perl会隐式地将数组转换为列表。因此上述列表操作多数也适用于数组。
但数组是Perl的内置数据结构,是直接暴露给编程人员的数据类型,它可以转换为列表,但它不是为了转换成列表而存在的,它有自己的角色,有一些操作只能应用于数组而不能应用于列表。
数组常见的操作包括:each、pop、push、shift、unshift、keys、values、splice。
本节将介绍数组的常见操作,列表相关操作将留给后文。
keys、values
-
keys函数在列表上下文返回数组的所有索引或hash的所有key,在标量上下文返回数组或hash的元素数量
-
values函数在列表上下文返回数组的所有元素或hash的所有value,在标量上下文返回数组或hash的元素数量
以数组为例:
my @arr = (11, 22, 33, 44);
# 列表上下文
my @arr_keys = keys @arr;
my @arr_values = values @arr;
say "@arr_keys"; # 0 1 2 3
say "@arr_values"; # 11 22 33 44
可以通过keys或values函数来迭代数组、hash的索引或值。以数组为例:
my @arr = (11, 22, 33, 44);
for(keys @arr){say $_;} # 0 1 2 3
for(values @arr){ say $_; } # 11 22 33 44
每次调用keys和values都会重置Perl内部维护的迭代指针,因此使用keys或values来迭代数组、hash是安全的,它们总能取得数组或hash的所有元素。
另外,values获取的值是对元素的引用,因此修改values获取的值,也将修改源数据。
my @arr = (11, 22, 33, 44);
my @arr_values = values @arr;
$arr_values[0] = 111;
say "@arr_values"; # 111 22 33 44
pop push shift unshift
- pop从数组中移除并返回最后一个元素,数组为空则返回undef
- push向数组尾部追加一个元素或一个列表,返回追加完成后数组长度
- shift移除并返回数组第一个元素,数组为空则返回undef
- unshift向数组头部添加一个元素或一个列表,返回追加完成后数组长度
对于pop、shift:
# pop
my @arr1 = (11,22,33);
say pop @arr1; # 33
say pop @arr1; # 22
say pop @arr1; # 11
say pop @arr1; # undef,警告模式下会给出警告
# shift
my @arr2 = (11,22,33);
say shift @arr2; # 11
say shift @arr2; # 22
say shift @arr2; # 33
say shift @arr2; # undef,警告模式下会给出警告
对于push、unshift:
# push
my @arr1 = (11,22,33);
push @arr1, 44; # 追加单个元素
push @arr1, 55, 66; # 追加列表,列表的小括号被省略
say push @arr1, (77,88); # 输出8,push返回数组长度
say "@arr1"; # 11 22 33 44 55 66 77 88
# unshift
my @arr2 = (11,22,33);
unshift @arr2, 'a', 'b';
unshift @arr2, qw(aa bb);
say "@arr2"; # aa bb a b 11 22 33
push追加在效果上等价于如下代码,但效率更高:
my @arr;
for my $v (@arr) {
# 向数组尾部追加一个元素
$arr[++$#arr] = $v; # 或者:$arr[~~@arr]=$v;
}
注意,Perl的数组结构和其他语言的数组结构有所不同,其他语言中,这四个函数的效率通常会比使用索引操作方式的效率要更低,但在Perl中,这四个函数的效率比使用索引的处理方式更高,这可能会让人难以置信。原因在于perl已经将这几个函数转换为opcode的方式,它们直接通过C数组索引访问底层的C数组,而如果使用Perl的索引,则先在Perl层面找到P数组的索引位置,然后再访问对应的C数组。不过,多数时候不需要考虑这些操作的效率问题。
另外,shift会导致数组元素向前挪位,unshift会导致数组元素先后挪位。在其他语言中,这样的挪位操作效率非常低,但是在Perl中,这两个操作没有任何效率损失。所以,请放心使用它们。
each
在上一小节已经详细介绍each的使用,参考:小心使用each。
splice
pop/push、unshift/shift操作的都是数组的开头或者末尾。splice则可以指定操作数组中的哪个位置。
splice ARRAY
splice ARRAY,OFFSET
splice ARRAY,OFFSET,LENGTH
splice ARRAY,OFFSET,LENGTH,LIST
splice在移除元素时,在列表上下文返回被移除的元素列表,标量上下文返回最后一个被移除的元素
1.一个参数时,即splice ARRAY,表示清空ARRAY。
use 5.010;
@arr=qw(perl py php shell);
@new_arr=splice @arr;
say "original arr: @arr"; # 输出:空
say "new arr: @new_arr"; # 输出原列表内容
如果splice在标量上下文,则返回最后一个被移除的元素:
use 5.010;
@arr=qw(perl py php shell);
$new_arr=splice @arr;
say "$new_arr"; # 输出:shell
2.两个参数时,即splice ARRAY,OFFSET,表示从OFFSET处开始删除元素直到结尾。
注意,OFFSET可以是负数。
例如:
use 5.010;
@arr=qw(perl py php shell);
@new_arr=splice @arr,2;
say "original arr: @arr"; # 输出:perl py
say "new arr: @new_arr"; # 输出:php shell
如果offset为负数,则表示从后向前数第几个元素,-1表示最后一个元素。
use 5.010;
@arr=qw(perl py php shell);
@new_arr=splice @arr,-3;
say "original arr: @arr"; # 输出:perl
say "new arr: @new_arr"; # 输出:py php shell
3.三个参数时,即splice ARRAY,OFFSET,LENGTH,表示从OFFSET处开始向后删除LENGTH个元素。
注意,LENGTH可以为负数,也可以为0,它们都有奇效。
例如:
use 5.010;
@arr=qw(perl py php shell ruby);
@new_arr=splice @arr,2,2;
say "original arr: @arr"; # 输出:perl py ruby
say "new arr: @new_arr"; # 输出:php shell
如果length为负数,则表示从offset处开始删除,直到尾部还保留-length个元素(例如length为-3时,表示尾部保留3个元素)。例如:
use 5.010;
@arr=qw(perl py php shell ruby java c c++ js);
@new_arr=splice @arr,2,-2; # 从php开始删除,最后只保留c++和js两个元素
say "original arr: @arr"; # 输出:perl py c++ js
say "new arr: @new_arr"; # 输出:php shell ruby java c
如果正数length的长度超出了数组边界,则删除至结尾。如果负数length超出了边界,也就是保留的数量比要删除的数量还要多,这时保留优先级更高,也就是不会删除。例如,从某个位置开始删除,后面还有2个元素,但如果length=-2“,则这两个元素不会被删除。
如果length为0,则表示不删除,这个在有第4个参数LIST时有用。
4.四个参数时,即splice ARRAY,OFFSET,LENGTH,LIST,表示将LIST插入到删除的位置,也就是替换数组的部分位置连续的元素。
例如:
use 5.010;
@arr=qw(perl py php shell ruby);
@list=qw(java c);
@new_arr=splice @arr,2,2,@list;
say "original arr: @arr"; # 输出:perl py java c ruby
say "new arr: @new_arr"; # 输出:php shell
如果想原地插入新元素,而不删除任何元素,可以将length设置为0,它会将新列表插入到offset的位置。
use 5.010;
@arr=qw(perl py php shell ruby);
@list=qw(java c);
@new_arr=splice @arr,2,0,@list;
say "original arr: @arr"; # 输出:perl py java c php shell ruby
say "new arr: @new_arr"; # 输出:空
注意上面php在新插入元素的后面。
列表常见操作
列表常见操作
列表常见操作包括:grep、join、map、reverse、sort、unpack、x操作符执行列表重复,等等。另外,标准库List::Utils中也提供了很多常见的列表操作,如reduce、first、any、sum、uniq、shuffle等。
多数时候,数组可以当作列表来使用,原因是操作列表的地方期待一个列表,即处在列表上下文,perl会隐式地将数组转换为列表。因此上述列表操作多数也适用于数组。
限于篇幅问题,本文只介绍Perl内置的列表操作函数,List::Utils中提供的操作可自行查阅手册或查看我的博客文章List::Util模块用法进行了解。
列表重复:x
使用小写字母x可以重复列表指定次数:
# @arr = (1,2,1,2,1,2)
my @arr = (1, 2) x 3;
列表重复通常用于初始化构建一个特定大小的数组,也常用于生成测试数据。例如:
# 创建包含100个undef元素的数组
# 等价于$arr[99] = undef;
my @arr = (undef) x 100;
# 生成一个大数组(20W个元素),用于某些测试
my @test_data = (11,22) x 100000;
一定要注意,不能将操作符x用于数组,因为x会被解析成字符串重复操作,使得数组处于标量上下文,然后进行字符串重复。例如:
my @arr = (11,22);
say @arr x 3; # 输出:222
如果需要对数组进行重复,将它放进小括号转换为列表即可:
my @arr = (11,22);
@arr = (@arr) x 3;
join
用给定字符将列表中各元素连接起来,返回连接后的字符串。
join语法:
join $sep,$list
例如:
say join "-",qw(a b c d e); # 输出:"a-b-c-d-e"
split
使用给定分隔符将字符串划分为列表,分隔符支持使用正则表达式。
在列表上下文,返回划分后得到的列表,在标量上下文,返回划分后列表的元素数量。
语法:
split /PATTERN/,EXPR,LIMIT
split /PATTERN/,EXPR
split /PATTERN/
split
例如:
my $str="abc:def::123:xyz";
my @list = split /:/,$str;
say join ',', @list; # abc,def,,123,xyz
my $str="abc:def::12:xyz";
my @list = split /::/,$str); # 返回:"abc:def","12:xyz"
my @list = split /[:]+/,$str); # 返回:"abc","def","12","xyz"
my @list = split /[:0-9]/,$str); # 返回:"abc","def","","","","","xyz"
可以加上一个limit参数,限制最多分隔为多少个元素。
例如,指定limit=2,表示只分隔一次:
my $str="abc:def::123:xyz";
my @list = split /:/,$str,2; # 返回"abc","def::123:xyz"两个元素
省略limit时,默认limit=0,表示尽可能多地划分元素,且忽略后缀空元素,但会保留前缀空元素。limit为负数时,几乎等价于limit=0,但不忽略后缀空元素。例如:
my $str=":::abc:def:123:xyz::::";
my @new_list1=join(".",split /:/,$str);
my @new_list2=join(".",split /:/,$str, -1);
say "@new_list1"; # ...abc.def.123.xyz
say "@new_list2"; # ...abc.def.1234.xyz....
省略字符串参数时(意味着也必须省略limit),split默认对$_进行划分:
split /:/; # 等价于 split /:/, $_;
对于split,除了常规用法,更重要的是要记住它的特殊用法:
-
将pattern指定为空格
" "时(注意,不是正则里的空格/ /),和awk的行为一样:忽略前缀空白,且将一个或多个空白作为分隔符my $str = " a b c "; my @arr = split " ", $str; say join ",", @arr; # a,b,c -
省略pattern时(意味着后面其他参数也被省略),即不带任何参数的split,默认pattern为空格
" ",对$_变量进行划分 -
将pattern指定为
//时(空正则表达式),字符串的各字符都被划分my $str = "abc"; my @arr = split //, $str; say join ",", @arr; # a,b,c
grep
从列表中筛选符合条件的元素,在列表上下文返回符合条件的元素列表,在标量上下文中返回符合条件的元素数量。
grep BLOCK LIST
grep EXPR, LIST
例如,筛选列表中的偶数和奇数:
my @nums = (11,22,33,44,55,66);
my @odds = grep {$_ % 2} @nums; # 取奇数
my @evens = grep {$_ % 2 == 0} @nums; # 取偶数
say "@odds";
say "@evens";
grep会迭代列表中的每一个元素,并将这些元素逐次【赋值】给默认变量$_,在给定的语句块BLOCK中可以使用该默认变量,当BLOCK中的代码评估结果为布尔真,则将本次迭代的元素放进返回值列表中等待被返回。
当BLOCK中只有一条语句或一个表达式时,可以使用grep expr,list语法。例如,上面示例的等价写法:
grep $_ % 2, @nums;
grep $_ % 2 == 0, @nums;
注意,grep在迭代列表各元素时,$_是各元素的别名引用,在代码块中修改$_,也将影响到源列表,也因此会影响返回值列表。
my @nums = (11,22,33,44,55,66);
my @arr = grep {$_++; $_ % 2} @nums;
say "@arr"; # 23 45 67
say "@nums"; # 12 23 34 45 56 67
map
语法:
map BLOCK LIST
map EXPR, LIST
map迭代列表的每个元素,并将表达式或语句块中返回的值放进一个列表中,最后返回这个列表。
例如:
my @chars = map(chr, (65..70));
say "@chars"; # A B C D E F
my @arr = map { $_ * 2 } (1..5);
say "@arr"; # 2 4 6 8 10
当语句块中只有一条语句时,可使用表达式写法。如
my @arr = map $_*2, (1..5);
say "@arr"; # 2 4 6 8 10
同grep一样,map迭代每个元素时,$_是这些元素的别名引用,修改$_将会修改元素原始数据。
注意,Perl map不是完全等量映射,不一定会返回和原列表元素数量相同的列表。特别地,如果语句块中返回空列表(),相当于没有向返回列表中追加元素。例如:
my @arr = (11,22,33,44,55);
# @evens = (undef,22,undef,44,undef)
my @evens = map {$_ if $_%2==0} @arr;
# @evens = (22,44)
my @evens = map {$_%2==0 ? $_ : ()} @arr;
# 等价于 map {$_} grep {$_%2==0} @arr;
并且,map允许在一个迭代过程中保存多个元素到返回列表中。
my @name=qw(ma long shuai);
my @new_names=map {$_,$_ x 2} @name;
say "@new_names"; # ma mama long longlong shuai shuaishuai
正因为map可以一次向返回列表中添加多个元素,因此可以每次迭代生成两个元素并将map返回值赋值给hash:
my @name=qw(ma long shuai gao xiao fang);
my %new_names = map {$_, $_ x 2} @name;
while (my ($key,$value) = each %new_names){
say "$key --> $value";
}
输出结果:
long --> longlong
xiao --> xiaoxiao
gao --> gaogao
ma --> mama
shuai --> shuaishuai
fang --> fangfang
当map的BLOCK返回两个元素时,map的大括号可能会和构建匿名hash结构的大括号产生歧义。Perl会尽量根据规则取猜测大括号是map的语句块还是用于构建匿名hash的。
# 下面的大括号被猜错了,当作了匿名hash的构建大括号
# 等价于 map \%hash @array
my %hash = map { "\L$_" => 1 } @array
# 给点提示,在第一个元素前使用`+`,使其不能作为hash的key
my %hash = map { +"\L$_" => 1 } @array
my %hash = map {; "\L$_" => 1 } @array # 这也可以
my %hash = map { ("\L$_" => 1) } @array # 这也可以
my %hash = map { lc($_) => 1 } @array # 这也可以
my %hash = map +( lc($_) => 1 ), @array # 这也可以
my %hash = map ( lc($_), 1 ), @array # 评估为(1, @array)
sort
sort用于对列表元素进行排序,返回排序后的列表。
sort SUBNAME LIST
sort BLOCK LIST
sort LIST
对于sort LIST语法,表示按照默认的字符串顺序进行排序(比如ASCII码顺序)。需要了解的几个顺序是:
最小:空值(0,undef,""等)
制表符(\t)
换行符(\n)
空格(space)
某些标点符号(主要考虑的是负号 - )
数字(0-9)
大写字母(A-Z)
小写字母(a-z)
例如:
my @str=qw(abc Abc ABc 123);
my @sorted=sort @str;
say "@sorted"; # 123 ABc Abc abc
对于sort BLOCK LIST语法,sort首先会从列表中取出两个元素,分别赋值给两个特殊的变量$a和$b(仍然是引用别名的关系,修改这两个变量将会影响原始元素):
- 若语句块返回-1,则表示
$a对应的元素小于$b对应的元素,$a将排在$b的前面 - 若语句块返回1,则表示
$a对应的元素大于$b对应的元素,$a将排在$b的后面 - 若语句块返回0,则表示
$a对应的元素等于$b对应的元素,$a和$b的位置不变
因此,可以编写如下代码对一串数字进行排序。
my @nums = (11,33,4,55,7,12);
# 升序排序
my @sorted_nums = sort {
if($a<$b){
-1
} elsif($a > $b) {
1
} else {
0
}
} @nums;
say "@sorted_nums"; # 4 7 11 12 33 55
Perl提供了两个非常好用的运算符:
<=>:用于比较数值,如果左边的数值小于右边的数值,则返回-1,大于则返回1,相等则返回0cmp:用于比较字符串,规则和<=>相同
因此,使用比较运算符来改写上面的升序排序:
my @nums = (11,33,4,55,7,12);
# 升序排序
my @sorted_nums_asc = sort {$a<=>$b} @nums;
# 降序排序
my @sorted_nums_desc = sort {$b<=>$a} @nums;
say "@sorted_nums_asc"; # 4 7 11 12 33 55
say "@sorted_nums_desc"; # 55 33 12 11 7 4
但是,在使用<=>时需要小心,因为<=>比较的是两个数值,如果有一方不是数值,将返回undef。而在sort中,它们被当作最小值
- 如果是正向排序,则非数值排在最前面
- 如果是逆序排序,则非数值排在最后面
下面是几个sort排序示例。
sort排序示例1:排序一串字符串,从字符串的第3个字符开始排序。
my @str = qw(Abxx bbcda bdef ab);
my @sorted = sort {substr($a,2) cmp substr($b,2)} @str;
say "@sorted";
sort排序示例2:对hash进行排序,排序依据是按照数值大小比较value。
例如,存放姓名和工资的hash,想要按照他们的工资进行排序,如果工资相同,则按照名字的大小顺序进行排序。最后输出排序后的姓名。
可以先使用keys获取key列表,再通过$hash{key}对每个value作比较,从而得到key的顺序。
my %name_salary = (
malong => 8000,
wugui => 6000,
xiaofang => 9000,
longshuai => 6000,
woniu => 10000
);
my @sorted_key = sort {
# 先对工资按数值进行排序
$name_salary{$a} <=> $name_salary{$b}
or
# 如果工资相同,则按照姓名大小排序
$a cmp $b
} keys %name_salary;
say "@sorted_key"; # 输出:longshuai wugui malong xiaofang woniu
注意,上面的or操作符,当比较的两个工资不等的时候,or前面的<=>比较返回1或-1,它们都表示true,于是短路直接返回给sort;当两个工资不等的时候,or前面的<=>比较返回0,它表示false,于是比较or后面的cmp,同样返回1、-1、0给sort。
reverse
reverse用于反转列表:在列表上下文中返回元素被反转后的列表,在标量上下文中,返回原始列表各元素组成的字符串的反转字符串。
my @arr1 = qw(aa bb cc dd);
say "@{[reverse @arr1]}"; # dd cc bb aa
say ~~(reverse @arr1); # ddccbbaa,返回aabbccdd的反转
reverse可以在标量上下文中直接反转一个字符串。
say ~~reverse "hello"; # olleh
reverse也常结合sort一起使用,用来反转sort排序后的结果。但注意,reverse结合sort并不会二次排序,perl会在sort排序时自动将reverse效果应用在sort排序期间,因此不会带来效率的下降。
my @arr = qw(Abxx bbcda bdef ab);
my @r_sorted = reverse sort {length $a <=> length $b} @arr;
say "@r_sorted";
Perl范围
范围
在Perl中,可以使用两点运算符..或三点运算符...表示一个范围。在列表上下文中两者等价,在标量上下文中两者不等价。
列表上下文中的范围
在列表上下文中,对于范围A..B来说,它返回从A到B中间所有的值,且包含边界的A和B,每一个值都是前一个值自增(即++运算符)之后的结果。如果左边的A值大于右边的B值,将表示空范围。
例如3..6表示3、4、5、6共四个数,'a'..'d'表示a、b、c、d共四个字母。
范围常用来为列表提供数据。例如:
my @arr1 = 1..3; # 1 2 3
my @arr2 = ('A'..'Z'); # 所有大写字母
my @arr3 = ('a'..'z'); # 所有小写字母
my @arr4 = ('a'..'z','A'..'Z'); # 所有大小写字母
my @arr5 = (0,3..5,7,10..20); # 离散数据:0 3 4 5 7 10到20
my @arr6 = ('01'..'31'); # 两位数日期
my @arr7 = ('01'..'12'); # 两位数月份
通过范围来指定循环执行次数变得非常简单:
# 循环10次
for(1..10){
say $_;
}
范围也常用于标量上下文。在标量上下文中,范围表示一个布尔值,Perl将这种情况下的操作符称为flip..flop,flip就像合上开关,flop就像打开开关。
标量上下文中的范围,表示的含义是:
A..B:从表达式A返回布尔真开始,到表达式B返回布尔真结束,评估表达式A之后会立即评估表达式BA...B:从表达式A返回布尔真开始,到表达式B返回布尔真结束,评估表达式A之后不会立即评估表达式B,而是下一次再评估B
无论是哪种方式,在左表达式开始为真之前,不进入范围,此时不会评估表达式B;在左表达式开始为真后,进入范围,在右表达式为真结束范围之前,不会再继续评估左表达式。简单来说,对于A..B,在A为真之前,不会执行B,在A为真之后、B为真之前,不会再执行A。
例如:
my $i = 0;
# 从0开始,左表达式为真,开始进入范围
# 到5结束,此时右表达式为真,结束范围
# 范围不要放在for、foreach里,它们是列表上下文
while(($i==0)..($i==5)){
say $i; # 输出:0 1 2 3 4 5
$i++;
}
注意,最好不要让右表达式处在左表达式所表示的范围中。例如,下面将是一个无限循环:
my $i = 0;
# 无限循环,从0到5是正常的范围,
# 从6开始,左表达式再次为真,但右表达式一直为假
while(($i>=0)..($i==5)){
say $i;
$i++;
}
如果进入范围时,左表达式和右表达式都为真,对于A..B,将立即结束范围。如果不想在进入范围时评估B,使用A...B。
例如:
my $i = 0;
# i为0时,左右表达式都为真,立即终止范围
# 因此只输出0
while(($i==0)..($i>=0)){
say $i;
$i++;
}
$i = 0;
# 变量i为0时,左表达式为真,开始进入范围,
# 此时不评估右表达式,第二轮循环才评估右表达式
# 因此输出0和1
while(($i==0)...($i>=0)){
say $i;
$i++;
}
很多时候,标量上下文中的范围flip..flop的左右表达式都是字面量而不是完整的表达式。如果flip或flop为数值,则该数值将和所读取内容的行号进行比较,即取行号范围,此时和sed、awk的..效果一致,如果flip或flop为正则表达式,则该正则表达式将与所读取含的内容$_做匹配。这种用法在Perl一行式命令中非常方便。
if(100..200){print;} # 输出第100行到第200行
next if (1.../^$/); # 跳过文件开头的所有空行
next if(/^$/..eof()); # 忽略从空行开始的所有行
hash类型
在不同语言中,hash类型有时候也被称为关联数组、映射、字典、散列等,这些概念描述的是同一种结构:存储键值对(key/value)的数据结构。
key和value之间一一映射,每一个key和对应的value组成一个键值对,每一个键值对也被称为hash的一个元素或一个entry。
例如,下面的变量person是一个hash变量,存储了三对key/value,name对应junmajinlong,age对应23,gender对应male。
%person = (
name => "junmajinlong",
age => 23,
gender => "male",
);
hash基本用法
hash基本用法
Perl中hash类型的变量使用%前缀表示,由列表创建而成,列表的格式为(k1,v1,k2,v2,k3,v3),即按照一个键一个值的方式构建hash。
例如,构建一个名为person的hash变量:
my %person = (
"name" , "junmajinlong",
"age" , 23,
"gender", "male"
);
Perl中,几乎总是可以使用=>代替逗号。因此,下面是等价的方式:
my %person = (
"name" => "junmajinlong",
"age" => 23,
"gender"=> "male"
);
当key的名称符合标识符命名规范时(只包含下划线、字母和数值,且非数值开头),可以省略key的引号。因此,构建hash时通常写成下面这种可读性更高的方式:
my %person = (
name => "junmajinlong",
age => 23,
gender => "male"
);
可以根据$hash{key}的方式来检索hash结构中key对应的value,如果key符合标识符命名规范,则可以省略包围key的引号。
my %person = (
name => "junmajinlong",
age => 23,
gender => "male"
);
say "$person{name}";
say $person{"age"};
如果访问hash中不存在的key,则返回undef,而不会报错:
say $person{class}; # undef
hash变量不能内插到双引号。
say "%person"; # 直接输出:%person
在列表上下文,hash变量会自动隐式转换为(k1,v1,k2,v2,k3,v3)格式的列表。
my %person = (
name => "junmajinlong",
age => 23,
gender => "male"
);
# hash展开成列表,默认所有的key和value紧密相连输出
# 修改内置变量`$,`可设置say/print输出时的列表分隔符
say %person; # namejunmajinlonggendermaleage23
$, = "-";
say %person; # name-junmajinlong-gender-male-age-23
在标量上下文,如果hash为空,则转换为数值0,如果hash结构非空,则hash变量会转换为m/n格式的标量,m表示当前的键值对数量,n表示hash结构当前的容量。因此,可以直接将hash变量作为布尔值判断:非空hash为true、空hash为false。
my %h; # 空hash
say ~~%h; # 输出:0
if(%h){say "empty hash"} # 不输出
$h{k1} = "v1";
say ~~%h; # 输出:1/8
if(%h){say "not empty hash"} # 输出
将hash变量赋值给另一个hash变量时,由于赋值hash时在列表上下文,因此会先将hash展开为列表,再赋值。
my %person = (
name => "junmajinlong",
age => 23,
gender => "male"
);
my %p = %person; # %person展开为列表,然后构建%p
多键组合的hash
在向hash中存储数据时,如果想要用多份数据组合起来作为key,那么可以用字符串相连的方式将它们的值连接起来:
my %h;
my ($x, $y) = qw(x, y);
$h{$x.$y} = "junmajinlong.com"; # 等价于$h{"$x$y"}
say $h{"$x$y"};
但这样的方式不安全。例如$x=aa,$y=aa组合作为key时,和使用$a=a,$b=aaa组合作为key是一样的。
Perl提供了一种更简便、更安全的逗号分隔,方式,当使用逗号分隔多份数据组合为key时,Perl会自动将每份数据使用下标连接符(默认值为\034)连接起来,最终得到的字符串作为key。\034通常可以认为是安全的连接符,它是一个ASCII中的控制字符,几乎不会出现在文本数据中。
my %h;
my ($x, $y) = qw(x y);
$h{$x, $y, "name"} = "junmajinlong.com";
say $h{$x, $y, "name"};
say $h{"$x\034$y\034name"}; # 等价形式
Perl使用的下标连接符由内置变量$;控制,该内置变量的默认值为\034。因此,下面这种写法也和上面的写法等价。
say $h{join($;, $x, $y, "name")};
操作hash
操作hash
hash切片
Perl也支持对hash变量的切片。
例如:
my %phone_num = (
longshuai =>"18012345678",
xiaofang =>"17012345678",
tun_er =>"16012345678",
fairy =>"15012345678"
);
my ($a,$b,$c) = @phone_num{qw(xiaofang fairy xiaofang)};
需要注意的几点是:
- hash切片使用
@前缀,而不是%前缀,因为它代表访问多个内存数据空间 - hash切片的索引部分是一个列表上下文,是表示键的列表
- 因此
@h{qw(a b)}或@h{"a","b"}是有效的,但省略双引号@h{a,b}是错的
- 因此
- hash不可内插至双引号,但hash的切片可以内插到双引号,因为hash切片的结果是一个列表
- hash切片可以作为左值,从而修改hash中对应的键值对数据
my %phone_num = (
longshuai =>"18012345678",
xiaofang =>"17012345678",
tun_er =>"16012345678",
fairy =>"15012345678"
);
# 双引号中内插hash切片
say "@phone_num{qw(fairy longshuai)}";
# hash切片作为左值
@phone_num{qw(fairy longshuai)} = qw(155555555 188888888);
say "@phone_num{qw(fairy longshuai)}"; # 输出:155555555 188888888
hash类内置函数
perl提供了几个基本的hash内置函数:delete、each、exists、keys、values。
keys和values
keys和values分别用来获取hash的key列表和value列表。注意,hash各元素的出现顺序是不可预测的。
my %h = qw(k1 v1 k2 v2 k3 v3);
my @keys = keys %h;
my @values = values %h;
say "keys: @keys"; # 输出:keys: k3 k2 k1
say "values: @values"; # 输出:values: v3 v2 v1
each和遍历hash
each常和while结合用来遍历数组和hash。每次each迭代时,都获取索引和对应值,并作上位置标记,下次从标记处开始继续迭代。需小心使用each,原因可参考小心使用each。
例如:
while(my ($k, $v) = each %hash){
say "key: $k, v: $v";
}
for、foreach也可以遍历hash,但只能通过keys函数来遍历Key,通过values函数来遍历Value。
my %myhash = qw(k1 v1 k2 v2 k3 v3);
# foreach迭代遍历key
foreach my $k (sort keys %myhash){
say $k, $myhash{$k};
}
# 迭代遍历value
foreach my $v (values %myhash){
say $v;
}
此外,还需注意,each、keys、values这三个函数共用一个迭代指针,每次调用keys、values时都会重置each的迭代指针。因此,while + each遍历hash时,循环体内要小心使用keys、values函数。
例如,下面的代码将无限循环。
while(my ($k, $v) = each %p){
say "k: $k, v: $v";
keys %p;
# keys在空上下文中只重置迭代指针而不返回key列表,因此效率不受影响
}
exists和判断键是否存在
exists用来判断hash结构中是否存在某个key,如果存在则返回表示布尔真的结果(数值1)。由于Perl中访问hash结构中不存在的键值对时不会报错,而是返回undef,因此有时候也会直接使用hash索引的方式来测试。但注意,如果key存在于hash结构中,但其对应的值表现为布尔假(即value为undef、0或空字符串等值)时,两种方式测试结果将不同。
my %h;
if(exists $h{k1}){...}
if($h{k1}){...}
$h{k1} = undef;
if(exists $h{k1}){say "1"} # 输出
if($h{k1}){say "2"} # 不输出
删除键值对和清空hash
delete用来删除hash结构中的键值对,可以使用hash切片方式一次性删除多个键值对。
my %hash = (
a => "aa", b => "bb",
c => "cc", d => "dd"
);
delete $hash{a}; # 删除单个键值对
delete @hash{qw(b c)}; # 根据hash切片删除
$, = "-";
say %hash; # d-dd
作为技巧,delete @HASH{keys %HASH}会清空hash,但效率很低。清空hash效率更高的是下面这两种方式:
%HASH = (); # 直接清空hash
undef %HASH; # 注销hash变量
delete还有一个特殊的用法:delete local,它只会在当前作用域内删除hash键值对,退出该作用域后,被删除的键值对仍然存在。
my %hash = (
a => "aa", b => "bb",
c => "cc", d => "dd"
);
$, = '-';
{
delete local $hash{a};
say %hash; # 输出:b-bb-c-cc-d-dd
}
say %hash; # 输出:d-dd-c-cc-a-aa-b-bb
了解hash结构的基本特性
了解hash结构的基本特性
介绍了Perl中如何使用hash类型后,有必要了解一些关于hash的基本特性。
hash结构中的key是唯一的。在将键值对存储到hash结构时,会对key进行hash计算,然后根据计算得到的hash值决定该键值对的值存储在何处,由于相同的key总是计算得到相同的hash值,因此先后两次存储key相同的键值对时,后存储的值将覆盖已存储的值。
my %person = (
name => "junmajinlong",
age => 23,
);
$person{name} = "junma"; # 覆盖name键映射的值
但是,不同的key也可能会计算出相同的hash值,这时将造成hash冲突(hash碰撞)问题:不同的键值对将存储在同一个位置。虽然hash冲突的计算较低,但仍然需要提供hash冲突时的解决方案,hash冲突的解决方案有多种,不同语言采用不同的策略。
hash结构不保证键值对的顺序,比如遍历时的顺序是不可预测的,并且插入新的键值对可能还会改变顺序,因此不要依赖hash的键值对顺序。另外,有些语言实现了按照键值对存储时的先后顺序进行遍历。
my %person = (
name => "junmajinlong",
age => 23,
);
my @keys = keys %person;
say "@keys"; # name age
$person{gender} = "male";
@keys = keys %person;
say "@keys"; # name gender age
hash结构的内存空间利用率不高。hash结构会划分hash桶(hash bucket),每个桶都预分配一些空间槽(slot),槽的数量决定了一个桶中最多能存放多少数据。每次存储键值对时,都将根据对key计算出来的hash值决定value存放在哪个桶以及桶的哪个位置(slot)。
hash结构的搜索速度和增删键值对的速度很快,且不会随着所存储键值对元素数量的增长而变慢,它由hash桶的大小决定。而数组的平均搜索速度则会随着元素的增长而逐渐变慢。
但是,当某次向hash中存储键值对时因空间不够而触发了扩容,速度会很慢,因为扩容时需要迁移整个hash结构,包括对所有的key进行rehash、拷贝内存数据。因此,一次性存储大量键值对时,会明显感受到长久的耗时。
例如,下面构建1000W个元素的hash耗时6.8秒,构建1000W个元素的数组只需0.7秒。
use 5.012;
use Time::HiRes qw(time);
my $num = 10_000_000;
my %h;
my $h_start = time;
for my $i (1..$num){ $h{$i} = 1; }
my $h_end = time;
my $h_diff = $h_end - $h_start;
say "time diff: $h_diff";
my @arr;
my $a_start = time;
for my $i (1..$num){ $arr[$i-1] = 1; }
my $a_end = time;
my $a_diff = $a_end - $a_start;
say "time diff: $a_diff";
流程控制结构
本章介绍Perl语言中的流程控制语句,包括布尔值判断、条件判断语句、循环语句以及循环语句的流程控制。这些语句都使用大括号,这些大括号都有自己的作用域。
本章还介绍Perl中如何进行错误处理,它也可以看作是流程控制的一种。
布尔值判断
布尔值判断
Perl没有专门提供布尔类型,它使用一些特殊的值代表布尔假,除了代表布尔假的值,其他值都代表布尔真。
代表布尔假的值包括:undef、0、空字符串。但注意:
- Perl数值还包括可转换为数值的字符串,所以字符串
"0"也是布尔假,且是唯一非空字符串为假的特例 - 由于布尔判断操作处于标量上下文,这使得列表、数组、hash会转换成标量,然后判断是否是布尔假
- 列表和数组转换为标量时,转换结果为长度
- hash转换为标量时:空hash转换为数值0,非空hash转换为
M/N格式的字符串
因此,总结以下代表布尔假的值:
- 数值0、0.0
- 空字符串
''、字符串"0" - undef
- 空列表,包括
() ((())) ((),()) - 空数组
- 空hash
除以上代表布尔假的值之外,其余都是布尔真。
一定要注意的是,Perl没有直接代表布尔值的false值和true值。甚至,直接使用false或true有可能会被当作Bareword字符串,从而被误认为布尔真。
# 这里的false被当作bareword字符串
# 关闭strict模式,下面会输出hello
if(false){say "hello"}
比较运算符
比较运算符
Perl数值比较、字符串比较使用如下运算符。可见,和Shell的比较方式正好相反:Shell使用符号格式比较字符串,使用字符串格式比较数值。
数值 字符串 意义
-----------------------------
== eq 相等
!= ne 不等
< lt 小于
> gt 大于
<= le 小于或等于
>= ge 大于或等于
<=> cmp 返回值-1/0/1
最后一个<=>和cmp用于比较两边的数值或字符串,并根据比较结果返回-1、0或1。对于a <=> b或a cmp b:
- a小于b时,返回-1
- a等于b时,返回0
- a大于b时,返回1
对于<=>,如果比较的双方有一方不是数值,该操作符将返回undef。
几个示例:
35 != 30 + 5 # false
35 == 35.0 # true
'35' eq '35.0' # false(str compare)
'fly' lt 'bly' # false
'fly' lt 'free' # true
'red' eq 'red' # true
'red' eq 'Red' # false
' ' gt '' # true,空格大于空串
10<=>20 # -1
20<=>20 # 0
30<=>20 # 1
逻辑运算:and(&&)、or(||)、//、not(!)
逻辑运算:and(&&)、or(||)、//、not(!)
Perl包含以下几种逻辑运算操作符:
not expr # 逻辑取反
expr1 and expr2 # 逻辑与
expr1 or expr2 # 逻辑或
! expr # 逻辑取反
expr1 && expr2 # 逻辑与
expr1 || expr2 # 逻辑或
expr1 // expr2 # 逻辑定义或
其中:
&&运算符只有两边为真时才返回真,且短路计算:expr1为假时直接返回false,不会评估expr2||运算符只要一边为真时就返回真,且短路计算:expr1为真时直接返回true,不会评估expr2not运算符对expr取反,expr为真,则取反后为假,expr为假,则取反后为真not and or基本等价于对应的! && ||,但文字格式的逻辑运算符优先级非常低,而符号格式的逻辑运算符优先级则较高//运算符见下文
因为符号格式的逻辑运算符优先级很高,所以往往左边和右边都会加上括号,而文字格式的优先级很低,左右两边不需加括号
if (($n >=60) && ($n <80)){ print "..."; }
if ($n >=60 and $n <80){ print "..."; }
or运算符往往会用于连接两个【成功执行,否则就】的子句。例如,打开文件,如果打开失败,就报错退出perl程序:
open LOG '<' "/tmp/a.log" or die "Can't open file!";
有时候还会分行缩进:
open LOG '<' "/tmp/a.log"
or die "Can't open file!";
同样,and运算符也常用于连接两个行为:左边为真,就执行右边的操作(例如赋值)。
$m < $n and $m = $n; # 将$m和$n之间较大值保存到变量m
逻辑运算的返回值
在Perl中,还需关注逻辑运算的返回值:返回最后计算的那个表达式的结果值。
对于expr1 && expr2,如果expr1计算结果为假,则短路计算,直接返回expr1的计算结果。如果expr1计算结果为真,将会继续计算expr2,于是返回的是expr2的计算结果。
对于expr1 || expr2,如果expr1计算结果为真,则段落计算,直接返回expr1的计算结恶果。如果expr1计算结果为假,将会继续计算expr2,于是返回的是expr2的计算结果。
对于! expr,如果expr计算结果为真,则返回undef(在不同上下文可转换为数值0或空字符串),如果expr计算结果为假,则返回代表布尔真的数值1。
作为技巧,可以将两个!一起用,如!!a,它会【负负得正】:如果原来a代表布尔真值,负负得正后会得到代表布尔真的1,如果原来a代表布尔假值,负负得正后得到代表布尔假的undef(在不同上下文可转换为数值0或空字符串)。也就是说,!!在布尔判断效果上不会变化,但会将值转换为undef或1。
say !!"abc"; # 1
say !!""; # 空
say ((!!"") + 2); # 2
关于||和//
||会短路计算,且有返回值。结合这两点,可以为变量做默认赋值。
例如:
my $name = $myname || "junmajinlong"
当变量myname未定义时,将"junmajinlong"赋值给变量name,当变量myname已定义时,将myname的值赋值给变量name。因此,这样的赋值方式可以让变量name有默认值。
但是,这样的方式不严谨,因为有两种情况都会将junmajinlong作为默认值赋值给变量name:
- 变量myname处于未定义状态
- 变量myname已定义,但其值为undef、空字符串、数值0等代表布尔假的值
因此,为了确保在myname处于未定义状态或值为undef时才将junmajinlong作为变量name的默认值,Perl v5.10提供了另一种逻辑运算符//,它也称为【逻辑定义或】(logical defined-or):如果左边的值不是undef(包括未定义变量),则短路运算且返回左边的值,如果左边的值为undef,则计算并返回右边表达式的值。
现在,可以使用//为变量赋以默认值:
use 5.010;
my $name = $myname // "junmajinloing";
当开启了warnings时,//可以免除使用undef值的警告,但仍然无法避开use strict模式下使用未定义变量的编译错误。
use warnings;
# 无警告,尽管使用了undef
my $name = undef // "junmajinloing";
use strict;
# 报错,使用了未定义变量myname
my $name = $myname // "junmajinloing";
条件判断:if、unless和三元运算
条件判断:if、unless和三元运算
if和unless都是条件判断语句,它们都支持else子句和任意数量的elsif子句。语法如下;
if(COND){ # 或者 unless(COND)
command
}
if(COND1){ # 或者 unless(COND1)
command1
}elsif(COND2){
command2
}elsif(COND3){
command3
} else {
commandN
}
if(COND){ # 或者 unless(COND)
command1
}else{
command2
}
注意,COND可以是任意一个表示布尔值的值或表达式,它是一个标量上下文。Perl中任何一个需要进行条件判断的地方都是标量上下文。
例如:
# 如果默认变量$_中有换行符,则去除换行符后使用say输出
if(chomp){ # chomp操作字符串时返回1或0
say $_;
}
# 如果数组元素数量大于等于5,则输出前5个元素
if(@arr >= 5){
say "@arr[0..4]";
}
unless和if判断方式相反,对于if,条件为真时执行紧跟着的语句块,对于unless,条件为假时执行紧跟着的语句块。所以,unless相当于if的else部分,或者说unless(cond)相当于if(!cond)。
# 除非数组元素数量小于5,否则就输出前5个元素
unless(@arr < 5){
say "@arr[0..4]";
}
多数时候,只会用到unless的单分支,不会用到unless的else或elsif子句,因为这样的逻辑可以改写成等价但更易懂的if语句。
三元运算符
Perl也支持三元运算符:如果expr返回真,则执行并返回when_true的结果,否则执行并返回when_false的结果。
expr ? when_true : when_false
例如,求平均值,如果$n=0,则输出------。
$avg = $n ? $sum/$n : "------";
注意上面示例中的优先级问题,赋值运算符=的优先级只比not and or和逗号运算符的优先级高,因此赋值操作几乎总是在最后才执行。
三元运算符是对if(expr){when_true}else{when_false}的简写。例如上面示例等价于下面的if逻辑:
if($n){
$avg = $sum / $n;
}else{
$avg = "------";
}
三目运算符可以写出更复杂的分支:
# 如果$score小于60分,则mark为c
# 如果大于等于60小于80,则mark为b
# 如果大于等于80小于90,则mark为c
# 其余情况,mark为d
$mark = ($score < 60) ? "c" :
($score < 80) ? "b" :
($score < 90) ? "a" :
"a++"; # 默认值
say $mark;
循环控制语句
循环控制语句
Perl中支持while循环、until循环、for循环、foreach循环,还支持for迭代遍历、foreach迭代遍历。在循环或迭代时,循环体内可以通过last、next、redo以及continue来控制循环流程。
此外,Perl还支持标签功能、goto语句、纯语句块以及do语句。
while循环和until循环
while循环和until循环是类似的:
- 对于while循环,只要条件判断为布尔真,就执行循环体,直到条件判断为假
- 对于until循环,只要条件判断为布尔假,就执行循环体,直到条件判断为真
语法如下:
while(CONDITION){
commands;
}
until(CONDITION){
commands;
}
注意条件判断处于标量上下文。
例如,循环10次:
my $i = 0;
while($i<10){
say $i;
$i++;
}
while也常结合each一起使用来遍历hash数据。例如:
while(my($k,$v)=each %p){
say "k: $k, v: $v";
}
for循环和foreach循环
Perl中的for和foreach支持两种语法:类C的for循环语法和迭代时的for迭代语法。for循环和foreach循环等价,for迭代和foreach迭代等价。
以for循环为例。例如:
for($i=1;$i<=10;$i++){
print $i,"\n";
}
print $i,"\n"; # 输出11
需要注意的是,上面的$i默认是全局变量,循环结束后还有效,在开启了strict模式后会报错。可以将其声明为局部变量:
for (my $i = 1;$i<=10;$i++ ){
print $i,"\n";
}
for循环不仅仅只支持数值递增、递减的循环方式,还支持其它类型的循环,只要能进行条件判断即可。见下面的例子。
for循环和foreach完整的语法为:
for (expr1; expr2; expr3) {
...
}
foreach (expr1; expr2; expr3) {
...
}
循环的执行流程为:首先执行expr1,这部分是for的初始操作,然后执行expr2进行条件判断,如果expr2为真,则执行一次循环体,执行完循环体后执行一次expr3,然后再执行expr2进行条件判断,为真则执行循环体,然后expr3,然后expr2,如此一直循环,直到expr2为布尔假时退出循环。
for括号中的3个表达式都可以省略,但两个分号不能省略:
- 如果省略第三个表达式,则表示一直判断,直到退出循环或者无限循环
- 如果省略第二个表达式,则表示不判断,因此会无限循环
- 如果省略第一个表达式,则表示不执行初始操作(比如初始赋值)
例如,下面分别省略第三个表达式和省略所有表达式:
# 每次删除字符串开头一个字符,直到删除完所有字符
for(my $str="junmajinlong";$str =~ s/(.)//;){
say $str;
}
# 无限循环
for(;;){
say "never stop";
}
对于无限循环,下面这种while方式更方便:
while(1){
command;
}
for迭代和foreach迭代
for迭代语法和foreach迭代语法是一致的。
对于for、foreach迭代遍历语法,其语法为:
for my $i (LIST) {}
for (LIST){}
foreach my $i (LIST) {}
foreach (LIST){}
下面以for迭代语法为例。
for会从列表中不断迭代每一个元素,每次取得一个元素并【赋值】给控制变量$i,如果没有指定控制变量,则【赋值】给默认变量$_。直到取完列表所有元素,迭代完成。
# 循环5次
for (1..5){
say $_;
}
# 遍历数组
my @arr1 = qw(a b c d e f);
for my $i (@arr1){
say $i;
}
# 带索引的数组遍历
my @arr2 = qw(a b c d e f);
for(0..$#arr2){
say "index: $_, value: $arr2[$_]";
}
需注意,for迭代时,控制变量$i指向每个被迭代的元素。因此,修改$i也会影响原始数据。例如:
my @arr = qw(1 2 3 4 5);
for (@arr){
say $_;
$_++;
}
say "@arr"; # 2 3 4 5 6
另外,迭代过程中改变列表长度,也会影响迭代过程。例如:
my @arr = qw(1 2 3 4 5);
for (@arr){
say $_; # 输出1 3 5
shift @arr;
}
say "@arr"; # 4 5
纯语句块
纯语句块即单独一个大括号:
{...}
纯语句块实际上是一个只循环一次的循环结构。
纯语句块常用来创建一个局部作用域,在该语句块内声明的局部变量,退出语句块后失效。
my $a = 1;
{
say $a; # 1
my $a = 33; # 将掩盖外部变量a
say $a; # 33
} # 退出语句块,语句块内的变量a失效
say $a; # 1
控制循环流程
控制循环流程
标签
Perl允许为循环结构打标签:
LABEL while (EXPR) BLOCK
LABEL until (EXPR) BLOCK
LABEL for (EXPR; EXPR; EXPR) BLOCK
LABEL for VAR (LIST) BLOCK
LABEL foreach (EXPR; EXPR; EXPR) BLOCK
LABEL foreach VAR (LIST) BLOCK
# 纯语句块也可以打标签,它是执行一次的循环结构
LABEL BLOCK
为循环结构打标签后,last、next等可以控制循环流程的关键字就可以指定要控制哪个层次的循环结构。
last、next、redo
这三个关键字都用于控制循环的执行流程:
- last相当于其它语言里的break关键字,用于退出循环(包括for/foreach/while/until/纯语句块)
- next相当于其它语言里的continue关键字,用于跳入下一轮循环
- redo用于跳转到当前循环层次的顶端,使得本轮循环从头开始再次执行
下面是一些示例。
last:
# 当变量i等于5时退出循环
# 该循环将输出1 2 3 4
for my $i (1..10){
if($i==5){
last;
}
say $i;
}
next:
# 当变量i等于5时进入下一轮循环
# 该循环将输出1 2 3 4 6 7 8 9 10
for my $i (1..10){
$i == 5 and next;
say $i;
}
redo:
# 当变量i等于5时,再次执行第5轮循环
# 该循环将输出2 3 4 6 6 7 8 9 10 11
for my $i (1..10){
$i++;
$i == 5 and redo;
say $i;
}
如果熟悉sed命令,应该会知道sed里也有类似redo的功能。但其他语言中没有类似redo的功能。可通过下面示例再感受一下redo的效果。
use open ':std', ':encoding(UTF-8)';
foreach (1..5){
say "请输入redo";
chomp($_ = <>); # 从终端读取输入
/redo/i and redo;
say "你没有输入redo";
}
默认情况下,last、next和redo控制的都是当前层次的循环结构,可以为它们指定标签来决定要控制哪个外层循环。下面是使用标签控制外层循环的一个示例:
OUTER:
while (1) {
print "start outer\n";
while (1) {
print "start inner\n";
last OUTER;
print "end inner\n";
}
print "end outer\n";
}
print "done\n";
将输出:
start outer
start inner
done
附加循环代码:continue
Perl中还有一个continue关键字(perldoc -f continue),它可以是一个函数,也可以跟一个代码块。
continue # continue函数
continue BLOCK # continue代码块
如果指定了BLOCK,continue可用于循环结构之后。
while (EXPR) BLOCK continue BLOCK
until (EXPR) BLOCK continue BLOCK
for VAR (LIST) BLOCK continue BLOCK
foreach VAR (LIST) BLOCK continue BLOCK
BLOCK continue BLOCK
continue表示在循环结构的主循环代码块之后附加了一段额外的代码块,每轮循环中,在执行完主循环代码块后都会执行continue部分的代码块,执行完后才进入下一轮循环。
当循环结构给定continue代码块后,redo、last和next关键字的控制规则为:
- redo、last直接控制整个循环主体
- next总是跳转到continue代码块开头
continue语句块中也可以使用redo、last和next关键字,控制规则不变。
以while + continue为例,当在continue中使用next、last、redo时:
while(){
# <- redo会跳到这里
CODE
} continue {
# <- next总是跳到这里
CODE
}
# <- last跳到这里
实际上,如果没有在循环语句中指定continue语句块,逻辑上等价于给了一个空的continue代码块,这时next可以跳转到空代码而进入下一轮循环。
例如:
my $a=3;
while($a<8){
if($a<5){
say '$a in main if block: ',$a;
next;
}
} continue {
say '$a in continue block: ',$a;
$a++;
}
输出结果:
$a in main if block: 3
$a in continue block: 3
$a in main if block: 4
$a in continue block: 4
$a in continue block: 5
$a in continue block: 6
$a in continue block: 7
通过循环实现一个简单的Perl Shell
Perl自身没有提供交互式的Shell,有时候要测试Perl代码不是很方便。但实现一个简单的交互式的Perl Shell也比较简单:
while(print ">> ") { # 无限循环,输出提示符
# 读取终端输入,去除行尾换行符
chomp ($_ = <>);
# 当输入q并回车时,退出循环
/^q$/ && last;
# 执行输入的perl代码,并输出执行代码的返回值
say "=> ", (eval $_) // "undef";
}
虽然有很多不足,但做简单的临时测试工具,已经足够了。执行效果如图:
$ perl perl_shell.pl
>> 33 + 44
=> 77
>> $a = 33
=> 33
>> print $a;
33=> 1
>> say $a;
33
=> 1
>> my $b;
=> undef
>> if($a){say "$a"}
33
=> 1
>> q # 退出
流程控制语句修饰符和do语句块
流程控制语句修饰符和do语句块
Perl支持单条语句后面加流程控制符。
command Operator Cond;
这样的结构称为流程控制表达式。其中:
- command部分是要执行的语句或表达式
- Operator部分支持的操作符有if、unless、while、until和foreach,它们称为流程控制语句修饰符
- Cond部分是条件判断
整个结果的逻辑是:如果条件判断通过,则根据操作符决定是否要执行command部分。
例如:
print "true.\n" if $m > $n;
print "true.\n" unless $m > $n;
print "true.\n" while $m > $n;
print "true.\n" until $m > $n;
print "$_" foreach @arr;
这种流程控制表达式结构有几个注意点:
-
控制符左边只允许一个命令(语句或表达式),除非使用do语句块,参见下文介绍的do语句块
-
foreach的时候,不能自定义控制变量,只能使用默认的
$_ -
while或until循环的时候,因为要退出循环,只能将退出循环的条件放进前面的命令中。如:
print "abc",($n += 2) while $n < 10; print "abc",($n += 2) until $n > 10;
do语句块
do语句块结构如下:
do {...}
do语句块像是匿名函数一样,给定一个语句块,直接执行。且和函数一样,do语句块有返回值,它的返回值是最后一个被执行语句的返回值。
例如,将使用if-elsif-else结构进行赋值的行为改写成do。以下是if-elsif-else结构:
my $name;
if($gender eq "male"){
$name="Junmajinlong";
} elsif ($gender eq "female"){
$name="Gaoxiaofang";
} else {
$name="RenYao";
}
改写成do结构:
my $name=do{
if($gender eq "male"){"Junmajinlong"}
elsif($gender eq "female") {"Gaoxiaofang"}
else {"RenYao"}
}; # 注意结尾的分号
使用流程控制表达式结构的时候,控制符左边只能写一个语句。例如下面的if,左边有了print后,就不能再有其它语句。
print "..." if(...);
使用do结构,可以将多个语句包围,然后执行:
my $a=3;
do {
say "statement1";
say "statement2";
} if $a > 2;
但当do语句块结合while和until操作符使用的时候,效果有所改变。这时候Perl将它们特殊对待为其他语言中的do...while和do...until结构,即do语句块先执行一次,然后才开始进行条件判断。
do {
...
} while cond;
do {
...
} until cond;
最后,需要区分do语句块和纯语句块:
- 它们都只执行一次
- 它们都有自己的代码块作用域
- do语句块相当于匿名函数,有返回值,它不是循环结构,语句块中不能使用last、redo、next
- 纯语句块没有返回值(因此不能赋值给变量),它是只执行一次的循环结构,语句块中可以使用last、redo、next
Perl处理异常
Perl处理异常
Perl自带了die函数,用来报错并退出程序,相当于其他语言中的raise。还自带了warn函数,用法和die类似,它用来发出警告信息,但不会退出。
# 如果打开文件失败,报错退出
if ( ! open LOG "<" "/tmp/a.log" ){
die "open file error: $!";
}
输出的错误信息如下:
open file error: No such file or directory at 1.pl line 4.
上面的特殊变量$!表示Perl调用系统调用出错时由操作系统收集并反馈给Perl的错误信息,即No such file or directory。并非所有的错误都会收集到$!变量中,只有涉及到系统调用且出错时,才会设置$!。例如:
if ( @ARGV < 2 ){
die "wrong! help me!";
}
注意,die和warn默认会输出程序名称和行号,但如果在错误消息后面加上\n换行符,则不会报告程序名称和行号。
if ( @ARGV < 2 ){
die "wrong! help me!\n";
}
croak和carp
Perl自带的die和warn有时候并不友好,它们只会报告代码出错的位置,即哪里使用了die或warn,就报告这个地方有问题。
例如,文件第11行调用函数fff(),函数fff()里的第3行代码(位于文件第20行)错误,使用die和warn时将报告第20行出错,这不利于追踪是在何处调用代码导致的错误。
Carp模块提供的croak和carp函数提供了更细致的错误追踪功能,用法分别对应die和warn,区别仅在于它们会展示更具体的错误位置。
例如:
use Carp 'croak';
sub f{
croak "error in f";
}
f;
报告的错误信息:
error in f at first_perl.pl line 73.
main::f() called at first_perl.pl line 76
eval错误处理
使用die或Carp的croak,都将报错退出程序,如果不想退出程序,可以使用eval来处理错误:当eval指定的代码出错时,它将返回undef而不是退出。
eval有两种用法,一种是字符串作为参数,另一种是语句块作为参数。无论是字符串参数还是语句块参数,参数部分都会被当作代码执行一次。例如:
eval 'say "hello world"';
eval {say "hello world"};
如果eval参数部分执行时没有产生错误,则eval的返回值是最后一条被执行语句的计算结果,并且特殊变量$@为空。
如果eval参数部分执行时产生了错误,则eval的返回值为undef或空列表,同时将错误信息设置到$@中。
因此,可以通过eval结合$@来判断程序是否出错:
eval {...};
if (my $err = $@){
...处理错误:handle_error...
}
之所以将$@保存起来,是因为handle_error可能也有eval,这时handle_error的eval将覆盖之前的$@。
更合理的eval使用方式是:
my $res;
my $ok = eval { $res = some_func(); 1};
if ($ok){
...代码正确...
} else {
...eval代码出错...
my $err = $@;
...
}
Perl正则表达式
本章介绍Perl正则表达式,Perl作为一门强大的文本处理语言,其正则功能比其他语言的正则要丰富许多。
本章假设读者已经具备基础正则表达式的基础,如果对正则还是零基础,可先找一些资料入门,再来学习Perl中的正则。
虽然Perl正则功能非常丰富,但很多时候也用不到那些只在Perl中支持的正则功能,因此本章也只是介绍各种语言通用的正则功能在Perl中的用法。
使用Perl正则进行匹配
使用Perl正则进行匹配
在Perl中使用正则表达式进行匹配是非常简单的一件事。例如:
"abc123def" =~ /\d+/;
上面示例会使用正则表达式\d+去匹配字符串abc123def。其中=~是正则匹配操作符,左边是待匹配的字符串数据,右边是双斜线包围的正则表达式。
Perl中,正则匹配之后,默认不会返回所匹配成功的内容,而是返回一个代表着本次正则匹配是否成功的数据,因此正则匹配可直接用来做条件判断。实际上,Perl正则匹配的返回值问题比较复杂,稍后会详细解释。
my @names = qw(junma jinlong tuner fairy wugui);
my @names1;
for(@names){
push $_,@names1 if($_ =~ /[u-z]/);
}
say "@names1";
当正则表达式要匹配的是变量$_,则可以直接简写为正则表达式。也就是说,$_ =~ /reg/和/reg/是等价的。
因此,上面筛选出包含uvwxyz字符的名字的示例,等价于如下简短代码:
my @names = qw(junma jinlong tuner fairy wugui);
my @names1 = grep {/[u-z]/} @names;
say "@names1";
严格来说,Perl中正则表达式的书写方式为m//,其中斜线可以替换为其它符号,规则如下:
- 双斜线可以替换为任意其它成对符号,例如可以是对称的各种括号
m() m{},也可以是相同的字符m!! m%% - 当采用双斜线时,可省略前缀m字母,即
//等价于m// - 如果正则表达式中出现了和分隔符相同的字符,需转义表达式中的符号,但建议换分隔符,例如
/http:\/\//转换成m%http://%
使用qr创建正则表达式
Perl中除了可以将正则写为m/reg/或省略m的/reg/,还可以通过qr来构建正则表达式。
qr和q、qq、qw类似,只不过它构建的是正则表达式的字面量。例如:
qr/abc.*def/
qr(abc.*def)
qr{ab.*def}
此外,可以在正则模式中使用变量替换,所以可以将正则的一部分表达式事先保存在变量中。例如:
$str="hello worlds junmajinlong";
$pattern="w.*d";
$str =~ /$pattern/;
但这样做缺陷很大,必须要确保插入在正则表达式中的变量pattern中没有存放具有特殊意义的字符。例如,当使用m//格式的正则进行匹配时,不能在变量中保存/,除非转义。
Perl提供了qr/pattern/的功能,它把pattern部分构建成一个正则表达式对象,然后就可以在正则表达式中直接引用这个对象,更方便的是可以将这个对象保存到变量中,通过引用变量的方式来引用这个已保存好的正则对象。
$str="hello worlds junmajinlong";
# 直接作为正则表达式
$str =~ qr/w.*d/;
# 保存为变量,再作为正则表达式
$pattern=qr/w.*d/;
$str =~ $pattern; # (1)
$str =~ /$pattern/; # (2)
# 保存为变量,作为正则表达式的一部分
$pattern=qr/w.*d/;
$str =~ /hel.* $pattern/;
还允许为这个正则对象设置修饰符,比如忽略大小写的匹配修饰符为i,这样在真正匹配的时候,就只有这一部分正则对象会忽略大小写,其余部分仍然区分大小写。
$str="HELLO wORLDs gaoxiaofang";
$pattern=qr/w.*d/i; # 忽略大小写
$str =~ /HEL.* $pattern/; # 匹配成功,$pattern部分忽略大小写
$str =~ /hel.* $pattern/; # 匹配失败
$str =~ /hel.* $pattern/i; # 匹配成功,所有都忽略大小写
小心正则表达式中的特殊符号
正则表达式中使用了很多元字符,这些元字符在正则表达式中有特殊含义。另外,Perl自身也使用了很多特殊符号。如果在正则表达式中使用了两者冲突的特殊符号,就需要特殊处理。
例如,可以在正则表达式中内插变量:
$str =~ /hel.*$pattern/;
但如果是下面这样的正则表达式呢?
$str =~ /abc$\ndef/m;
这里有两种解析方式:
- 将
$\看作变量,等价于/abc${\}ndef/m - 在多行模式下,匹配abc以及下一行def
Perl会默认解析为前者,如果确实想要的是前者,在正则表达式中内插变量,都建议使用${var}的变量引用方式。
如果想要的结果是后者,则可改写为:
$str =~ /abc$(?:)\ndef/m;
即,使用一个空的非捕获分组括号将$符号和\隔开。
更好的方式是将正则表达式部分以单引号的方式定义为变量,然后在正则表达式中内插该变量:
my $re_str = q%abc$\ndef%;
$str =~ /${re_str}/m;
有时候并不是想要将Perl中的特殊字符转义,而是想要将正则表达式中的特殊字符转义。此时可使用反斜线转义元字符,使其被当作普通字面符号。如果要转义的元字符较多,可使用Perl提供的\Q...\E进行强转。但注意,\Q仍然无法转义变量内插。
$sub="world";
$str="hello worlds junmajinlong";
$str =~ /\Q$sub\E/; # $sub会替换,所以匹配成功world
$str =~ /\Q$sub.\E/; # 元字符"."被当做普通的点符号,所以无法匹配
正则匹配返回值和正则相关变量
正则匹配返回值和正则相关变量
Perl正则匹配返回值
正则匹配的返回值情况比较复杂,具体可参考perldoc perlop。大致可总结为:
- 在标量上下文中,正则匹配总是在匹配成功时返回1表示布尔真,匹配失败时返回undef
- 在列表上下文中:
- 匹配失败时,总是返回空列表,表示布尔假
- 匹配成功时,如果使用了小括号分组捕获,则返回本次匹配各分组捕获的内容列表
- 匹配成功时,如果未使用小括号分组捕获,则在未使用
g修饰符时返回列表(1),在使用了g修饰符时返回全局匹配成功的内容列表
例如:
# 在标量上下文,正则匹配可直接作为判断条件
my $str = "abAB12cdCD34";
say "matched" if($str =~ /\d+/);
say "not matched" if($str =~ /xy/);
# 在列表上下文,匹配失败时,返回空列表
my @arr = $str =~ /xy/;
say ~~@arr; # 0
# 在列表上下文,匹配成功,且使用小括号分组捕获时,返回各分组内容
my @arr = $str=~/(\d+)/;
say "@arr"; # 12
@arr = $str=~/(\d+)[^0-9]+(\d+)/;
say "@arr"; # 12 34
# 在列表上下文,匹配成功,且未使用小括号分组捕获时,
# 如果未使用g修饰符全局匹配,则返回列表`(1)`
# 如果使用g修饰符全局匹配,则返回全局匹配成功的内容列表
my @arr1 = $str=~/\d+/;
say "@arr1"; # 1
my @arr2 = $str=~/\d+/g;
say "@arr2"; # 12 34
Perl正则匹配相关变量
Perl提供了一些和正则表达式相关的内置特殊变量,通过这些变量,可以访问某次正则匹配完成之后的一些数据。
例如,Perl正则匹配在标量上下文不会返回匹配成功的内容,但可以通过特殊变量$&来获取匹配到的内容:
my $str = "abAB12cdCD34";
say "matched: $&" if($str =~ /\d+/);
下面是正则表达式相关的特殊变量总结,其中一部分在后面内容涉及到的时候还会解释。
$1 $2 $3...
保存了各个分组捕获的内容
$&
$MATCH
保存了本次匹配到的内容
$`
$PREMATCH
保存了本次匹配起始位置之前的内容
$'
$POSTMATCH
保存了本次匹配结束位置之后的内容
对于$` $& $',它们保存的分别是本次匹配时,匹配内容前的内容、匹配到的内容和匹配内容后的内容。例如,对于正则匹配"aAbBcC"=~/bB/来说,匹配后它们的内容如下所示:
(aA)(bB)(cC)
| | |
$` $& $'
在以前的Perl版本中,使用$` $& $'会有性能问题,每次匹配成功后都会拷贝对应的字符串到这三个变量中,但是从Perl v5.20开始,Perl采用了写时复制(copy-on-write)技术,只有确实使用了这些变量时,才会拷贝对应的字符串保存到这三个变量中,因此不用再担心使用这三个变量时的性能问题。
这些特殊变量是只读的,每次正则匹配时Perl会自动重置这些变量。这些变量只在当前作用域内有效,并且只在本次正则匹配后、下次正则匹配前有效。
$str = "abbc123";
$str=~/a(.*)c/;
say $1;
$str=~/a.*c/;
say $1; # undef
还有几个比较常用的特殊变量是:
$+
$LAST_PAREN_MATCH
最后一个匹配成功的分组括号所匹配的内容(PAREN是括号parentheses的缩写)
%+
%LAST_PAREN_MATCH
保存本次匹配过程中所有命名分组捕获的内容,hash的key是分组名称,value是分组捕获的内容
@-
@LAST_MATCH_START
@+
@LAST_MATCH_END
前两个数组变量保存了各个分组匹配的起始位置。后两个数组变量保存了各个分组匹配的结束位置。
@- @+这两个变量结合substr用起来可以非常强大,通过它们可以构造出和$` $& $'等价的值,且能构造出更多匹配结果。例如:
$` == substr($var, 0, $-[0])
$& == substr($var, $-[0], $+[0] - $-[0])
$' == substr($var, $+[0])
$1 == substr($var, $-[1], $+[1] - $-[1])
$2 == substr($var, $-[2], $+[2] - $-[2])
$3 == substr($var, $-[3], $+[3] - $-[3])
Perl正则模式修饰符
Perl正则模式修饰符
指定模式匹配的修饰符,可以改变正则表达式的匹配行为。例如,下面的i就是一种修饰符,该修饰符让前面的正则REG在匹配时忽略大小写。
m/REG/i
perl总共支持以下几种修饰符:msixpodualngc
i:匹配时忽略大小写g:全局匹配。默认情况下,正则表达式/abc/匹配"abcdabc"的时候,将只匹配左边的abc,使用g将匹配两个abcc:在开启g的情况下,如果匹配失败,将不重置搜索位置m:多行匹配模式s:让.可以匹配换行符\n,也就是说该修饰符让.真的可以匹配任意字符x:允许正则表达式使用空白符号,免得整个表达式难读难懂,但这样会让原本的空白符号失去意义,这时可以使用\s来表示空白o:只编译一次正则表达式n:非捕获模式p:保存匹配的字符串到${^PREMATCH} ${^MATCH} ${^POSTMATCH}中,它们在结果上对应$` $& $'a和u和l:分别表示用ASCII、Unicode和Locale的方式来解释正则表达式d:使用unicode或原生字符集,就像5.12和之前那样,不用考虑这个修饰符
这些修饰符可以连用,连用时顺序可随意。例如下面两行是等价的行为:全局忽略大小写的匹配行为。
m/REG/ig
m/REG/gi
上面的修饰符,本节介绍imsxpo这几个修饰符,gc在后面介绍全局匹配时解释,n修饰符在后面分组捕获的地方解释,auld修饰符和字符集相关,不打算解释。
i修饰符:忽略大小写
该修饰符使得正则匹配的时候,忽略大小写。
my $name="aAbBcC";
if($name =~ m/ab/i){
print "pre match: $` \n"; # 输出a
print "match: $& \n"; # 输出Ab
print "post match: $' \n"; # 输出BcC
}
m修饰符:多行匹配模式
正则表达式一般都只用来匹配单行数据,但有时候却需要一次性匹配多行。比如匹配跨行单词、匹配跨行词组,匹配跨行的对称分隔符(如一对跨行括号)。
使用m修饰符可以开启多行匹配模式。
例如:
my $txt="ab\ncd";
$txt =~ /a.*\nc/m;
say "===match start==="
say $&;
say "===match end===";
执行,将输出:
===match start===
ab
c
===match end===
关于多行匹配,需要注意的是元字符.默认情况下无法匹配换行符。可以使用[\d\D]代替点,也可以开启s修饰符使.能匹配换行符。
例如,下面两个匹配的结果和上面是一致的。
$txt =~ /a.*c/ms;
$txt =~ /a[\d\D]*c/m;
s修饰符
默认情况下,.元字符不能匹配换行符\n,开启了s修饰符功能后,可以让.匹配换行符。正如刚才的那个例子:
my $txt="ab\ncd";
$txt =~ /a.*c/m; # 匹配失败
$txt =~ /a.*c/ms; # 匹配成功
x修饰符
正则表达式最为人所抱怨的就是它的可读性极差,无论你的正则能力有多强,看着一大堆乱七八糟的符号组合在一起,都得一个符号一个符号地从左向右读。
万幸,Perl正则允许分隔表达式,甚至支持注释,只需加上x修饰符即可。这时候正则表达式中出现的所有空白符号都不会当作正则的匹配对象,而是直接被忽略。如果想要匹配空白符号,可以使用\s表示,或者将空格使用\Q...\E包围。
例如,以下4个匹配操作是完全等价的。
my $ans="cat sheep tiger";
$ans =~ /(\w) *(\w) *(\w)/; # 正常情况下的匹配表达式
$ans =~ /(\w)\s* (\w)\s* (\w)/x;
$ans = ~ /
(\w)\s* # 本行是注释:匹配第一个单词
(\w)\s* # 本行是注释:匹配第二个单词
(\w) # 本行是注释:匹配第三个单词
/x;
$ans =~ /
(\w)\Q \E # \Q \E强制将中间的空格当作字面符号被匹配
(\w)\Q \E
(\w)
/x;
对于稍微复杂一些的正则表达式,常常都会使用x修饰符来增强其可读性,最重要的是加上注释。
p修饰符
在Perl v5.20版本之前,通过3个特殊变量$` $& $'保存正则匹配相关的内容时,可能会因为频繁地拷贝字符串使得效率低下。Perl为此提供了一个p修饰符,使得能够使用另外三个等价但不降低性能的变量:
${^PREMATCH} <=> $`
${^MATCH} <=> $&
${^POSTMATCH} <=> $'
在Perl v5.20中及之后的版本,Perl采取了写时复制的技术,使得使用这三个变量的过程中不会降低性能。
o修饰符
正则表达式要能够去匹配字符串,大致需要经过几个过程:
- 正则表达式文本分析
- 编译正则
- 正则引擎使用编译后的正则去匹配字符串
很多时候的正则表达式是固定不变的,比如通过一个正则表达式去循环匹配文件中的行,在循环过程中这个正则不会发生变化。
while(){
print if /^abc\d+$/;
}
为了优化,Perl不会每次都去执行耗时的编译过程,只会在第一次正则匹配的过程中去编译该正则文本,然后将编译后的正则缓存下来,下次将直接使用该正则去执行匹配操作。
在以前古老的Perl版本(Perl v5.6及以前)中,Perl不会自动优化为只编译一次正则表达式,而是每次使用正则匹配的时候都会编译。但是现在,Perl在绝大多数情况下,都会自动优化正则的编译过程。
但某些场景下,正则表达式不是固定不变的,比如正则表达式中使用了变量内插。Perl认为在正则表达式中使用变量,意味着正则表达式可能会是动态的,会发生改变,因此Perl不会去优化这种形式的正则表达式。
while(){
print if /^abc${reg}\d+$/;
}
但如果能够确保正则表达式中的变量不会在未来发生改变,那么可以为该正则表达式加上o修饰符,这将会强制只编译一次正则,并且以后都使用第一次编译后缓存下来的正则。
使用o修饰符的时候,一定要确保内插的变量不会发生改变,否则只编译一次的正则可能会不符合预期。例如:
my $day=qw(Mon Tue Wed Thr Fri Sat Sun)[rand 7];
while(...){
print if /^${day}/o;
}
这里加上修饰符o,将使得变量$day的随机效果失效,在整个while循环过程中,都将使用相同的正则表达式去匹配$_。
范围模式匹配修饰符(?imsx-imsx:pattern)
前文介绍的正则修饰符都是放在m//{FLAG}的FLAG处的,放在这个位置会对整个正则表达式产生影响,所以它的作用范围较宽。例如,m/pattern1 pattern2/i的i修饰符会影响pattern1和pattern2。
Perl允许指定只在一定范围内生效的修饰符,方式是(?imsx:pattern)或(?-imsx:pattern)或(?imsx-imsx:pattern),其中加上-表示去除这个修饰符的影响。这里只列出了imsx,因为这几个最常用,其他的修饰符也一样有效。
例如,对于待匹配字符串"Hello world junmajinlong",使用以下几种模式去匹配的话:
/(?i:hello) world/
表示匹配hello时,可忽略大小写,但匹配world时仍然区分大小写。所以匹配成功/(?ims:hello.)world/
表示可以跨行匹配helloworld,也可以匹配单行的hellosworld,且hello部分忽略大小写。所以匹配成功/(?i:hello (?-i:world) junmajinLONG)/
表示在第二个括号之前,可忽略大小写进行匹配,但第二个括号里指明了去除i的影响,所以对world的匹配会区分大小写,但是对junmajinlong部分的匹配又不区分大小写。所以匹配成功/(?i:hello (?-i:world) junmajin)LONG/和前面的类似,但是将LONG放到了括号外,意味着这部分要区分大小写。所以匹配失败
全局匹配
全局匹配
Perl在默认情况下,匹配一次成功后就会立即退出匹配。例如,对于下面的正则匹配来说:
"abcabc" =~ /ab/
匹配到第一个ab后就结束正则匹配。
如果想要继续匹配第二个ab,就需要进行全局匹配。使用g修饰符可以让正则进入全局匹配工作模式:匹配完第一个ab,继续向后匹配,直到匹配完成功或匹配结束。
当使用了全局修饰符g时,在标量上下文中,正则匹配返回表示匹配成功与否的值,在列表上下文中,如果匹配成功,则返回全局匹配成功的内容列表或小括号分组捕获的内容。
因此,想要查看全局匹配的匹配结果,将其放在列表上下文即可:
my @arr = "abcabc" =~ /ab/g; # 匹配返回qw(ab ab)
say "@arr"; # ab ab
或者,使用循环匹配的方式来验证全局匹配中的每次匹配结果:
my $name="aAbBcCaBc";
while($name =~ m/ab/gi){
say "pre match : $`";
say "match : $&";
say "post match: $'";
}
执行它,将输出如下内容:
pre match : a
match : Ab
post match: BcCaBc
pre match : aAbBcC
match : aB
post match: c
在开启了g全局匹配后,perl会在每次匹配成功后记下匹配的偏移位置,以便下次匹配时可以从该位移处继续向后匹配。每次匹配成功后的位移值,都可以通过pos()函数获取。偏移值从0开始算,0位移代表的是第一个字符左边的位置。如果本次匹配导致位移指针重置,pos将返回undef。
my $name="123ab456";
$name =~ m/\d\d/g; # 第一次匹配,匹配成功后记下位移
say "matched: $&, pos: ",pos $name;
$name =~ m/\d\d/g; # 第二次匹配,匹配成功后记下位移
say "matched: $&, pos: ",pos $name;
执行它,将输出如下内容:
matched: 12, pos: 2
matched: 45, pos: 7
匹配失败的时候,正则匹配操作会返回假,所以可以作为if或while等的条件语句来终止全局匹配。例如:
my $name="123ab456";
while($name =~ m/\d\d/g){
say "matched: $&, pos: ",pos $name;
}
c修饰符
默认全局匹配情况下,当本次匹配失败,便宜指针将重置到起始位置0处,也就是说,下次匹配将从头开始匹配。例如:
my $txt="1234a56";
$txt =~ /\d\d/g; # 匹配成功:12,位移向后移两位
say "matched $&: ",pos $txt;
$txt =~ /\d\d/g; # 匹配成功:34,位移向后移两位
say "matched $&: ",pos $txt;
$txt =~ /\d\d\d/g; # 匹配失败,位移指针回到0处,pos()返回undef
say "matched $&: ",pos $txt;
$txt =~ /\d/g; # 匹配成功:1,位移向后移1位
say "matched $&: ",pos $txt;
执行上述程序,将输出:
matched 12: 2
matched 34: 4
matched 34: #<-- warning: use undef value
matched 1: 1
如果g修饰符下同时使用c修饰符,也就是gc,它表示全局匹配失败的时候不重置位移指针。也就是说,本次匹配失败后,位移指针会卡在原处不动,下次匹配将从这个位置处开始匹配。
my $txt="1234a56";
$txt =~ /\d\d/g;
say "matched $&: ",pos $txt;
$txt =~ /\d\d/g;
say "matched $&: ",pos $txt;
$txt =~ /\d\d\d/gc; # 匹配失败,$&和pos()保留上一次匹配成功的内容
say "matched $&: ",pos $txt;
$txt =~ /\d/g; # 匹配成功:5
say "matched $&: ",pos $txt;
$txt =~ /\d/g; # 匹配成功:6
say "matched $&: ",pos $txt;
$txt =~ /\d/gc; # 匹配失败
say "matched $&: ",pos $txt;
执行上述程序,将输出:
matched 12: 2
matched 34: 4
matched 34: 4
matched 5: 6
matched 6: 7
matched 6: 7
\G反斜线序列
如果上面第三个匹配语句不是/\d\d\d/gc,而是/\d/g,它匹配字母a的时候也失败,但是最终它会匹配成功。因为,它会继续先后匹配,直到匹配成功或匹配结束。
my $txt="1234ab56";
$txt =~ /\d\d/g;
say "matched $&: ",pos $txt;
$txt =~ /\d\d/g;
say "matched $&: ",pos $txt;
$txt =~ /\d/g; # 字母a匹配失败,后移一位,字母b匹配失败,后移一位,数值5匹配成功
say "matched $&: ",pos $txt;
$txt =~ /\d/g; # 数值6匹配成功
say "matched $&: ",pos $txt;
执行上述程序,将输出:
matched 12: 2
matched 34: 4
matched 5: 7
matched 6: 8
实际上,全局匹配时,默认情况下,如果当前字符匹配失败,将会后移继续去匹配,直到匹配成功或匹配结束。
可以指定\G,使得本次匹配强制从位移处进行匹配,不允许跳过任何匹配失败的字符。
- 如果本次
\G全局匹配成功,位移指针后移到匹配终止的位置 - 如果本次
\G全局匹配失败,且没有加上c修饰符,那么位移指针将重置 - 如果本次
\G全局匹配失败,且加上了c修饰符,那么位移指针将卡着不动
例如:
my $txt="1234ab56";
$txt =~ /\d\d/g;
say "matched $&: ",pos $txt;
$txt =~ /\d\d/g;
say "matched $&: ",pos $txt;
$txt =~ /\G\d/g; # 强制从位移4开始匹配,无法匹配字母a,但又不允许跳过
# 所以本次\G全局匹配失败,由于没有修饰符c,指针重置
say "matched $&: ",pos $txt;
$txt =~ /\G\d/g; # 指针回到0,强制从0处开始匹配,数值1能匹配成功
say "matched $&: ",pos $txt;
以下是输出内容:
matched 12: 2
matched 34: 4
matched 34: #<-- warning: use undef value
matched 1: 1
如果将上面第三个匹配语句加上修饰符c,甚至后面的语句也都加上\G和c修饰符,那么位移指针将卡在那个位置:
my $txt="1234ab56";
$txt =~ /\d\d/g;
say "matched $&: ",pos $txt;
$txt =~ /\d\d/g;
say "matched $&: ",pos $txt;
$txt =~ /\G\d/gc; # 匹配失败,指针卡在原地
say "matched $&: ",pos $txt;
$txt =~ /\G\d/gc; # 匹配失败,指针继续卡在原地
say "matched $&: ",pos $txt;
$txt =~ /\Gab/gc; # 匹配成功,指针后移两位
say "matched $&: ",pos $txt;
以下是输出结果:
matched 12: 2
matched 34: 4
matched 34: 4
matched 34: 4
matched ab: 6
一般来说,全局匹配都会用循环去多次迭代,和上面一次一次列出匹配表达式不一样。所以,下面使用while循环的例子来对\G和c修饰符稍作解释,其实理解了上面的内容,在循环中使用\G和c修饰符也一样很容易理解。
my $txt="1234ab56";
while($txt =~ m/\G\d\d/gc){
say "matched: $&, ",pos $txt;
}
执行结果:
matched: 12, 2
matched: 34, 4
当第三轮循环匹配到a字母的时候,由于使用了\G,导致匹配失败,结束循环。
上面使用c与否是无关紧要的,但如果这个while循环的后面后还有对$txt的匹配,那么使用c修饰符与否就有关系了。例如下面两段程序,返回结果不一样:
## 第一段匹配
## ----------------
my $txt1="1234ab56";
# 使用c修饰符,第二轮匹配完成后位移指针卡住,pos=4
while($txt1 =~ m/\G\d\d/gc){
say "matched: $&, ",pos $txt1;
}
# 从卡住的地方继续匹配,匹配失败,继续卡住,pos=4
$txt1 =~ m/\d\d/gc;
say "matched: $&, ",pos $txt1;
## 第二段匹配
## ----------------
# 不使用c修饰符,第二轮匹配完成后位移指针重置,pos=0
my $txt2="1234ab56";
while($txt2 =~ m/\G\d\d/g){ # 不使用c修饰符
say "matched: $&, ",pos $txt2;
}
# 从头开匹配配,匹配成功,pos=2
$txt2 =~ m/\G\d\d/gc;
say "matched: $&, ",pos $txt2;
Perl正则支持的反斜线序列
Perl正则支持的反斜线序列
大致可分为三类反斜线序列:位置锚定反斜线序列、字符匹配反斜线序列、分组捕获相关的反斜线序列。
位置锚定反斜线序列
所谓锚定,就是【零宽断言(zero-width assertions)】,是指它匹配的是位置,而非字符。比如锚定行首的意思是匹配第一个字母前的空字符。
下面列出了Perl支持的位置锚定反斜线序列:
\b:匹配单词边界处的空字符\B:匹配非单词边界处的空字符\<:匹配单词开头处的空字符\>:匹配单词结尾处的空字符\A:匹配绝对行首,换句话说,就是输入内容的开头\z:匹配绝对行尾,换句话说,就是输入内容的绝对尾部\Z:匹配绝对行尾或绝对行尾换行符前的位置,换句话说,就是输入内容的尾部\G:强制从位移指针处进行匹配
主要解释下\A \z \Z,\G留在后面全局匹配时解释,其余的则属于基础正则的内容,不多做解释。
\A \z \Z和^ $的区别主要体现在多行模式下。在多行模式下:

例如:
my $txt = "abcd\nABCD\n";
$txt =~ /^ABC*/; # 无法匹配
$txt =~ /^ABC*/m; # 匹配
$txt =~ /\Aabc/; # 匹配
$txt =~ /\Aabc/m; # 匹配
$txt =~ /\AABC/m; # 无法匹配
$txt =~ /cd\n$/m; # 不匹配
$txt =~ /cd$\n/m; # 该正则是错的,$\被解析变量,即等价于/cd${\}n/m
$txt =~ //cd$(?:)\n/m; # 匹配
$txt =~ /cd$/m; # 匹配
$txt =~ /CD\Z\n/m # 匹配
$txt =~ /CD\Z\n\Z/m; # 匹配
$txt =~ /CD\n\z/m; # 匹配
my $txt1 = "abcd\nABCD";
$txt1 =~ /CD\Z/m; # 匹配
$txt1 =~ /CD\z/m; # 匹配
字符匹配反斜线序列
以下是一些常用的反斜线字符序列。除了以下这几种,还有一些用的不多的反斜线序列\v \V \h \H \R \p \c \X,这些不会在此解释。
\w:匹配单词构成部分,等价于[_[:alnum:]]\W:匹配非单词构成部分,等价于[^_[:alnum:]]\s:匹配空白字符,等价于[[:space:]]\S:匹配非空白字符,等价于[^[:space:]]\d:匹配数字,等价于[0-9]\D:匹配非数字,等价于[^0-9]\N:不匹配换行符,等价于[^\n]
由于元字符.默认无法匹配换行符,但可以使用特殊组合[\d\D]或者(\n|\N)来替换.,它们能匹配换行符。换句话说,如果想匹配任意长度的任意字符,可以将.*换成[\d\D]*或(\n|\N)*。之所以不用[\n\N],是因为\N有特殊意义,不能随意接符号和字母。
分组捕获的反斜线序列
\1:反向引用,其中1可以替换为任意一个正整数,即使超出9,例如\111表示匹配第111个分组\g1或\g{1}:也是反向引用,只不过这种写法可以避免歧义,例如\g{1}11表示匹配第一个分组内容后两个数字1\g{-1}:还可以使用负数,表示距离\g左边的分组号,也就是相对距离。例如(abc)([a-z])\g{-1}中的\g引用的是[a-z],如果-1换成-2,则引用的abc\g{name}:引用已命名的分组(命名捕获),其中name为分组的名称\k<name>:同上,引用已命名的分组(命名捕获),其中name为分组的名称\K:丢弃\K左边的内容。换句话说,要求匹配\K左边的内容成功,但却不包含在匹配结果中
此处暂时还没介绍到命名分组,所以\g{name}和\k<name>留在后面再介绍。
\K表示强制丢弃前面已完成的匹配。例如
"abc22ABC" =~ /abc\K2.*/;
abc三个字母先被匹配,如果没有\K,这3个字母将放进$&中,但是\K使得匹配完abc后立即丢弃前面的匹配,所以这个正则表达式的匹配结果是22ABC。
再例如:
"abc123abcfoo"=~ /(abc)123\K\g1foo/;
它匹配到123后被切断,但是分组引用还可以继续引用,所以匹配的结果是abcfoo。
所以,使用\K可以做左侧条件判断(类似于逆向环视锚定):要求成功匹配\K左边的部分,但不要它们。
贪婪匹配、非贪婪匹配、占有优先匹配
贪婪匹配、非贪婪匹配、占有优先匹配
在基础正则中,那些能匹配多次的量词默认都会匹配最长内容。这种尽量多匹配的行为称为【贪婪匹配】(greedy match)。
例如:
"aa1122ccbb" =~ /a.*c/;
上面正则中的.*将直接从第二个字母a开始匹配到最结尾的b,因为从第二个字母a开始到最后一个字母b都符合.*的匹配模式。再然后,去匹配字母c,但因为已经把所有字母匹配完了,只能一个字符一个字符地回退释放,每释放一个字符就匹配一次字母c,发现回退释放到倒数第三个字符c就能满足匹配要求,于是这里的.*最终匹配的内容是a1122c。
上面涉及到回溯的概念,表示将那些已经被匹配的内容回退释放。
上面描述的是贪婪匹配行为,还有非贪婪匹配、占有优先匹配。简单描述下:
- 非贪婪匹配:(lazy match)尽可能少地匹配,也叫做懒惰匹配
- 占有优先匹配:(possessive)只要占有就不再交还回溯
有必要搞清楚这几种匹配模式在匹配机制上的区别:
- 贪婪匹配:对于那些量词,将一次性从左到右匹配到最大长度,然后再往回回溯释放
- 非贪婪匹配:对于那些量词,将从左向右逐字符匹配最短长度,然后直接结束这次的量词匹配行为
- 占有优先匹配:先按照贪婪模式匹配,匹配后就【锁】住已匹配内容,不允许进行回溯
贪婪匹配模式、非贪婪匹配模式和占有优先匹配模式对应的量词元字符如下:
(量词后加上?) (量词后加上+)
贪婪匹配量词 非贪婪匹配量词 占有优先匹配量词
------------------------------------------------------
* *? *+
? ?? ?+
+ +? ++
{M,} {M,}? {M,}+
{M,N} {M,N}? {M,N}+
{N} {N}? {N}+
几点需要说明:
- 非贪婪匹配时,
{M,}?和{M,N}?等价,因为最多只匹配M次 - Perl不支持
{,N}的量词模式,所以也没有对应的非贪婪和占有优先匹配模式 - 由于
{N}是精确匹配N次的量词,所以贪婪与否对最终结果无关紧要,但是却影响匹配时的行为:贪婪匹配最长,需要回溯,非贪婪匹配最短,不回溯,占有优先匹配最长不回溯
看以下示例即可理解贪婪和非贪婪匹配的行为:
my $str="abc123abc1234";
# greedy match
if( $str =~ /(a\w*3)/){
say "$&"; # abc123abc123
}
# lazy match
if( $str =~ /(a\w*?3)/){
say "$&"; # abc123
}
占有优先匹配模式示例:
my $str="abc123abc1234";
if( $str =~ /a\w*+/){ # 成功
say "possessive1: $&";
}
if( $str =~ /a\w*+3/){ # 失败
say "possesive2: $&";
}
从上面第二个示例可知,使用占有优先匹配模式时,它后面不应该跟其他正则表达式,例如a*+x永远匹配不了东西。
分组捕获和分组引用
分组捕获和分组引用
在基础正则中,使用括号可以对匹配的内容进行分组,这种行为称为分组捕获。捕获后可以通过\1这种反向引用方式去引用(访问)保存在分组中的匹配结果。
例如:
"abc11ddabc11" =~ /([a-z]*)([0-9]*)dd\1\2/;
在Perl中,还可以使用\gN的方式来反向引用分组。例如,和上面等价的几种写法:
"abc11ddabc11" =~ /([a-z]*)([0-9]*)dd\g1\g2/;
"abc11ddabc11" =~ /([a-z]*)([0-9]*)dd\g{1}\g{2}/;
"abc11ddabc11" =~ /([a-z]*)([0-9]*)dd\g{-2}\g{-1}/;
Perl还会把分组的内容放进Perl自带的特殊变量$1,$2,...,$N中,它们和\1,\2,...\N在匹配成功时的结果上没有区别,但是:
- 反向引用
\N可在正则表达式中使用,且只在正则匹配中有效,正则匹配结束后就消亡了 - 分组变量
$N不能在正则表达式中使用,它是Perl变量,在本次正则匹配结束后、下次正则匹配前可用
所以,可以使用$N的方式来输出分组匹配的结果:
"abc11ddabc11" =~ /([a-z]*)([0-9]*)dd\1\2/;
say "first group: $1";
say "second group: $2";
有几点需要注意:
- 分组可能未捕获任何内容(比如那些允许匹配0次的量词),但整个匹配是成功的。这时
$N引用分组时,得到的结果将是空串 - 每次正则匹配都重置
$N,因此$N在下一次正则匹配之前一直有效
例如:
# 分组没有捕获内容,但匹配是成功的,$1是空串
"abcde" =~ /([0-9]*)de/;
say "empty group: $1";
# 分组捕获到数值4,$1保存了4,
# 但下次正则匹配后,将重置$1
"abc4de" =~ /([0-9]*)de/;
say "group: $1"; # 4
"abcde" =~ /([0-9]*)de/;
say "empty group: $1"; # 空串
Perl更强大的分组捕获
Perl正则除了支持普通分组(也就是直接用括号的分组),还支持:
- 命名分组
(?<NAME>...):捕获后放进一个名为NAME的分组,正则表达式中可使用该名称来反向引用该分组内容,如\g{NAME} - 匿名分组
(?:...):仅分组,不捕获,所以后面无法再引用这个捕获 - 固化分组
(?>...):一匹配成功就永不交还内容
匿名分组
匿名捕获是指仅分组,不捕获。因为不捕获,所以无法使用反向引用,也不会将分组结果赋值给$1这种特殊变量。
例如:
my $str = "xiaofang or longshuai";
if ($str =~ /(\w+) or (\w+)/){
say "name1: $1, name2: $2";
}
但如果中间的or也可以换成and,为了同时满足and和or两种需求,使用模式/(\w+) (and|or) (\w+)/去匹配,但这时引用的序号就得由$2变为$3:
my $str = "xiaofang or longshuai";
if ($str =~ /(\w+) (or|and) (\w+)/){
say "name1: $1, name2: $3";
}
可使用匿名分组解决这样的问题:
my $str = "xiaofang or longshuai";
if ($str =~ /(\w+) (?:or|and) (\w+)/){
say "name1: $1, name2: $2";
}
另外,Perl有一个n修饰符,它使得普通分组变成匿名分组,但对命名分组无效。且因为它是修饰符,它会使修饰范围内的所有普通分组都变成匿名分组。
my $str = "xiaofang or longshuai";
# 等价于:
# if ($str =~ /(?:\w+) (?:or|and) (?:\w+)/n){
if ($str =~ /(\w+) (or|and) (\w+)/n){
say "name1: $1, name2: $2"; # 错,$1 $2不可用
}
命名分组
命名分组是指将捕获到的内容放进分组,这个分组是有名称的分组,后面可以使用分组名去引用已捕获进这个分组的内容。除此之外,和普通分组并无区别。
当要进行命名分组时,使用(?<NAME>)的方式替代普通分组的括号()即可。例如,要匹配abc并将其分组,以前普通分组的方式是(abc),如果将其放进命名为name1的分组中:(?<name1>abc)。
当使用命名捕获的时候,要在正则内部引用这个命名捕获,除了可以使用序号类的绝对引用(如\1或\g1或\g{1}),还可以使用以下任意一种按名称的引用方式:\g{NAME} \k{NAME} \k<NAME> \k'NAME'。
如果要在正则外部引用这个命名捕获,除了可以使用序号类的绝对应用(如$1),还可以使用$+{NAME}的方式。可使用后一种引用方式的原因是,Perl将命名捕获的内容放进了一个名为%+的特殊hash中。
例如:
my $str = "ma xiaofang or ma longshuai";
if ($str =~ /
(?<firstname>\w+)\s # firstname -> ma
(?<name1>\w+)\s # name1 -> xiaofang
(?:or|and)\s # group only, no capture
\g1\s # \g1 -> ma
(?<name2>\w+) # name2 -> longshuai
/x){
say "$1";
say "$2";
say "$3 ";
# 或者指定名称来引用
say "$+{firstname}\n$+{name1}\n$+{name2}";
}
固化分组
固化分组的用法是(?>PATTERN),它会将PATTERN匹配的内容吞掉且绝不交还,相当于是将其匹配的内容进行固化。它和占有优先匹配模式在行为上是类似的:占有之后不回溯。
另外,固化分组不是一种分组,因此无法去引用它吞掉的内容。
例如"hello world"可以被hel.* world成功匹配,但不能被hel(?>.*) world匹配。因为固化分组时,.*匹配后面所有内容并将其吞掉,这些内容一经匹配绝不交回。
但如果正则表达式是hel(?>.* world)将能匹配成功,即将原来分组外面的内容放进了分组内部。固化分组的内部是允许回溯的。
再例如:
my $str="ma longshuai gao xiaofang";
if($str =~ /ma (?>long.*)/){ # 成功
say "matched";
}
if($str =~ /ma (?>long.*)gao/){ # 失败
say "matched";
}
if($str =~ /ma (?>long.*gao)/){ # 成功
say "matche";
}
if($str =~ /ma (?>long.*g)ao/){ # 成功
say "matched";
}
环视锚定
环视锚定(断言)
环视(lookaround)是一种锚定匹配,即匹配的是位置,而不是字符。
(?=...):表示从左向右的顺序环视。如(?=\d)表示当前字符的右边是一个数字时就满足条件(?!...):表示顺序环视的否定。如(?!\d)表示当前字符的右边不是一个数字时就满足条件(?<=...):表示从右向左的逆序环视。如(?<=\d)表示当前字符的左边是一个数字时就满足条件(?<!)...:表示逆序环视的取反。如(?<!\d)表示当前字符的左边不是一个数字时就满足条件
一定要主要,环视锚定匹配的是位置,而不是字符,它不会消耗任何字符。
例如"your name is longshuai MA"和"your name is longfei MA",使用(?=longshuai)将能锚定第一个句子中单词longshuai前面的位置(即空格和字母l中间的位置),所以(?=longshuai)long才能long这几个字符。仅对于此处的两个句子,long(?=shuai)和(?=longshuai)long是等价的。
一般为了方便理解,在顺序环视的时候会将匹配内容放在锚定括号的左边(如long(?=longshuai)),在逆序环视的时候会将匹配的内容放在锚定括号的右边(如(?<=long)shuai)。
例如:
my $str="abc123abcc12c34";
# 顺序环视
$str =~ /a.*c(?=\d)/; # abc123abcc12c
say "$&";
# 顺序否定环视
$str =~ /a.*c(?!\d)/; # abc123abc
say "$&";
# 逆序环视
$str =~ /a.*(?<=\d)c/; # abc123abcc12c
say "$&";
# 逆序否定环视
$str =~ /a.*(?<!\d)c/; # abc123abcc
say "$&";
逆序环视的表达式必须只能表示固定长度的字符串。例如(?<=word)或(?<=word|word)可以,但(?<=word?)不可以,因为?匹配0或1长度,长度不定,它无法对左边是word还是wordx做正确判断。
my $str="hello worlds Gaoxiaofang";
$str =~ /he.*(?<=worlds?) Gao/; # 报错
$str =~ /he.*(?<=worlds|world) Gao/; # 报错
在PCRE中,这种变长的逆序环视锚定可重写为(?<=word|words),但Perl中不允许,因为Perl严格要求长度必须固定。
通过\K可以在一定程度上解决这样的问题:
my $str="hello worlds Gaoxiaofang";
$str =~ /he.*worlds?\K Gao/;
$str =~ /he.*(worlds|world)\K Gao/;
否定分组
否定分组
否定分组是一种位置锚定技巧,而不是一种正则语法。它的用法为((?!xxx).),用于取代匹配任意字符的.,其外层括号的主要目的是将(?!xxx)和.组合在一起。
例如(?:(?!xxx).)*在作用上表示右边不能是xxx,然后再匹配任意单个字符。其效果等价于匹配任意单个字符,直到右边是xxx的字符,且不要求xxx必须存在,即类似于.*(?!xxx).。
例如"abcat" =~ /(?:(?!cat).)*/,它的匹配过程如下:
- 首先锚定起始位置(a的左边),其右边不是cat,于是吞掉一个字符a
- 进行下一轮匹配,锚定a后面的位置(a右边b左边),其右边不是cat,于是吞掉字符b
- 再锚定b后面的位置,其右边是cat,锚定失败,于是本轮匹配失败,但注意,b在上轮匹配中已经被吞掉
- 所以最终匹配的结果是ab,因此
/(?:(?!cat).)/相当于匹配任意单个字符,直到右边是cat字符
否定分组常常需要结合其他位置锚定一起使用才能有比较好的效果。
比如分析下面几个匹配的匹配结果:
# 匹配cat前的所有字符
'fox,cat,dog,parrot' =~ /\A((?!cat).)*/;
#=> "fox,"
# 匹配parrot前的所有字符
'fox,cat,dog,parrot' =~ /\A((?!parrot).)*/;
#=> "fox,cat,dog,"
# 匹配pig前的所有字符
'fox,cat,dog,parrot' =~ /\A((?!pig).)*/;
#=> "fox,cat,dog,parrot"
# 匹配连续重复字符前的所有字符
'fox,cat,dog,parrot' =~ /\A(?:(?!(.)\1).)*/;
#=> "fox,cat,dog,pa"
# cat((?!do).)*匹配从cat开始直到do前面的一个字符,即"cat,"
# 然后还要紧跟着匹配par
'fox,cat,dog,parrot' =~ /cat((?!do).)*par/;
#=> undef
除了上述技巧,否定分组还常用于如下匹配需求:
- (1).左边任意位置(相邻或不相邻)不能有某字符(串)
- (2).右边任意位置不能有某字符(串)
即类似于环视锚定的需求。需求(2)完全可以使用正向环视锚定来匹配,而需求(1)不一定能通过逆向环视锚定来匹配,因为逆向环视锚定要求字符数量是固定的。\K能实现变长字符的逆向环视锚定,但\K会丢弃匹配结果。
因此,否定分组一般只用于实现需求(1),且不丢弃匹配结果。
例如,想要匹配dog左边没有cat的字符串:
# 匹配失败
# \A((?!cat).)*匹配cat前任意长度的字符,然后紧跟着要匹配dog
'fox,cat,dog,parrot' =~ /\A((?!cat).)*dog/;
# 匹配成功
# 只有当pig不在dog左边时,才能匹配成功
'fox,cat,dog,parrot' =~ /\A((?!pig).)*dog/;
正则引用: qr构建正则对象
正则引用: qr构建正则对象
可以在正则模式中使用变量替换,所以可以将正则中的一部分表达式先保存在变量中,然后插入到正则表达式中。例如:
my $str="hello worlds malong";
my $pattern="w.*d";
$str =~ /$pattern/;
say "$&";
但这样很容易出现问题:保存正则表达式的变量中存放特殊字符时要进行转义处理。例如,当使用m//的方式做匹配分隔符时,不能在变量中保存/,它需要先转义。
Perl提供了qr/pattern/的功能,它把pattern部分构建成一个正则表达式对象(也称为正则引用),这使得构建复杂的正则表达式变得非常方便:
- 在正则表达式中可以直接引用这个对象
- 可以将这个对象保存到变量中,通过引用变量的方式来引用这个已保存好的正则对象
- 将正则对象变量插入到其它正则模式中来构建更复杂的正则表达式
其中:
qr//的斜线可以替换为其它符号,例如qr() qr{} qr<> qr[] qr%% qr## qr!! qr$$ qr"" qr''等- 使用单引号时比较特殊(即
qr''),它会使用单引号的语义去解析pattern部分。例如变量$var无法解析为变量的值,但这样可以使得正则表达式的元字符仍然起作用,例如$仍然表示行尾
my $str="hello worlds malong";
# 直接作为正则表达式
$str =~ qr/w.*d/;
say "$&";
# 保存为变量,再作为正则表达式
my $pattern=qr/w.*d/;
$str =~ $pattern; # (1)
$str =~ /$pattern/; # (2)
say "$&";
# 保存为变量,作为正则表达式的一部分
$pattern=qr/w.*d/;
$str =~ /hel.* $pattern/;
say "$&";
还允许为这个正则对象设置修饰符,比如忽略大小写的匹配修饰符为i,这样在真正匹配的时候,就只有这一部分正则对象会忽略大小写,其余部分仍然区分大小写。
my $str="HELLO wORLDs malong";
my $pattern=qr/w.*d/i; # 忽略大小写
$str =~ /HEL.* $pattern/; # 匹配成功,$pattern部分忽略大小写
$str =~ /hel.* $pattern/; # 匹配失败
$str =~ /hel.* $pattern/i; # 匹配成功,所有都忽略大小写
qr如何构建正则对象
可以输出查看qr构建的正则引用,从而了解qr构建的正则对象是怎样的结构:
my $patt1=qr/w.*d/;
say "$patt1";
my $patt2=qr/w.*d/i; # 加上修饰符i
say "$patt2";
my $patt3=qr/w.*d/img; # 加上修饰符img
say "$patt3";
输出结果:
(?^:w.*d)
(?^i:w.*d)
(?^mi:w.*d)
qr的作用实际上就是在给定的正则pattern基础上加上(?^:)并带上一些修饰符,得到的结果总是(?^FLAGS:pattern)。
但是上面patt3的修饰符g不见了。要知道其原因,需要了解(?^:)的作用:非捕获分组,并重置修饰符。重置为哪些修饰符?对于(?^FLAGS:)来说,只有这些修饰符alupimsx是可用的,即(?^alupimsx:):
- 如果给定的修饰符不在这些修饰符内,则不被识别,有时候会报错
- 如果给定的修饰符属于这几个修饰符,那么没有给定的修饰符部分将采用默认值(不同版本可能默认是否开启的值不同)
所以上面的g修饰符被丢弃了,甚至在进一步操作这个正则引用时,会报错。
由于qr构建正则表达式对象的时候给pattern部分加上了(?^:),使得它们插入到其它正则中的时候,能保证这一段正则子表达式是独立的,不受全局修饰符影响。
my $patt1=qr/w.*d/im;
my $patt2=qr/hel.*d $patt1/i;
say "$patt2"; # 输出:(?^i:hel.*d (?^mi:w.*d))
正则对象作为标量的用法
qr//创建的正则对象引用是一个标量,可以使用标量的地方,就可以使用正则对象。例如,放进hash结构、放进数组结构、作为参数传递给函数、作为函数返回值被返回,等等。
例如,放进数组中形成一个正则表达式列表,然后给定一个待匹配目标,依次用列表中的这些模式去匹配。
use v5.10.1;
my @patterns = (
qr/(?:Willie )?Gilligan/,
qr/Mary Ann/,
qr/Ginger/,
qr/(?:The )?Professor/,
qr/Skipper/,
qr/Mrs?. Howell/,
);
my $name = 'Ginger';
foreach my $pattern ( @patterns ) {
if( $name =~ /$pattern/ ) {
say "Match!";
print "$pattern";
last;
}
}
还可以将这些正则对象放进hash中,为每个pattern都使用key来标识,例如:
use v5.10.1;
my %patterns = (
Gilligan => qr/(?:Willie )?Gilligan/,
'Mary Ann' => qr/Mary Ann/,
Ginger => qr/Ginger/,
Professor => qr/(?:The )?Professor/,
Skipper => qr/Skipper/,
'A Howell' => qr/Mrs?. Howell/,
);
my $name = 'Ginger';
my( $match ) = grep { $name =~ $patterns{$_} } keys %patterns;
say "Matched $match" if $match;
构建复杂的正则表达式
有了qr,就可以将正则表达式细化成简单的子表达式,然后将它们组合起来形成复杂的正则表达式。例如:
my $howells = qr/Thurston|Mrs/;
my $tagalongs = qr/Ginger|Mary Ann/;
my $passengers = qr/$howells|$tagalongs/;
my $crew = qr/Gilligan|Skipper/;
my $everyone = qr/$crew|$passengers/;
就像RFC 1738中对URL各个部分的解剖,如果转换成Perl正则,大概是这样的:
# 可复用的基本符号类
my $alpha = qr/[a-z]/;
my $digit = qr/\d/;
my $alphadigit = qr/(?i:$alpha|$digit)/;
my $safe = qr/[\$_.+-]/;
my $extra = qr/[!*'\(\),]/;
my $national = qr/[{}|\\^~\[\]`]/;
my $reserved = qr|[;/?:@&=]|;
my $hex = qr/(?i:$digit|[A-F])/;
my $escape = qr/%$hex$hex/;
my $unreserved = qr/$alpha|$digit|$safe|$extra/;
my $uchar = qr/$unreserved|$escape/;
my $xchar = qr/$unreserved|$reserved|$escape/;
my $ucharplus = qr/(?:$uchar|[;?&=])*/;
my $digits = qr/(?:$digit){1,}/;
# 可复用的URL组成元素
my $hsegment = $ucharplus;
my $hpath = qr|$hsegment(?:/$hsegment)*|;
my $search = $ucharplus;
my $scheme = qr|(?i:https?://)|;
my $port = qr/$digits/;
my $password = $ucharplus;
my $user = $ucharplus;
my $toplevel = qr/$alpha|$alpha(?:$alphadigit|-)*$alphadigit/;
my $domainlabel = qr/$alphadigit|$alphadigit(?:$alphadigit|-)*$alphadigit/x;
my $hostname = qr/(?:$domainlabel\.)*$toplevel/;
my $hostnumber = qr/$digits\.$digits\.$digits\.$digits/;
my $host = qr/$hostname|$hostnumber/;
my $hostport = qr/$host(?::$port)?/;
my $login = qr/(?:$user(?::$password)\@)?/;
my $urlpath = qr/(?:(?:$xchar)*)/;
然后就可以用上面看上去无比复杂的正则表达式去匹配一个路径是否是合格的http url:
use v5.10.1;
my $httpurl = qr|$scheme$hostport(?:/$hpath(?:\?$search)?)?|;
say "yes" if /$httpurl/;
正则表达式模块
虽然qr为构建复杂正则表达式提供了比较友好的方式,但很多正则表达式本身就是复杂的。实际上,很多常用且复杂的正则表达式已经被别人造好了轮子,我们可以直接拿来用。例如,Regexp::Common模块,提供了很多种已经构建好的正则表达式。
首先安装这个模块:
sudo cpan -i Regexp::Common
以下是CPAN上提供的Regexp::Common已造好的轮子,可参考:https://metacpan.org/release/Regexp-Common。
Regexp::Common - Provide commonly requested regular expressions
Regexp::Common::CC - provide patterns for credit card numbers.
Regexp::Common::SEN - provide regexes for Social-Economical Numbers.
Regexp::Common::URI - provide patterns for URIs.
......
Regexp::Common::comment - provide regexes for comments.
Regexp::Common::delimited - provides a regex for delimited strings
Regexp::Common::lingua - provide regexes for language related stuff.
Regexp::Common::list - provide regexes for lists
Regexp::Common::net - provide regexes for IPv4, IPv6, and MAC addresses.
Regexp::Common::number - provide regexes for numbers
Regexp::Common::profanity - provide regexes for profanity
Regexp::Common::whitespace - provides a regex for leading or trailing whitescape
Regexp::Common::zip - provide regexes for postal codes.
这些正则表达式是通过hash进行嵌套的,最外层hash的名称为%RE。
以模块Regexp::Common::URI::http为例,它提供的是HTTP URI的正则表达式,它嵌套了两层,第一层的key为URI,这个key对应的值是第二层hash,第二层hash的key为HTTP,于是可以通过$RE{URI}{HTTP}的方式获取这个正则。
例如,匹配一个http url是否合理:
use Regexp::Common qw(URI);
say "yes" if /$RE{URI}{HTTP}/;
再例如,从Regexp::Common::net中可以获取匹配IPV4的正则表达式:
use Regexp::Common qw(net);
my $ipv4=$RE{net}{IPv4};
say $ipv4;
以下是结果(为美化排版,下面将一行结果分成了多行显示):
(?:
(?:25[0-5]|2[0-4][0-9]|[0-1]?[0-9]{1,2})
[.]
(?:25[0-5]|2[0-4][0-9]|[0-1]?[0-9]{1,2})
[.]
(?:25[0-5]|2[0-4][0-9]|[0-1]?[0-9]{1,2})
[.]
(?:25[0-5]|2[0-4][0-9]|[0-1]?[0-9]{1,2})
)
需要注意的是,在真正匹配的时候,应该将获取到的正则引用配合锚定一起使用,否则对318.99.183.11进行匹配的时候也会返回true,因为18.99.183.11是符合匹配结果的。所以,对前后都加上锚定,例如:
$ipv4 =~ /^$RE{net}{IPv4}$/;
可以将上面的ipv4正则改造一下(去掉非捕获分组的功能),让它适用于shell工具中普遍支持的扩展正则(为了美化排版,将一行结果分成多行显示):
(25[0-5]|2[0-4][0-9]|[0-1]?[0-9]{1,2})
(\.
(25[0-5]|2[0-4][0-9]|[0-1]?[0-9]{1,2})
){3}
默认情况下,Regexp::Common的各个模块没有开启捕获功能。如果要使用$1 $N这种变量,需要使用{-keep}选项,至于每个分组捕获的是什么内容,需要参考帮助文档的说明。
例如:
use Regexp::Common qw(number);
say $1 if /$RE{num}{int}{ -base => 16 }{-keep}/;
字符串替换:s///
字符串替换:s///
m//模式用来匹配文本,即用于搜索。Perl还支持和sed类似的s///用法,它用来查找并替换文本。
$str =~ s/PATTERN/Replacement/FLAGS;
它表示用指定的正则表达式PATTERN去搜索$str中的内容,并将搜索出来的内容替换为Replacement。
FLAGS指定s替换时的行为,m///FLAG支持的FLAG也都可以用于s///。例如,s/reg//i表示PATTERN正则匹配的时候不区分大小写。
例如:
my $str = "junmajinlong";
$str =~ s/(jin.*)$/ \1/;
say $str; # junma jinlong
s///的斜线可以替换为其他对称的符号(括号类)或相同的符号。例如,左右相同的分隔符s!!! s### s%%%,对称的括号分隔符s()() s{}{} s<><>等,或者混用这些分隔符s{}## s{}()等。
如果不指定替换目标,则默认操作$_。因此,下面两种写法是等价的:
s///;
$_ =~ s///;
默认情况下,s///返回替换的次数。因此,如果发生了替换,那么替换次数等于1或次数大于1(使用了g修饰符),它们都可以代表真值,如果未发生替换,则返回0,可代表布尔假。
# 如果替换成功,执行say
say "substituted" if s///;
# 不断将空格替换为逗号,每轮循环替换一次,直到所有空给都替换完成
while(s/ /,/){
...
}
如果FLAGS处使用了r修饰符,则拷贝$str,并对拷贝后的数据进行替换,原变量$str的内容不变,此时返回值是替换后的结果而不是替换次数。
在PATTERN中使用分组捕获时,由于捕获成功后会立即将分组捕获的结果保存到特殊变量\1和$1中,所以在Replacement部分可以使用这些变量。
say $str = "gao xiao or ma long";
$str =~ s/(gao)(.*)(ma)(.*)/\3$2\1$4/;
say $str; # 输出ma xiao or gao long
在PATTERN和Replacement部分,可以使用变量,它们会替换为对应的变量值:
my $foo = "foo";
my $bar = "BAR";
my $str="hello foo";
$str =~ s/$foo/$bar/; # hello BAR
还有一种操作符$str !~ s///,用法和=~是相同,只不过它转换了布尔逻辑:替换成功时返回0,未发生替换时返回1。
需要注意,有时候将所有替换操作放在单个s///中,效率可能不如使用多个s///分次替换,这和正则表达式的效率有关。例如,移除前缀空白和后缀空白:
# 一次性替换,效率低
s/^\s*(.*?)\s*$/$1/;
# 分两次替换,效率高
s/^\s+//;
s/\s+$//;
修饰符
m//FLAG可用的修饰符在s///中基本都可用,最常用的修饰符还是gimsx。
my $str = "Gao xiao or Ma long";
# 全局替换,且搜索时不区分大小写
$str =~ s/(gao).* or (ma).*/$2 xiao or $1 long/ig;
再例如,压缩空白:
s/(\s)+/\1/g; # 将多个空白缩减成一个
s/^\s+//; # 去除行首空白
s/\s+$//; # 去除行尾空白
s/^\s+|\s+$//; # 去除行首空白和行尾空白
此外,s///还有自己的修饰符r和e。注:还有一个ee修饰符,和e类似,但多一层eval评估的效果。
r修饰符
默认情况下,s///的返回值是替换成功的次数,使用r修饰符,可以让这个替换操作返回替换后的字符串。几个注意点:
- r修饰符实际上是在替换前先拷贝一份待替换数据,然后在副本上进行替换,所以原始数据不会发生改变
- r修饰符实际上是返回拷贝后的数据,如果替换成功,则返回替换后的字符串,如果替换失败,则直接返回这个副本
- r修饰符的替换返回结果一定是纯文本字符串,即使它操作的是一个对象
my $str = "ma xiao or ma long";
say $str =~ s/Ma/gao/igr; # 输出替换后的内容
say $str; # 原始内容不变
my $copy = $str =~ s/Ma/gao/igr; # 替换后的内容赋值给新的变量
say $copy; # 输出替换后的内容
如果不使用r修饰符,想要将替换的内容输出,只能先将其保存到一个新的变量中,然后输出这个变量:
my $str = "ma xiao or ma long";
(my $copy = $str) =~ s/Ma/gao/ig;
say $str; # 原始数据不变
say $copy; # 替换后的数据
使用r修饰符的时候,可以将多个s///r串联起来:
# bar数据不变,foo保存两次替换之后的结果
my $foo = $bar =~ s/this/that/r
=~ s/that/other/r;
r修饰符在map函数中非常好用,它可以替换一个列表中的某些元素。例如,下面的map将@list中首字母大写的单词替换为小写。
my @list = qw(Ma long Gao xiao);
my @new_list = map {s/([A-Z])([a-z]+)/\L\1\E\2/rg} @list;
say "@new_list";
e修饰符
e可以让Replacement部分当作一个表达式执行,然后将表达式返回结果替换到PATTERN匹配成功的地方。
my $str="ma long or ma xiao";
# 不使用e修饰符
$str =~ s/ma/$& x 2/g;
say $str; # ma x 2 long or ma x 2 xiao
# 使用e修饰符
$str =~ s/ma/$& x 2/eg;
say $str; # mama long or mama xiao
e修饰符使得能够直接在Replacement处使用Perl表达式,这个功能非常好用。例如:
s/PATTERN/++$num/e; # 执行自增操作后替换
s/PATTERN/@{[EXPR]}/e; # 直接执行一个内插表达式
s/PATTERN/sprintf()/e; # 格式化字符串后再替换
s/PATTERN/print$&;$&/e; # 输出$&,丢弃返回值,然后替换为$&
字符映射转换:tr和y///
字符映射转换:tr和y///
除了可用使用s///来替换字符串,Perl还支持y///,它和sed命令的y///作用类似,用于字符映射转换。
Perl中,还支持tr,tr是和y///等价的别名。
tr的语法:
tr/SEARCH/REPLACEMENT/cdsr
y/SEARCH/REPLACEMENT/cdsr
tr或y用于将SEARCH中出现的字符(或指定修饰符c表示未出现的字符)逐字符转换为REPLACEMENT中的字符,根据指定的修饰符不同,转换操作要么是替换(默认是替换),要么是删除(d修饰符)。
tr默认返回替换成功或删除成功的字符数量,如果指定修饰符r,则拷贝一份数据,对数据进行转换并返回,原数据保持不变。
其中:
- c:取search的补集,将search中未找到的字符全都替换成replacement的最后一个字符
- d:删除search中出现的字符
- s:压缩重复字符,仅仅只需要压缩不需要替换时,可将replacement指定为空
- r:返回的不是替换成功的数量,而是替换成功后的内容,原数据不变,和s///的r修饰符是一样的
y///或tr///的斜线分隔符可以替换为其他符号,例如tr### tr%%% tr=== 或括号方式tr{}{} tr()() tr{}[]以及它们的混合方式tr{}// tr()##。
tr的基本用法
下面是tr的一些基本用法。
1.tr的映射功能
将小写字母e替换为大写字母E。
my $str = "abcdef";
$str =~ y/e/E/;
say $str;
将小写字母全替换为大写字母。
my $str="abcdef";
$str =~ y/a-z/A-Z/;
say $str;
如果对同一个字母指定不同的映射集,那么第一个映射关系将生效。
my $str="aaa ddd eee fff";
$str =~ tr/aaa/xyz/; # a被映射为x
say $str; # 输出xxx ddd eee fff
如果未指定Replacement部分,则拷贝Search部分作为Replacement,相当于不做任何替换,但却执行了tr操作,因此有返回值:
say tr/abcd//; # 等价于say tr/abcd/abcd/
如果SEARCH部分比REPLACEMENT部分更长,则REPLACEMENT部分以最后一个字符补齐:
tr/abcd/AB/; # 等价于tr/abcd/ABBB/
2.s修饰符压缩连续字符
使用s修饰符,可将SEARCH中出现的字符进行压缩,然后映射替换或删除。
例如:
my $str = "aabbccdd";
$str =~ tr/a//s; # 连续的a替换为单个a,结果abbccdd
$str =~ tr/b/b/s; # 连续的b替换为单个b,结果abccdd
$str =~ tr/c/*/s; # 连续的c替换为单个*,结果ab*d
再例如:
my $str="abc ddd eee fff";
$str =~ tr/ //s; # 压缩连续空格,结果:abc ddd eee fff
$str =~ tr/d/x/s; # 压缩连续字符d,然后替换,结果:abc x eee fff
$str =~ tr/ef/y/s; # 压缩连续e和f,然后替换,结果:abc x y y
say $str;
可以压缩换行符:
my $str1="abc\n\nddd\neee fff";
$str1 =~ tr/\n //s; # abc\nddd\neee fff
3.d修饰符删除SEARCH中未参与替换的字符
例如,不指定replacement,search中的字符都被删除。用于直接删除某些字符。
my $str="abc ddd eee fff";
$str =~ y/de//d; # abc fff
指定replacement时,将先映射替换,再删除其余未参与替换的字符:
my $str="abc ddd eee fff";
$str =~ y/de/x/d; # d替换为x,e被删除,结果abc xxx fff
$str =~ y/abcf/mn/d; # a->m b->n,cf被删除,结果"mn xxx "
4.c修饰符取补集,将search中未指定的字符全部替换为replacement中的最后一个字符
c修饰符的作用,是将除search中指定字符之外的所有字符,都看作同一类字符。
my $str="aaa bbb ccc ddd";
$str =~ y/ab/xy/c; # aaaybbbyyyyyyyy
注意上面,除a和b外,其余字符全都替换为y,replacement中的x字符被忽略。
c修饰符的作用,相当于将除了ab字符之外的其余字符,都看作另一种相同字符,然后进行下一步操作。比如上面示例,空格字符和cd字符都可以被看作同一类字符A1 A2 A3,然后它们都被替换为字符y。
如果replacement比search长,则仍然是取replacement的最后一个字符作为替换字符。所以下面的等价:
y/ab/xy/c;
y/ab/zxy/c
因此,replacement部分指定单个替换字符即可。
如果同时指定了s修饰符,则先补集替换,然后再压缩。
my $str="aaa bbb ccc ddd";
$str =~ y/ab/xy/sc; # 先补集替换,得到aaaybbbyyyyyyyy
# 再压缩得到aaaybbby
因此,sc修饰符的效果是:除了search部分指定的字符外,其余字符全部被当成同一类字符,然后压缩。
如果同时指定cd修饰符,则删除所有未在search中的字符,也就是说replacement是多余的:
my $str="aaa bbb c d";
$str =~ y/ab/xy/dc; # 删除所有非ab字符,结果:aaabbb
$str =~ tr/0-9//cd; # 删除所有非数字字符
5.使用r返回替换后的结果
r修饰符使得处理数据前会先拷贝一份数据,然后对副本数据进行操作,所以原始数据会保持不变。
my $str="abcdef";
say $str =~ y/e/E/r; # abcdEf
say $str; # abcdef
tr的一些细节
tr不指定操作对象时,默认操作$_。因此,下面是等价的:
$_ =~ tr/a/b/;
tr/a/b/;
tr默认返回被替换或被删除的字符数量,这可以作为获取字符串长度的一种技巧。但需要注意,和length获取字符长度一样,如果被操作的字符串中含有多字节字符,则应当use utf8,否则得到字节数而不是字符数。
say tr///c; # 输出$_变量的字符数量
my $s="你好";
say $s =~ y///c; # 6
{
use utf8;
say $s =~ y///c; # 2
}
使用r修饰符使得tr将拷贝一份数据,并对副本数据进行替换删除,原数据保持不变。因此,可将r修饰符操作后的数据赋值给变量,且有一些技巧可用:
($STR = $str) =~ tr/a/A/; # str不变,对STR进行转换
$STR = $str =~ tr/a/A/r; # str不变,拷贝修改后赋值给STR
$STR = $str =~ tr/a/A/r
=~ s/:/ -p/r; # tr///r和s///r串联
tr总是在编译期间生成字符映射表,因此,无法在search部分和replacement部分使用变量。如果要使用变量,则应该使用eval来实现:
eval "tr/$oldlist/$newlist/";
tr有两种方式指定字符范围:a-z0-9A-Z,以及[a-z0-9A-Z],前者不使用中括号,在编译期间可以精确知道哪些字符需要生成映射表,后者在编译后仍然是动态的字符类,因此无法对其生成映射表。使用不同的字符范围语法,可能会导致不同的结果。例如,在使用d修饰符删除时:
my $str="abc ddd eee fff";
# $str =~ y/d-f//d; # e不会被保留,得到"abc "
# $str =~ y/d-f/e/d; # e被保留,得到"abc eee "
# $str =~ y/[d-f]/e/d; # e不会被保留,得到"abc "
# $str =~ y/[def]/e/d; # e不会被保留,得到"abc "
# $str =~ y/[df]e/e/d; # e不会被保留,得到"abc "
除了=~,也可以使用!~操作符,这表示先进行转换,对转换后的结果布尔取反。也就是说,如果执行了转换操作,则返回布尔假,未执行转换操作,则返回布尔真。例如:
$str !~ tr/A//; # 若$str中有A时返回假,没有A时返回真
使用和理解引用
本章介绍Perl中引用相关的内容。在Perl中,学会使用引用是使用复杂数据结构的前提。
引用基础
引用基础
在前面章节中,曾多次用到过变量的引用:在变量的sigil符号前加上反斜线即表示该变量的引用。
例如,通过引用查看变量所保存数据的内存地址:
my $name = "junmajinlong";
say \$name; # SCALAR(0x55f80476d588)
本书前面章节曾经使用过的引用包括以下几种。除了这几种类型的引用,还有其他类型的引用,比如子程序的引用,文件句柄的引用等,这些类型的引用将在需要的时候再介绍。
$name -> \$name # 标量变量的引用
@array -> \@array # 数组变量的引用
%hash -> \%hash # hash变量的引用
"abc" -> \"abc" # 字面数据值的引用
无论是何种类型的引用,它们都是一种指针,指针中保存了其指向数据的内存地址。打印输出引用时,不同类型的引用,输出结果有所不同:
my $name = "junma";
my @arr = qw(a b c);
my %h = ( name => "junma", age => 23 );
say \$name; # SCALAR(0x55ad7f974dc8)
say \@arr; # ARRAY(0x55ad7f974738)
say \%h; # HASH(0x55ad7fa99150)
引用是一种指针,因此引用是一种标量数据。
例如:
my $name = "junma";
my $name_ref = \$name;
上面示例中,name_ref是一个标量变量,它保存变量name的引用,或者说,name_ref保存了变量name所指向字符串数据"junma"的内存地址。
再例如,数组的引用、hash的引用,也都是标量数据:
my @arr = qw(a b c);
my $arr_ref = \@arr;
my %hash = (name=>"junma", age=>23,);
my $h_ref = \%hash;
理解变量和引用
当声明变量时,Perl会为该变量初始化(默认初始化为undef),它在栈中保存了一个内存地址,以后向该变量赋值时,数据都将存放在栈中这个地址所指向的内存处。
这一点和某些语言的行为有所不同。
Perl以变量存放的地址为基准,将任何赋值给该变量的数据都放在这个内存地址处,变量指向的内存地址永不改变。
而有些语言以内存数据为基准,每次为该变量赋值,都修改变量所存放的地址,使得变量指向该数据。
以下面简单的代码为例:
my $n;
$n = 33;
$n = 'junma';
Perl声明变量n并为变量n赋值的过程大致如下图:
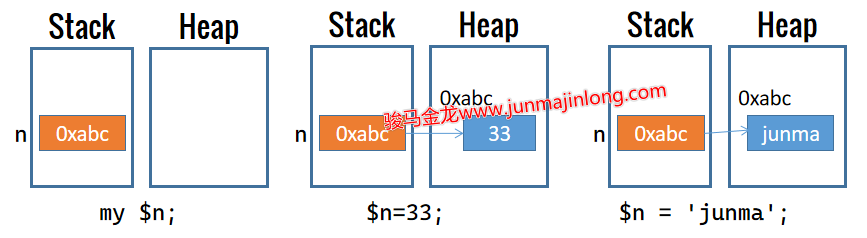
Perl中的数组、hash结构,它们保存的元素也都是各数据的引用,而不是直接将数据保存在数组或hash容器中。
例如:
my @arr = qw(a b c);
my %hash = (one=>1, two=>2, three=>3,);
它们的内存布局大致如图:
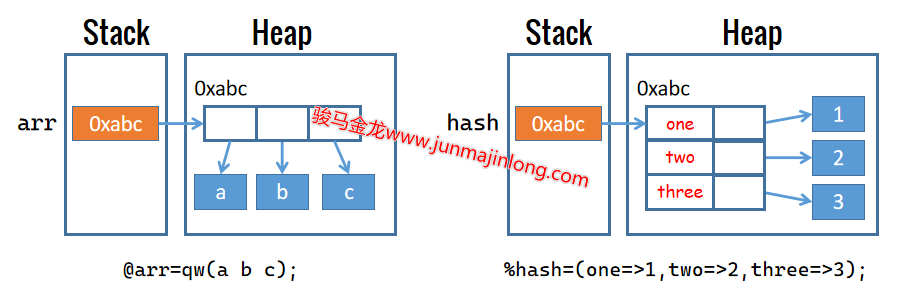
变量保存在栈中指向内存数据的地址,以及数组或hash中各元素所保存的内存数据的地址,都是Perl内部的引用,Perl会自动解析这些地址从而找到它们所指向的内存位置。
此外,也可以手动创建内存数据的引用。例如创建变量n的引用n_ref:
my $n = 'junma';
my $n_ref = \$n;
n_ref是一个变量,声明这个变量的时候,Perl就为其初始化并在栈中保存了一个内存地址。此外,变量n_ref是一个引用,它是一个标量变量,该变量实际保存的数据是变量n所指向内存数据的地址。
因此,现在内存的布局大致如下图:
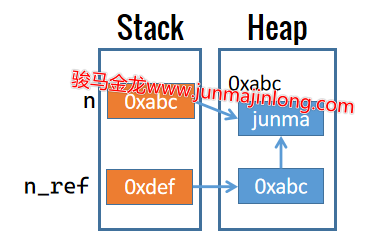
从图中可以知道,变量n在栈中保存的数据和变量n_ref在堆中所保存数据是一致的,都是指向堆中实际数据的指针。
因此,名称n和名称$n_ref在使用时是等价的,原来使用名称n的地方,都可以替换为使用其引用$n_ref。注意,n没有sigil前缀,这表示该变量的栈中数据,即指向"junma"的指针,而n_ref有sigil前缀,这表示导航到该变量在堆中保存的数据,即指向"junma"的指针。
例如:
my $name = "junma";
my $name_ref = \$name;
say $name;
say $$name_ref; # $name中的名称name替换为$name_ref

对数组变量名、hash变量名的使用,也一样可以替换为它们的引用:
# 数组变量名和数组引用:名称arr可被替换为$arr_ref
my @arr = qw(a b c);
my $arr_ref = \@arr;
say $arr[0]; # 或${arr}[0]
say $$arr_ref[0]; # 或${$arr}[0]
# hash变量名和hash引用:名称hash可被替换为$h_ref
my %hash = (
name => "junma",
age => 23,
);
my $h_ref = \%hash;
say $hash{name}; # 或${hash}{name};
say $$h_ref{name}; # 或${$h_ref}{name}
实际上,只要理解了sigil符号的作用,也能很容易理解变量名和引用变量之间的关系。例如$name表示根据name变量所存储的内存地址进行导航,导航到该地址所指向的内存处。对于${$name_ref},内部的$name_ref表示根据name_ref所保存的内存地址导航到其所指向的内存处,该内存处保存了一个引用指针,因此,可以继续使用$符号根据这个引用指针去导航到最终其所指向的内存处。
按引用赋值
Perl手动进行变量赋值时,总是按值拷贝变量数据。
例如:
my $name = "junma";
my $name1 = $name;
上面的name和name1的值都将是junma,但它们没有任何关系,它们互不影响。在将$name赋值给$name1时,$name会导航到name所指向的内存地址处,并取得该内存处的数据,拷贝一份保存到name1变量所指向的内存位置处。
但Perl支持操作数据的引用,因此,可以将数据的引用赋值给一个变量。此时仍然算是按值拷贝,只不过拷贝的值是一个引用值。
my $name = "junma";
my $name1 = \$name;
上面的$name1和变量name都指向同一个内存地址,\$name操作会拷贝一份name所保存的内存地址,然后赋值给变量name1。现在,修改name变量将会影响name1变量:
my $name = "junma";
my $name1 = \$name;
$name = "junmajinlong";
say $$name1; # junmajinlong
但注意,修改变量name1不会影响变量name,比如为name1重新赋值,这是因为修改name1时,改变的是其所保存的堆数据,这可能会让它不再指向name所指向的数据:
my $name = "junma";
my $name1 = \$name;
# name1不再是引用变量,而是字符串变量
$name1 = "junmajinlong";
say $name1; # junmajinlong
say $name; # junma
可以为某个数据创建任意多个引用:
my $name = "junma";
my $name_ref1 = \$name;
my $name_ref2 = \$name;
my $name_ref3 = $name_ref2;
有时候为了方便,会直接将字面量数据的引用赋值给变量,有时候也会在声明变量的时候直接将其引用赋值给另一个变量:
# 将字面量的引用赋值给变量
my $name = \"junmajinlong";
say $name;
# 声明变量的同时,将其引用赋值给变量
my $age_ref = \my $age;
say $age_ref;
# 声明变量的同时赋值,且将其引用赋值给变量
my $age1_ref = \(my $age1 = 33);
say $$age1_ref; # 33
引用计数
引用计数
Perl采用引用计数的方式来管理内存:每次引用内存数据,该数据的引用计数加1,当引用计数减为0,Perl将回收该内存数据。
具体来说,Perl会对每个内存数据都会维护一个引用计数器:
- 最初创建数据对象时,赋值给初始化变量或者保存在数组或hash中时,该数据的引用数为1
- 以后每次引用、赋值引用、拷贝引用等操作都会对引用数加1
- 将变量赋值为undef,或者,将数组或hash中原本指向该数据的元素设置为undef,将显式取消引用关系,引用数减1
- 引用可能在作用域中,当离开对应作用域时,该作用域内的引用将取消(比如my声明的变量离开作用域时,引用数将1)
- 只要某内存数据的引用计数还未减少为0,该内存数据所占用的内存就不会释放。当引用计数为0时,perl将回收这段内存空间,但不会交还给操作系统,在必要的时候perl会重用这段内存空间存储新数据,而无需再向操作系统申请新内存
例如:
my $name = "junma"; # 数据junma的引用数1
my @arr = (\$name, 23); # 数据junma的引用数2
my $name_ref = \$name; # 数据junma的引用数3
{
my $name_ref1 = $name_ref; # 数据junma的引用数4
} # 数据junma的引用数3,出作用域
undef @arr=undef; # 数据junma的引用数2
$name_ref = 111; # 数据junma的引用数1
$name = undef; # 数据junma的引用数0,junma被perl回收
使用引用计数方式管理内存,它最大的优点在于:
- 即刻回收:只要数据对象的引用计数器为0了,就会立刻被回收,不会推迟
- 暂停时长很短:因为回收时无需遍历内存,所以回收率很高
但使用引用计数方式管理内存也有很大的缺点:
- 要频繁增、减计数,增、减计数的工作压力非常大
- 无法回收循环引用
想象一下,在循环100W次的循环中使用一个字面量,那么增、减该数据的引用计数并回收该数据各100W次。好在,Perl已经对此做好了优化:在循环中会缓存字面量并在循环过程中一直使用该缓存结果。
say \"junma";
say \"junma";
for (1..5){
say \"junma";
}
输出结果:
SCALAR(0x55e14a34dc10) # 不在循环中,字面量地址不同
SCALAR(0x55e14a34dcd0)
SCALAR(0x55e14a7292b0) # 循环过程中字面量地址相同
SCALAR(0x55e14a7292b0)
SCALAR(0x55e14a7292b0)
SCALAR(0x55e14a7292b0)
SCALAR(0x55e14a7292b0)
解引用
解引用
前面说过,在使用上,可以使用变量名称的地方,都可以替换使用引用变量。理解了这一点,就知道如何去解引用:根据引用获取其指向的原始数据。
标量的解引用、数组的解引用和hash的解引用方式如下:
- 引用的是一个标量,解引用时加上sigil前缀
$ - 引用的是一个数组,解引用时加上sigil前缀
@ - 引用的是一个哈希,解引用时加上sigil前缀
%
以标量$name及其引用$name_ref、数组@arr及其引用$arr_ref、hash结构%hash及其引用$hash_ref为例,分别通过变量和引用变量取得其所指向内存数据的分别方式为:
$name -> $$name_ref
@arr -> @$arr_ref
%hash -> %$hash_ref
也可以使用变量的完全限定语法:
${name} -> ${$name_ref}
@{arr} -> @{$arr_ref}
%{hash} -> %{$hash_ref}
对于数组或hash,取它们的某个元素:
$arr[0] -> $$arr_ref[0]
${arr}[0] -> ${$arr_ref}[0]
$hash{name} -> $$hash_ref{name}
${hash}{name} -> ${$hash_ref}{name}
例如:
my @name=qw(junma jinlong);
my $ref_name=\@name;
say "@{ $ref_name }";
say "@$ref_name";
say "$$ref_name[0]";
say "${$ref_name}[0]";
瘦箭头->解引用
除了上面介绍的解引用方式,Perl还允许使用瘦箭头->来解引用获取数组或hash中的元素。例如$a_ref->[0]和$h_ref->{name}。
例如:
my @names = qw(junma jinlong);
my $ref_names = \@names;
say $ref_names->[0]; # 等价于${$ref_names}[0]
my %hash=(
name => "junmajinlong",
age => 23,
);
my $ref_hash =\%hash;
say $ref_hash->{name}; # 等价于${$ref_hash}{name}
当数组中嵌套数组或hash,hash中嵌套数组或hash时,优先使用瘦箭头解引用的方式来取元素,这样整个取值过程更清晰。
例如,下面是取复杂数据结构中某元素的三种写法,显然使用瘦箭头方式要比原始的解引用方式更简洁。
# $ref_Config是一个hash引用,取得其中的urllist值
# urllist值是一个数组,取得第二个元素,该元素仍为数组,
# 再取得第四个元素,依然是数组,最后取得第二个元素
say ${$ref_Config}{urllist}[1][3][1];
say ${${${$ref_Config}{urllist}[1]}[3]}[1];
say $ref_Config->{urllist}->[1]->[3]->[1];
并且,连续多个瘦箭头时,从第二个瘦箭头开始可以省略瘦箭头。例如上面最后一种写法可简写为:
say $ref_Config->{urllist}[1][3][1];
复杂数据结构
复杂数据结构
复杂数据结构是指数组中嵌套数组或hash,hash中嵌套数组或hash,甚至它们存在多层嵌套关系。
由于Perl中数组或hash是根据列表提供的数据来构建的,如果直接将数组或hash放进列表上下文,它们将自动转换为列表数据,这样的行为可能会使得最终构建的结果并非预期结果。例如:
my @arr = qw(a b c);
# 嵌套数组,但@arr的元素直接被插入到了@arr1
# 等价于@arr1 = qw(a a b c b)
my @arr1 = (a, @arr, b);
my @arr2 = qw(a b c);
# %hash的某个value设置为数组,但
# 该数组不会作为值,而是展开为列表再构建Hash
# 等价于: (aa=>'a',b=>'c',bb=>1)
my %hash = ( aa => @arr2, bb => 1);
因此,在需要嵌套数组或hash的时候,应当使用它们的引用。
例如:
my @arr = qw(a b c);
my %h = ( aa => \@arr, bb => 1);
现在hash变量h中嵌套保存了一个数组,要获取到这个数组的第一个元素,方式为:
my $aa_value = $h{aa};
say ${$aa_value}[0];
# 或者可读性非常差的:say ${$h{aa}}[0];
如果改用Perl的瘦箭头解引用方式,则取值过程非常清晰:
say $h{aa}->[0];
say $h{aa}[0]; # 可省略瘦箭头
也可以将一个复杂的hash结构的引用嵌套在一个数组或其他hash中,例如:
my @arr = qw(a b c);
my %h = ( aa => \@arr, bb => 1);
my @outer = ( 'x', 'y', \%h, 'z' );
say $outer[2]->{aa}->[0];
say $outer[2]->{aa}[0];
say $outer[2]{aa}[0];
下面是一个更为复杂的取值示例:
my @more_urllist=qw(http://mirrors.shu.edu.cn/CPAN/
http://mirror.lzu.edu.cn/CPAN/
);
my @my_urllist=('http://mirrors.aliyun.com/CPAN/',
'https://mirrors.tuna.tsinghua.edu.cn/CPAN/',
'https://mirrors.163.com/cpan/',
\@more_urllist # 将数组more_urllist引用作为元素
);
my %Config = (
'auto_commit' => '0',
'build_dir' => '/home/fairy/.cpan/build',
'bzip2' => '/bin/bzip2',
'urllist' => [
'http://cpan.metacpan.org/',
\@my_urllist # 将数组my_urllist作为元素
],
'wget' => '/usr/bin/wget',
);
my $ref_Config=\%Config;
现在想要通过$ref_Config取得@more_urllist中的第二个元素:
say ${$ref_Config}{'urllist'}[1][3][1];
say ${${${$ref_Config}{'urllist'}[1]}[3]}[1];
say $ref_Config->{urllist}->[1]->[3]->[1];
say $ref_Config->{urllist}[1][3][1];
显然,除了第二种写法非常伤眼睛之外,其他写法都比较简洁。
打印输出数据结构
默认情况下,Perl使用print、say、printf进行输出,但有些变量数据不适合使用它们进行输出。比如想查看一个hash结构却又不想遍历hash。
可以使用Perl模块Data::Dump提供的dump函数进行输出,需要先安装:
cpan install Data::Dump
安装之后,导入使用:
use Data::Dump qw(dump);
my @arr = qw(a b c d);
my %hash = ( name=>"junma", age=>23, arr => \@arr);
# 传递待输出数据的引用
dump(\@arr);
dump(\%hash);
输出:
["a" .. "d"]
{ age => 23, arr => ["a" .. "d"], name => "junma" }
更适合查看数据结构的是Data::Printer模块的p方法。先安装:
cpan install Data::Printer
使用p()输出数据结构:
use Data::Printer;
my @arr = qw(a b c d);
my %hash = ( name=>"junma", age=>23, arr => \@arr);
p(@arr);
p(%hash);
输出结果:
[
[0] "a",
[1] "b",
[2] "c",
[3] "d"
]
{
age 23,
arr [
[0] "a",
[1] "b",
[2] "c",
[3] "d"
],
name "junma"
}
上面的输出结果中,数组元素带了索引,hash元素的key和value之间使用空白符号分隔。这些输出行为都可以控制。例如:
use Data::Printer {
index => 0, # 不要输出数组索引
hash_separator => ': ', # hash元素的key和value分隔符
quote_keys => 'auto', # 自动加引号
};
my @arr = qw(a b c d);
my %hash = ( name=>"junma", age=>23, arr => \@arr);
p(@arr);
p(%hash);
输出结果:
[
"a",
"b",
"c",
"d"
]
{
age : 23,
arr : [
"a",
"b",
"c",
"d"
],
name: "junma"
}
Data::Printer还支持查看(面向对象的)对象结构,支持其他很多种输出控制行为,可参考模块手册:https://metacpan.org/pod/Data::Printer。
匿名数组和匿名hash
匿名数组和匿名hash
在此之前,构建数组和hash结构时,都使用列表语法去提供数据。但Perl也是允许使用中括号[]构建数组,使用大括号{}构建hash的,只不过它们构建的是匿名数组、匿名hash,它们都是引用。
- 使用中括号
[]构建匿名数组 - 使用大括号
{}构建匿名hash - 不包含任何元素的
[]和{}分别是匿名空数组、匿名空hash
构造匿名对象
例如,在数组、hash中构建匿名数组:
# 匿名数组、匿名hash都是引用,因此赋值给标量变量
my $anonymou_array = []; # 空数组
my $anonymou_hash = {}; # 空hash
# 将匿名数组嵌套在其他数组或hash中
my @name=('fairy', ['longshuai','wugui','xiaofang']);
my %hash=('longshuai' => ['male',18,'jiangxi'],
'wugui' => ['male',20,'zhejiang'],
'xiaofang' => ['female',19,'fujian'],
);
say "$name[1][2]";
say "$hash{wugui}[1]";
如果不想在匿名数组中输入引号,可以使用qw()。
# 以下等价
my @name=('fairy',['longshuai','wugui','xiaofang']);
my @name=('fairy',[qw(longshuai wugui xiaofang)]);
在数组、hash中构建匿名hash:
my @name=( # 匿名hash作为数组的元素
{ # 第一个匿名hash
'name'=>'longshuai', 'age'=>18,
},
{ # 第二个匿名hash
'name'=>'wugui', 'age'=>20,
},
{ # 第三个匿名hash
'name'=>'xiaofang', 'age'=>19,
},
);
my %hash=( # 匿名hash作为hash的value
'longshuai'=>{ # 第一个匿名hash
'gender'=>'male', 'age'=>18,
},
'wugui'=>{ # 第二个匿名hash
'gender'=>'male', 'age'=>20,
},
'xiaofang'=>{ # 第三个匿名hash
'gender'=>'female', 'age'=>19,
},
);
解除匿名对象的引用
匿名数组或匿名hash是引用,因此可以解除引用,还原得到原始数据对象。
my $arr_ref = [qw(a b c)];
say "@$arr_ref"; # 解除引用得到匿名数组
除了可以通过解除引用变量的方式来得到匿名数据结构,还可以直接解除匿名数据结构:
- 解除匿名数组的引用
@{[]} - 解除匿名hash的引用
%{ {} }
之所以可以直接解除匿名数组和匿名hash,是因为构建匿名数组的[]和构建匿名hash的{}本身就返回引用。
例如,解除匿名数组:
# 解除匿名数组的引用,得到数组,再将其内插到双引号
say "@{ ['longshuai','xiaofang'] }";
say "@{ [qw(longshuai xiaofang)] }";
# 获取匿名对象中的第二个元素
say "@{ [qw(longshuai xiaofang)] }[1]";
解除匿名hash:
say %{ # 解除匿名hash
{ # 构造匿名hash
longshuai=> ['male',18,'jiangxi'],
wugui => ['male',20,'zhejiang'],
xiaofang => ['female',19,'fujian'],
}
}{longshuai}->[1];
解除匿名数组在双引号中内插的技巧
双引号中可以内插标量变量、数组变量,更严谨地说,是双引号中允许内插sigil符号$ @符号的取值操作。比如取标量值(包括取数组元素、hash元素)、取列表数据(包括取数组数据、取切片数据)。
# 内插标量取值
say "$name";
say "$hash{name}";
say "$arr[0]";
say "$hash{name}->{nn}->{nnn}";
# 内插列表值
say "@arr";
say "@arr[0,1,2]";
say "@hash[name,age]";
但Perl并不允许在双引号中直接内插hash,也不允许直接内插表达式或语句。
而从前面示例可知,解除匿名数组的语法@{[]}是可以直接内插在双引号中的,它会通过中括号将其中的数据构建成匿名数组,然后使用@{}解除匿名数组的引用,最终得到一个数组结构。这种语法为双引号中内插表达式提供了解决方案。
例如:
my $age = 23;
say "age+10: @{[$age+10]}";
my @arr = qw(Perl Go JavaScript Shell Ruby Python);
say "[len >= 5]: @{[grep {length $_ >=5} @arr]}";
最后注意,@{[]}的上下文环境是列表上下文。
大括号:区分匿名hash和代码块
Perl中大括号被用在多个地方:一次性语句块、if/for/while等的语句块、grep/map等的语句块、构建匿名hash。
大多数时候,Perl会根据使用{}的上下文环境自动判断大括号的作用,但有时候会判断错误或无法判断。例如:
# Perl无法判断
my %hash = map { "\L$_" => 1 } @array;
# Perl推断出大括号是语句块
my %hash = map { +"\L$_" => 1 } @array;
my %hash = map {; "\L$_" => 1 } @array;
my %hash = map { ("\L$_" => 1) } @array;
my %hash = map { lc($_) => 1 } @array;
# Perl推断出大括号是构建匿名hash的大括号
my @hashes = map +{ lc($_) => 1 }, @array;
因此,有时候需要显式地告诉Perl,这个大括号是语句块的大括号还是构建匿名hash的代码块:
- 大括号前面加上
+符号,即+{...},表示这个大括号是用来构造匿名hash的 - 大括号内第一个语句前,使用一个
;,即{;...},表示这个大括号是语句块
+不仅仅可以加载匿名hash的大括号前,还可以加在匿名数组的中括号前,以及hash引用变量、数组引用变量前,如+$ref_hash、+[]、+$ref_arr。
@{ +[qw(longshuai wugui)]} # 匿名数组中括号前
@{ +$ref_arr } # 数组引用变量前
%{ +$ref_hash } # hash引用变量前
autovivification特性
这个单词是perl自造的词,应用到了多种语言中:Wiki Autovivification。
它的功能大致为:当解除引用时,如果解除目标不存在,Perl会自动创建一个空目标,且会自动递归补齐上层缺失目标。注意,autovivification的作用体现在解除引用时。
这有点像Unix下的mkdir -p一样,当创建某个目录的时候,如果其父目录不存在,则自动补齐创建缺失的父目录。
例如:
push @{ $config{path} },'/usr/bin/perl';
say keys %config; # 输出:path
say $config{path}; # 输出:ARRAY(0x...)
say $config{path}[0]; # 输出:/usr/bin/perl
执行到push的时候,perl首先会发现@{}在解除一个匿名数组引用,这个引用来自于$config{path},因此$config是一个hash引用,但是perl发现这个hash目前还不存在,hash里的key(即path)也不存在。于是根据autovivification特性,perl首先会构建一个空的hash对象%config={},然后创建hash里的一个key:path,其值为空列表,即$config{path}=[],最后将"/usr/bin/perl"字符串push到对应的列表中,即$config{path}=['/usr/bin/perl']。
在上面的示例中,perl在解除引用时,自行创建了几个部分:
- 自建一个hash对象
- 自建hash对象中的一个元素
- 自建hash对象中某个元素的value部分
必须注意,perl的autovivification功能只在解除引用的时候才自建缺失的结构,从解除引用的操作动机上看,每当要解除引用,说明可能要操作引用对象中的数据了,那么缺少的部分应该要补齐。
如果不是在解除引用,那么Perl将根据语法特性决定是否自建对象。例如下面将自建数组@name和hash对象%person以及它的一个元素$person{name}。但这不是autovivification的特性,而是perl的语法特性,且是未处在strict模式下的特性。
push @name,"longshuai";
$person{name}="longshuai"
say "$name[0]";
say keys %person;
紧跟着上面的示例:
@{ $config{path} }[2]='/usr/bin/perl';
say $config{path}; # 输出:ARRAY(0x5571664403c0)
say $config{path}[0]; # 输出:空
say $config{path}[1]; # 输出:空
say $config{path}[2]; # 输出:/usr/bin/perl
say scalar @{$config{path}}; # 输出元素个数:3
检查引用的类型
检查引用的类型
有时候可能会需要检查引用是什么类型的(主要是在定义函数时使用),从而确保期待数组引用时,传递的确实是数组引用,而不是hash引用。
ref函数可用来检查引用的类型,并返回类型。perl中内置了如下几种引用类型,如果检查的不是引用,则返回undef。
SCALAR
ARRAY
HASH
CODE
REF
GLOB
LVALUE
FORMAT
IO
VSTRING
Regexp
例如:
my @name=qw(longshuai wugui);
my $ref_name=\@name;
my %myhash=(
longshuai => "18012345678",
xiaofang => "17012345678",
wugui => "16012345678",
tuner => "15012345678"
);
my $ref_myhash =\%myhash;
say ref $ref_name; # ARRAY
sya ref $ref_myhash; # HASH
因此,可以对传入的引用进行判断:
my $ref_type = ref $ref_hash;
say "expect HASH reference" unless $ref_type eq 'HASH';
上面的判断方式中,是将HASH字符串硬编码到代码中的。如果不想硬编码,可以让ref对空hash、空数组等进行检测,然后对比。
ref [] # 返回ARRAY
ref {} # 返回HASH
例如:
my $ref_type=ref $ref_hash;
say "expect HASH reference" unless $ref_type eq ref {};
或者,将HASH、ARRAY这样的引用类型名定义为常量:
use constant HASH => ref {};
use constant ARRAY => ref [];
say "expect HASH reference" unless $ref_type eq HASH;
say "expect Array reference" unless $ref_type eq ARRAY;
除了ref函数,Perl模块Scalar::Util提供的reftype函数也用来检测类型,它还适用于对象相关的检测。
Perl子程序
在某些语言中,子程序(subroutine)是没有返回值的可复用的代码结构,函数(function)是有返回值的可复用的代码结构。
在Perl中,子程序就是函数,它们没有区别。但通常,会将内置的代码结构称为函数,将自定义的代码结构称为子程序。
Perl内置了很多已经预先定义好的函数,例如rand()、chomp()等,这些函数称为内置函数,可直接调用这些函数。
Perl也允许使用sub关键字自定义子程序。例如:
# 定义子程序
sub say_hello{
say "hello";
}
# 调用子程序
say_hello();
定义子程序完整的语法为:
sub NAME BLOCK
sub NAME(PROTO) BLOCK
sub NAME : ATTRS BLOCK
sub NAME(PROTO) : ATTRS BLOCK
对于这几种定义语法:
- 通常情况下定义子程序时,子程序名称后面不带括号,正如前面定义的say_hello子程序
- 如果定义子程序时,子程序名称后面加上小括号,表示定义原型子程序。原型子程序是一种参数模板,可粗略地理解为函数签名,比如限制最多传递几个参数、限制传递数组还是hash,等等。多数原型功能也能通过普通子程序实现,并且原型的效果有时候是超出预料的,因此,除非明确知道所使用的原型含义,否则不推荐定义原型子程序
- 定义子程序时使用了冒号,这表示为子程序设置它的属性,可用的三种属性是:
- locked:表示锁住子程序,使其线程安全,多个线程无法同时进入子程序
- method:表示这个子程序是对象方法,method通常结合locked一起使用,此时表示锁住方法的第一个参数(self),即锁住对象
- lvalue:表示这个子程序可以作为一个左值,即可以被赋值
更多子程序属性(以及变量属性),参考perldoc attributes。
定义和调用子程序
定义和调用子程序
使用sub关键字定义子程序roll,该子程序用于掷色子,它返回1-6之间的随机整数:
sub roll{
print 1 + int(rand(6));
}
注意:
在定义子程序时,不要随意在子程序名称后面加上小括号,
sub f(){}和sub f{}是有很大区别的,前者是一种使用原型(prototype)的子程序定义方式,通常称为原型子程序。在本章节的后面将详细介绍原型子程序。
定义好roll子程序后,有几种调用子程序的方式:
- 使用子程序名称调用子程序
- 使用sigil前缀
&调用子程序 - 子程序名称后面加上小括号
不同调用方式的行为不同,本章后面将详细介绍各种不同调用方式的区别。
例如:
# 定义子程序
sub roll{
print 1 + int(rand(6));
}
# 不同调用方式
roll;
roll();
&roll;
&roll();
可以使用return关键字(return实际上也是一个内置函数)设置子程序的返回值,return会使子程序立即退出,即让子程序的执行流程立即终止。例如,返回掷色子的随机整数值,而不是输出它:
sub roll{
return 1+int(rand(6));
}
设置子程序的返回值后,调用子程序时它就有了返回值。使用返回值的其中一种方式是将返回值赋值给变量:
my $random = &roll;
还可以为子程序传递参数,使得子程序内部可以使用传递进来的数据。Perl子程序的参数处理比较特殊,在后面会详细解释。
sub roll{
my $num = shift @_; # 获取传递的第一个参数
return 1 + int( rand($num) );
}
# 调用参数时,传递参数
my $random = roll(6);
子程序的返回值细节
子程序的返回值细节
Perl子程序总是有返回值,且因为存在上下文的原因,子程序的返回值和其他语言有些不同,有必要去了解一下相关的细节。
Perl中设置返回值的方式有两种:使用return和无return。其中:
- return的参数(即要指定的返回值)是一个列表上下文
- 无return时将以最后被执行的语句计算结果作为返回值
无参数的return
如果不指定return的参数,它也有指定返回值,此时return自身将根据调用子程序的上下文来决定返回何值:
- 在列表上下文,无参数的return返回空列表
- 在标量上下文,无参数的return返回未定义值(可当作undef或0或空字符串使用)
- 在空上下文,无参数的return不返回任何数据,只用于终止子程序
sub roll{
print 1+int(rand(6));
return;
}
无return的子程序返回值
在Perl中,即使不使用return指定返回值,子程序也会有返回值,此时子程序的返回值为最后一条被执行语句的计算结果。
下面是两个等价的子程序定义方式:
sub roll{
1+int(rand(6));
}
sub roll(){
return 1+int(rand(6));
}
这里要注意区分最后一条被执行语句和最后一条语句,最后一条被执行的语句不一定是子程序的最后一条语句。例如:
sub roll{
if(COND){
## 分支1
2;
} else {
## 分支2
3;
}
}
如果COND条件为真,则最后一条被执行的语句分支1中的2,2直接被返回。如果COND条件为假,则最后一条被执行的语句是分支2中的3,3直接被返回。
由于子程序中不使用return关键字时也有返回值,有时候要注意它可能带来的副作用。
例如,下面的子程序也有返回值:
sub roll{
print 1 + int(rand(6));
}
上述子程序中没有使用return,因此最后一条被执行语句的计算结果(或它的返回值)是该子程序的返回值。最后一条被执行的语句是print语句,print函数的返回值为1,因此roll()的返回值为1。
say roll(); # 1
返回单值和列表
使用return返回时,可直接返回标量,也可以返回多个数据组成的列表:
# 返回单个值
return 1
return 0
return ""
# 返回多值组成的列表
return 1,2,3;
return (1,2,3);
返回数组和hash
Perl中的return无法直接返回数组和hash,因为它们会先转换成列表,再以列表的方式返回。
如果确实要返回数组或列表,应当返回它们的引用。
return $array_ref;
return $hash_ref;
也可以返回匿名数组或匿名hash:
return [qw(a b c)]; # 返回匿名数组
return {(name=>"junmajinlong", age=>23,)}; # 返回匿名hash
不同上下文的子程序return
使用return返回时,将根据所处上下文的不同进行对应的转换。
例如,对于return返回列表的子程序,当它处于一个标量上下文中时,返回的列表将转换为标量数据,即列表的最后一个元素(再次提醒,要区分标量上下文中列表和数组转换为标量的区别:列表取最后一个元素,数组取数组长度)。
如果想要根据上下文的不同决定不同的返回值,可使用wantarray关键字。wantarray用来检测子程序在何种上下文环境:
- wantarray在列表上下文返回true
- wantarray在标量上下文返回false
- wantarray在空上下文返回未定义数据
wantarray典型的用法大致如下:
# 如果在空上下文,则直接终止,不返回数据
return unless defined wantarray;
# 如果在列表上下文,返回数组数据(会转换为列表),
# 在标量上下文,返回标量数据
return wantarray ? @array : $scalar;
实际上,wantarray更应该命名为wantlist,它期待的是列表上下文,而不是期待数组。在perldoc -f wantarray中也说明了,wantarray在未来的版本中可能会更换为wantlist。
子程序的参数
子程序的参数
Perl子程序不需要定义形参,在调用子程序时,传递参数的地方是一个列表上下文,传递的所有实参会依次放入名为@_的数组中。因此,通过$_[0]可获取第一个参数的值,通过$_[1]可获取第二个参数的值,依次类推。
sub area{
my $length = $_[0];
my $width = $_[1];
return $length * $width;
}
# 传递两个参数,子程序内部:`@_ = (2, 5)`
say area(2, 5);
Perl的默认变量总结:
1.默认标量变量
$_2.在子程序内部,默认列表变量是
@_3.在子程序外部,默认列表变量是
@ARGV
在子程序内部,列表操作的默认对象是@_,因此,在子程序内部,下面两个操作是等价的:
shift @_;
shift;
它们都表示获取第一个参数,且从参数列表@_中移除第一个参数。
在定义子程序时,经常会使用shift来获取所传递的参数并修改参数列表:
sub subname{
my $arg1 = shift;
my $arg2 = shift;
}
处理多个参数
调用子程序时,可直接传递多个参数:
subname('a', 'b', 'c', 'd');
上面传递的四个参数,均存储在@_中,可分别通过$_[0]、$_[1]、$_[2]、$_[3]获取。
有时候可能会期望将前几个参数赋值给指定变量,剩余参数放进一个数组。这种需求可以这样实现:
my ($a, @arr) = @_;
当然,也可以将传递的参数组合成hash:
sub subname {
my %hash = @_;
say keys %hash;
say values %hash;
}
subname(
"name", "junmajinlong",
"age", 23,
);
# 或者
subname(
name=>"junmajinlong",
age=>23,
);
上面第二种调用subname子程序时传递参数的方式也是传递命名参数的方式。但是,这种方式处理命名参数比较容易出错,这要求传递的参数必须能够转换成hash数据,如果传递的参数不合理,将会给出警告或报错。
例如,只传递单个参数,将无法合理地构建成hash,于是会给出警告信息:
subname("junmajinlong");
解决这种问题的方案是传递一个hash引用。参考下文。
注意,重新构建的数组变量、hash变量必须放在最后面。例如,下面处理参数的方式是不合理的:
my (@arr, $a, $b) = @_;
放在最前面的@arr会吞掉@_的所有元素,使得$a和$b都是空变量。
传递数组和hash
实际上,调用子程序的参数部分是一个列表上下文,传递的所有参数都会转换为列表数据然后放入@_中。
因此,直接将数组变量或hash变量作为参数传递给子程序,将得不到期待的结果,数组变量或hash数据都会被压平(flatten)。
my @arr = qw(a b c);
my %h = (name=>"junma", age=>23,);
subname(@arr); # 等价于subname('a', 'b', 'c');
subname(%h); # 等价于subname('name', 'junma', 'age', 23);
某些情况下,可以将它们压平后的元素重新构建成数组或hash:
sub subname{
my @arr = @_; # 将所有参数重新构建成数组
my %h = @_; # 将所有参数重新构建成Hash
...
}
但这种重新构建数组或hash的方式不能适用于所有场景,有些情况下也不方便,比如传递的参数数量是奇数时不能合理地构造hash,比如要传递非常多参数时,传递所有参数数据不如传递一个包含它们的引用更高效。
如果确实需要传递数组或hash,建议的方式是传递它们的引用。
sub subname{
my $arr_ref = shift;
say $$arr_ref[0];
}
my @arr = qw(a b c);
subname(\@arr);
当然,也可以传递匿名数组、匿名hash,它们本质上仍然是引用。
sub subname{
my $arr_ref = shift;
my $hash_ref = shift;
my $scalar = shift;
say $$arr_ref[0];
say $$hash_ref{name};
say $scalar;
}
subname([qw(a b c)], {name=>'junma', age=>23}, 3333);
参数是别名引用
调用子程序时传递的参数,放入@_中的都是原始数据的别名引用:修改@_各元素的值,也将影响原始数据。
例如:
sub subname{
$_[0]++;
say $_[0];
}
my $a=33;
subname($a);
say $a;
这将输出:
34
34
也就是说,@_中的数据和原始数据是完全相同的,它们是别名关系。
这种别名关系也存在于容器的元素中。
sub subname{
$_[0]++;
say $_[0];
}
my @arr = (11,22,33);
subname(@arr);
say $arr[0];
实际上,subname(@arr)会将@arr的各元素压平后传入子程序内的@_,但是压平后的是各元素的别名,而不是各元素的值。因此上面的示例输出:
12
12
如果想要让子程序内部的修改不影响原始数据,则应该将参数数据保存到变量中。
sub subname{
my $a = shift;
$a++;
say $a;
}
my $x=33;
subname $x; # 34
say $x; # 33
数组也类似:
sub subname{
my @arr = @_;
$arr[0]++;
say $arr[0];
}
my @arr=(11,22,33);
subname @arr; # 12
say $arr[0]; # 11
调用子程序的几种方式
调用子程序的几种方式
注:本节包含了原型子程序相关内容,关于原型,将在本章后面的小节中详细介绍。
在Perl中,调用子程序有几种方式。以调用subname子程序为例:
- (1).
&subname([args]) - (2).
subname([args]) - (3).
subname [args]和无参数时的subname - (4).
&subname
从上面几种调用方式来看,容易发现不允许使用&subname args调用方式,即&前缀不能和没有小括号的参数传递一起使用。
必须得区分清楚这几种调用方式的不同之处:
- 建议的调用子程序方式是(2),即使用小括号调用方式
- 如果子程序已经定义好了(即子程序先定义后调用),则可以省略小括号,即(3)
- 使用小括号调用子程序时,sigil前缀
&是可选的,即(1)和(2)效果差不多:- 对于一般的子程序来说,(1)和(2)等价
- 对于原型子程序来说,(1)和(2)不等价
- 使用了sigil前缀
&,有两层效果:- 当未手动传递参数时,将调用子程序环境的
@_传递给子程序,即(4)。例如,如果在子程序a中&b调用子程序b,调用子程序a(1,2,3),则参数1、2、3也将传递给子程序b(可继续参考稍后的示例来理解) - 忽略编译器的原型检测过程
- 当未手动传递参数时,将调用子程序环境的
例如,下面两个子程序,without_prototype不带原型,with_prototype带有原型:
# (1)
sub without_prototype{ ... }
sub with_prototype(){ ... }
# (2)
在位置(1)处,可通过如下几种方式分别调用without_prototype和with_prototype:
&without_prototype;
without_prototype();
without_prototype(1,2,3); # 带参数调用
&without_prototype();
&without_prototype(1,2,3); # 带参数调用
# 原型子程序会先检测原型,因此应当先定义再调用
&with_prototype; # 跳过原型检测
with_prototype(); # 不建议的调用方式,会给出警告
with_prototype(1,2,3); # 不建议的调用方式,会给出警告
&with_prototype(); # 跳过原型检测
&with_prototype(1,2,3);
在位置(2)处,可通过如下几种方式分别调用without_prototype和with_prototype:
without_prototype;
without_prototype 1,2,3;
without_prototype(1,2,3);
&without_prototype;
&without_prototype(1,2,3);
# 上面的原型子程序要求了不能传递参数,
# 所以调用子程序时不能传递参数
with_prototype;
&with_prototype; # 会跳过原型检测
with_prototype();
&with_prototype(2); # &跳过了原型检测,因此可传递参数
此外,还需理解&调用子程序时,如果不手动传递参数,则会自动将所在环境的@_作为参数传递给子程序。例如:
sub first{
&second; # &subname不手动传递参数
}
sub second{
say "@_";
}
first(1,2,3); # 调用first并传递参数
上面示例中,调用first时传递了参数1、2、3,由于first子程序内部使用&second而非&second(ARGS)方式调用子程序second,由于未手动为second传递参数,因此在调用second时,perl会自动将调用second时所在环境(即first子程序内)的@_作为参数传递给second子程序。因此,first内部的&second等价于&second(@_)。
最后,作为总结,建议第一选择是使用小括号调用方式subname([args]),如果子程序已经定义好,则可以考虑不使用小括号的调用方式subname [args],它们都不会跳过原型检测。如果是调用自己编写的而非从其他模块导入的函数,则可以考虑使用&前缀调用方式。或者,如果明确知道&前缀调用子程序的副作用,也可以考虑使用&前缀相关的几种调用方式。
子程序引用的调用方式
由于Perl还支持子程序引用,因此,除了上述几种调用子程序的方式,还有几种调用子程序引用的方式。
假如$subref是一个子程序的引用,有以下几种调用方式:
&$subref([args])或者完整格式的&{$subref([args])}$subref->([args])&$subref
这里的&前缀仍然具有两层效果:
- 跳过编译器的原型检测
- 如果未手动传递参数,则将当前环境的
@_作为参数传递给子程序
state声明变量
state声明变量
Perl子程序内部还可以使用state关键字来声明一个持久化的私有变量:这个变量只在第一次调用子程序时被初始化,以后调用该子程序时将忽略state声明变量的代码,且子程序外部不能看见这个变量。
state是v5.10添加的功能,因此需加上use 5.010;才能使用state。
例如,定义一个记录子程序被调用总次数的变量:
use 5.010;
sub roll{
state $cnt=0; # 只初始化一次的变量,初始值为0
$cnt++; # 每次调用子程序都自增一次
return 1 + int( rand(6) );
}
state的效果类似于在一个独立的作用域内定义子程序(即类似于闭包):
{
my $cnt = 0;
sub roll{
$cnt++;
say $cnt;
return 1 + int(rand(6));
}
}
roll();
roll();
子程序引用和匿名子程序
子程序引用和匿名子程序
子程序也有引用,创建子程序引用的方式为\&subname。
例如:
my $sub_ref = \&subname;
通过子程序引用调用子程序的方式包括:
- (1).
&$sub_ref([ARGS])或完整格式的&{$sub_ref}([ARGS]),某些时候必须使用完整格式 - (2).
$sub_ref->([ARGS]) - (3).
&$sub_ref或完整格式的&{$sub_ref},某些时候必须使用完整格式
注意,使用&前缀的副作用,它会跳过原型检测,且不手动传递参数时,将会把当前所在环境的@_作为参数传递给子程序。
例如:
sub subname{
say "@_";
}
my $sub_ref = \&subname;
&$sub_ref(1,2,3);
$sub_ref->(11,22,33);
sub f{
&$sub_ref;
}
f(111,222,333);
输出结果:
1 2 3
11 22 33
111 222 333
由于子程序的引用是一个标量变量,因此子程序的引用可以保存到变量、保存到数组或hash。
例如:
sub subname{say "@_"}
my $sub_ref = \&subname;
# 子程序引用保存到数组
my @arr = ($sub_ref);
$arr[0]->(1,2,3); # 调用子程序
&{$arr[0]}(1,2,3); # 必须使用完整格式,不能使用&$arr[0](1,2,3)
# 子程序引用保存到hash
my %h = (
sub1 => $sub_ref,
);
$h{sub1}->(1,2,3);
&{$h{sub1}}(1,2,3); # 必须使用完整格式
不仅可以将子程序引用保存起来,还可以将子程序引用作为参数传递给函数、作为函数返回值返回。
例如:
sub subname{say "@_"}
my $sub_ref = \&subname;
# 子程序引用作为参数传递给函数
# 第一个参数是子程序引用,剩余参数传递给该子程序
sub call_sub_ref{
my $sub_ref = shift;
$sub_ref->(@_); # 或者直接 &$sub_ref;
}
call_sub_ref($sub_ref, 11, 22, 33);
# 子程序引用作为函数返回值
sub return_sub_ref{
sub inner_sub{ say "@_"; }
return \&inner_sub;
}
my $sub = return_sub_ref;
$sub->(111,222,333);
匿名子程序
和匿名数组、匿名hash类似,匿名子程序也是引用。
# 创建匿名子程序的方式
sub {
...
}
一般情况下,会将匿名子程序赋值给某个变量,那么这个变量就是一个子程序引用。
my $sub = sub {
say "@_";
}
$sub->(1,2,3);
也可以将匿名子程序放进数组、hash:
# 匿名子程序放进hash
my %h = (
sub1 => sub { say "sub1: @_"; },
sub2 => sub { say "sub2: @_"; },
);
$h{sub2}->(11,22,33);
还可以将匿名子程序作为参数传递给子程序,或者当作子程序返回值被返回:
# 作为参数被传递
sub subname {
my $sub = shift;
$sub->(11,22,33);
}
subname(sub{say "@_";});
# 返回匿名子程序
sub subname {
return sub {
say "@_";
}
}
my $sub = subname();
$sub->(11,22,33);
Perl子程序的引用计数
Perl中的子程序和标量、数组等类似,它也是保存在内存中实实在在的数据。这和其他语言可能有所区别。
实际上,Perl子程序也有引用计数值:
sub sub1{say "hello";} # 内存中子程序的引用计数为1
my $s = \&sub1; # 内存中子程序的引用计数为2
{
my $ss = $s; # 内存中子程序的引用计数为3
} # 内存中子程序的引用计数为2
当子程序的引用计数值减为0,该子程序将被销毁。
例如:
{
my $sub = sub { say "hello"; }
}
$sub->(); # 报错
当离开大括号语句块时,my声明的私有变量$sub被销毁,使得匿名子程序的引用计数减为0,它被销毁。
需要注意的是,具名子程序的名称是非私有的变量名称,它相当于没有使用my声明的全局子程序名称:
{
sub subname1{say "hello";}
}
subname1(); # 不报错
sub sub1{
sub subname2{say "hello";}
}
subname2(); # 不报错
即使离开了作用域,subname1和subname2子程序仍然有效。
回调函数和闭包
回调函数和闭包
在Perl中,子程序的引用或匿名子程序常用来做回调函数(callback)、闭包(closure)。
回调函数
回调函数的意义是:每触发某种事件就调用一次用户手动指定的函数。这个指定的函数通常通过参数传递。
例如,给子程序传递一个数值,子程序将每0.5秒自增一次该数值,每当数值能被5整除,就执行一次通过参数传递的子程序:
use Time::HiRes qw(sleep);
# subname(Sub, N)
sub subname{
my $sub_ref = shift;
my $cnt = shift;
my $tmp;
while(1){
$tmp = $cnt++;
$sub_ref->($tmp) if $tmp % 5 == 0;
sleep 0.5;
}
}
subname(
sub {say "lalala: @_";}
,3);
上面通过参数传递的匿名子程序sub {say "lalala: @_"}就是回调函数,每当触发某个条件时它就被执行。
再例如,File::Find模块的find函数可用于搜索给定目录下的文件,然后对每个搜索到的文件执行一些操作(通过定义子程序),这些操作对应的函数要传递给find函数,它们就是回调函数。就像unix下的find命令一样,找到文件,然后print、ls、exec CMD操作一样,这几个操作就是find命令的回调函数(或者称为回调命令)。
use File::Find;
sub cmd {
say "$File::Find::name";
};
find(\&cmd, qw(/perlapp /tmp/pyapp));
其中$File::Find::name代表的是find搜索到的从起始路径(/perlapp /tmp/pyapp)开始的全路径名,此外,find每搜索到一个文件,就会赋值给默认变量$_。它代表的是文件的basename,和$File::Find::name全路径不一样。例如:
起始路径 $File::Find::name $_
-------------------------------------------
/perlapp /perlapp/1.pl 1.pl
. ./a.log a.log
perlapp perlapp/2.pl 2.pl
回到回调函数的问题上。上面的示例中,定义好了一个名为cmd的子程序,这个子程序不需要手动去调用,而是将其引用作为参数传递给find函数,由find函数自动去调用它。
由于回调函数通常只作为参数传递给子程序,而不手动调用,因此没必要花脑细胞去设计它的名称,完全可以将其设计为匿名子程序,放进find函数中。
use File::Find;
find(
sub {
say "$File::Find::name";
},
qw(/perlapp /tmp/pyapp)
);
Perl闭包
从Perl语言的角度来简单描述下闭包:子程序1中返回另一个子程序2,这个子程序2访问子程序1中的变量x,当子程序1执行结束,外界无法再访问x,但因为子程序2还引用着变量x所保存的数据,使得子程序2在子程序1结束后可以继续访问变量x所保存的数据。
所以,子程序1中的变量x必须是my声明的词法变量(可简单理解为私有变量),否则子程序1执行完后,变量x仍可以被外界访问、修改,如果这样,闭包和普通函数就没有区别了。
一个简单的闭包示例:
sub sub1 {
my $var1 = 33;
my $sub2 = sub {
$var1++;
}
return $sub2; # 返回一个闭包
}
# 将闭包函数存储到子程序引用变量
my $my_closure = sub1();
子程序sub1内部的子程序$sub2可以访问属于$sub1但不属于子程序$sub2的变量$var1,这样一来,只要把调用sub1返回的闭包赋值给$my_closure,就可以让这个闭包函数一直引用$var1变量所保存的数据。并且,离开了sub1,除了$my_closure,没有任何其他方式可以访问$var1所保存的数据。当sub1执行完毕后,外界也将没有任何方式去去访问这个数据。
简单来说,sub1退出后,闭包sub2是唯一可以访问sub1中变量的方式。
下面是一个具体的Perl闭包示例:
sub how_many { # 定义函数
my $count=2; # 词法变量$count
return sub {say ++$count}; # 返回一个匿名函数,这是一个匿名闭包
}
my $ref=how_many(); # 将闭包赋值给变量$ref
how_many()->(); # (1)调用匿名闭包:输出3
how_many()->(); # (2)调用匿名闭包:输出3
$ref->(); # (3)调用命名闭包:输出3
$ref->(); # (4)再次调用命名闭包:输出4
上面将闭包赋值给$ref,通过$ref去调用这个闭包,即使how_many中的$count在how_many()执行完就消失了,但$ref指向的闭包函数仍然在引用这个变量,所以多次调用$ref会不断修改$count的值,所以上面(3)和(4)先输出3,然后输出改变后的4。而上面(1)和(2)的输出都是3,因为两个how_many()函数返回的是独立的匿名闭包。
Perl语言有自己的特殊性,它的某些语句块具有独立的作用域环境。例如,只执行一次的语句块(即用一对大括号{}包围)。这使得Perl中的闭包并非一定要嵌套在一个子程序中,也可以将闭包函数放在一对大括号中:
my $closure;
{
my $count=1; # 随语句块消失的词法变量
$closure = sub {print ++$count,"\n"}; # 闭包函数
}
$closure->(); # 调用一次闭包函数,输出2
$closure->(); # 再调用一次闭包函数,输出3
在上面的代码中,$count所指向内存数据的引用计数在赋值时为1,在sub中使用并赋值给$closure时引用计数为2,当离开大括号代码块的时候,$count被销毁,该内存数据的引用计数减1,此时闭包$closure仍在引用该数据。
值得注意的是,Perl中的子程序也保存在内存中,它也是一份实实在在的数据,这一点和其他语言可能不太一样。上面的示例中,在大括号语句块中,$closure引用这个子程序数据,当离开大括号时,$closure仍是有效变量,它依然引用这个子程序数据,使得该子程序不被销毁。
如果确实想要定义只在某范围内有效的子程序,可开启Perl的特性use feature 'lexical_subs'。此时可定义my sub或state sub,这种方式定义的子程序只在某作用域内有效。例如:
no warnings "experimental::lexical_subs";
use feature 'lexical_subs';
sub whatever {
my $x = shift;
my sub inner {
... do something with $x ...
}
inner();
} # 退出后,inner()失效
关于my sub和state sub相关的细节,参考perldoc perlsub中的Lexical Subroutines段落。
闭包的注意事项
对于下面的示例:
{
my $count=10;
sub one_count{ ++$count; }
sub get_count{ $count; }
}
one_count();
one_count();
say get_count(); # 输出12
但如果将调用子程序的语句放在代码块前面呢?
one_count(); # 1
one_count(); # 2
say get_count(); # 输出:2
{
my $count=10;
sub one_count{ ++$count; }
sub get_count{ $count; }
}
上面输出2,这暗示了$count=10的赋值行为尚未进行。这是因为my声明的词法变量和它的初始化过程是在编译期间完成的,而赋值操作是在执行到赋值语句时进行的。所以,当编译完成后进入运行期间,在执行到one_count()这条语句时,将调用已编译好的子程序one_count,但这时$count的赋值还没有执行。
可以将上面的语句块加入到BEGIN块中:
one_count(); # 11
one_count(); # 12
say get_count(); # 输出:12
BEGIN{
my $count=10;
sub one_count{ ++$count; }
sub get_count{ $count; }
}
state修饰符替代简单的闭包
闭包的作用是为了让my声明的词法变量不能被外部访问,但却让子程序持续访问它。
Perl v5.10提供了一个state修饰符,它和my完全一样,都用于声明私有的词法变量,唯一的区别在于state修饰符使得变量持久化,且state修饰的变量只会初始化赋值一次。
注意:
- state修饰符不仅仅只能用于子程序中,在其他语句块中也可以使用,例如find、grep、map、循环中的语句块
- 只要没有东西在引用state变量所指向的数据,它指向的数据就会被回收
- 目前state只能修饰标量,可以修饰数组、hash的引用变量,因为引用就是个标量
例如,将state修饰的变量从外层子程序移到内层子程序中。下面两个子程序等价:
use 5.010; # for state
sub how_many1 {
my $count=2;
return sub { say ++$count };
}
sub how_many2 {
return sub {state $count=2;ay ++$count};
}
my $ref=how_many2(); # 将闭包赋值给变量$ref
$ref->(); # (1)调用命名闭包:输出3
$ref->(); # (2)再次调用命名闭包:输出4
需注意,虽然state $count=2,但同一个闭包多次执行时不会重新赋值为2,而是在初始化时赋值一次。
而且,将子程序调用语句放在子程序定义语句前面是可以如期运行的(前面分析过,闭包不会如期运行):
my $ref=how_many2(); # 将闭包赋值给变量$ref
$ref->(); # (1)调用命名闭包:输出3
$ref->(); # (2)再次调用命名闭包:输出4
sub how_many2 {
return sub {state $count=2;say ++$count};
}
这是因为state $count=2是闭包函数的一部分,无论在哪里调用到它,都会执行它,只不过会它只被初始化一次。
再例如,state用于while循环的语句块内部,使得每次迭代过程中都持续访问这个变量,而不会每次迭代都初始化:
use v5.10; # for state
while($i<10){
state $count;
$count += $i;
say $count; # 输出:0 1 3 6 10 15 21 28 36 45
$i++;
}
say $count; # 输出空
原型子程序
原型子程序和函数签名
通常情况下,使用如下方式定义子程序:
sub subname{
BODY
}
这种方式定义的子程序参数是很自由的,可以随意传递参数到子程序,它们都会保存到@_,参数相关的处理需要操作@_,也即在运行时处理参数。
Perl还支持定义原型子程序,定义原型子程序要求在子程序名称后加上括号,括号内可能包含一些特殊的用于表示原型的元字符。
例如:
sub proto_sub($){
say "@_";
}
该原型子程序要求调用proto_sub时,需要传递一个且必须是一个标量参数(严格来说是进入标量上下文,会转换为标量数据)。
定义原型子程序后,在编译期间,会检查所有调用原型子程序的代码,检查调用原型子程序时传递的参数是否符合原型定义。如果不符合,将编译错误(编译错误而非运行时错误)。
因此,在一定程度上,原型可以作为限制子程序的参数类型、参数数量的一种手段。它有点类似于函数签名,但不同于函数签名。在后面,将介绍Perl中支持的函数签名功能。
需要注意,以sigil前缀&调用子程序时会跳过编译期间的原型检测。因此,如非必要,否则不要使用&subname的方式调用原型子程序。
原型字符
Perl的原型由几种具有特殊意义的字符来表示。例如,下面是官方手册中(perldoc perlsub)给出的原型子程序定义示例:
sub mylink ($$) mylink $old, $new
sub myvec ($$$) myvec $var, $offset, 1
sub myindex ($$;$) myindex &getstring, "substr"
sub mysyswrite ($$$;$) mysyswrite $buf, 0, length($buf) - $off, $off
sub myreverse (@) myreverse $a, $b, $c
sub myjoin ($@) myjoin ":", $a, $b, $c
sub mypop (+) mypop @array
sub mysplice (+$$@) mysplice @array, 0, 2, @pushme
sub mykeys (+) mykeys %{$hashref}
sub mygrep (&@) mygrep { /foo/ } $a, $b, $c
sub myrand (;$) myrand 42
其中:
-
$表示该参数处于一个标量上下文中因此,
sub mylink($$)表示要传递两个参数,这两个参数都会转换为标量数据 -
@和%都表示吞掉剩余所有参数,并进入列表上下文 -
\$、\@和\%分别表示对应的参数必须以$、@和%开头,即必须传递标量变量(而不是字面量标量)、数组变量和hash变量\$更特殊一些,它除了可以传递$标量变量,还可以传递任意标量左值,例如$foo = 7或f()->[0]- 实际上,
\X表示该参数必须以X开头,支持的反斜线原型包括\$ \@ \% \& \*
# 必须传递两个参数,第一个参数会被转换为标量数据 # 第二个参数必须是'@xxx'格式的数组变量 sub f($\@){} -
可使用
\[]对反斜线原型进行归纳。例如\[$@%]表示该参数可以传递$xx、@xx或%xx的任意一种sub f(\[%@$&]){} # 允许的调用方式: f %x; f @x; f $x; f &x; -
;用于分隔强制参数和可选参数,分号左边的参数不可省略,右边的参数可省略。显然,@或%前使用;没有意义,因为它们表示的列表本身就允许是空列表# 必须传递2个或3个参数,第三个参数可选 sub f($$;$){} -
+表示该参数可以是数组变量或数组引用,或者是hash变量或hash引用-
无论该参数传递的是数组变量还是数组引用,都会自动转换为数组引用,同理hash变量也会转换为hash引用
-
使用该原型时,有必要在代码体中检测引用的类型是数组引用还是hash引用
sub f(+){say "@_"} my @arr=(1,2,3); f @arr; # ARRAY(0x557c8cb6ba38) f \@arr; # ARRAY(0x557c8cb6ba38)
-
-
&表示该参数是一个匿名子程序或子程序引用,当它作为第一个参数时,可省略sub关键字以及该参数后的逗号分隔符。这是一个非常有趣的语法,甚至它可以实现新的Perl语法,比如可以实现类似于grep {} @arr的语句块用法,在perldoc persub中也给出了通过该功能实现try{}catch{}语法# 类似于map的功能 sub f(&@){ my $sub_ref = shift; my @arr=(); for (@_){ push @arr, $sub_ref->($_); } return @arr; } my @arr = f { $_ * 2 } 11,22,33; say "@arr";
函数签名
函数签名
Perl支持函数签名的功能,目前函数签名还是实验阶段的功能,未来可能会发生改变。
要使用函数签名,需要先开启签名特性。且默认会给出该实验特性的警告,可禁用该警告。
use feature 'signatures';
no warnings 'experimental::signatures';
例如:
use feature 'signatures';
no warnings 'experimental::signatures';
sub f($num1, $num2){
return $num1 + $num2;
}
say f(3, 5);
这表示将调用子程序f(3,5)时传递的两个参数分别保存到标量变量$num1 $num2中,这两个标量变量是该子程序的词法变量,只在该子程序作用域内可见。
如果调用子程序时传递的参数(数量)和函数签名不一致,将报错。
上面使用函数签名的子程序,其功能等价于下面手动处理参数的子程序:
sub f{
die "arguments too long" if @_ > 2;
die "arguments too short" if @_ < 2;
my $num1 = $_[0];
my $num2 = $_[1];
return $num1 + $num2;
}
最简单的函数签名是没有任何参数的签名。如下(注意小括号不能省略):
use feature 'signatures';
no warnings 'experimental::signatures';
sub f(){}
这表示调用子程序f时,不能传递任何参数。
函数签名和原型
Perl函数签名和子程序的原型类似,都可以在一定程度上检测参数,且定义子程序时都使用小括号。
为了避免产生歧义,在开启了use feature 'signatures'时可明确使用:prototype属性来声明原型部分。并且,函数签名和原型可以同时存在。例如:
use feature 'signatures';
no warnings 'experimental::signatures';
# 开启了`use feature 'signatures';`后,
# 使用prototype属性定义原型
sub foo :prototype($) {
return $_[@];
}
# 下面的子程序定义中出现两个小括号是合法的
sub bar :prototype($$) ($left, $right) {
return $left + $right;
}
函数签名和原型有很大不同:
- 原型是在编译期间,对子程序调用传递的参数进行检查
- 函数签名是在运行期间,像其他编程语言一样处理函数参数,而不再需要手动操作
@_来管理参数。它在一定程度上也能检测参数
这里需要注意的是,和其他语言不一样,Perl的函数签名是在运行期间(子程序被调用准备开始执行时)生效,而不是在编译期间生效。
函数签名和@_
虽然使用函数签名时,perl会自动将传递的参数赋值给签名中指定的变量。但函数签名和@_不冲突,使用函数签名时,仍然可以去操作@_。
实际上,函数签名处理的参数和@_中保存的参数是有区别的:
- 函数签名的设置保存的变量是参数的拷贝,函数内修改参数变量不会影响外部数据
@_中保存的参数是外部数据的别名引用,函数内修改@_内的元素会影响外部数据
因此,函数签名设置的参数变量,等价于手动将@_内的元素的值赋值给了函数内的私有变量。
例如:
use feature 'signatures';
no warnings 'experimental::signatures';
sub ff($a, $b){
$a++;
$_[1]++;
say "in routine: $a, $_[1]";
}
my ($x, $y)=(33, 44);
ff($x, $y);
say "outer data: $x, $y";
输出结果:
in routine: 34, 45
outer data: 33, 45
函数签名的用法细节
定义子程序时,函数签名的小括号总是书写在代码体大括号的前面。函数前面的前面可能是子程序名称、原型或子程序属性定义。总之,函数前面之后必须紧跟着大括号代码体。例如:
sub f($left, $right){
return $left+$right;
}
当调用带有函数签名的子程序时,总是先处理签名部分:将调用子程序时传递的参数赋值给签名中指定的参数变量。如果参数处理成功,则开始进入执行子程序的代码体,如果签名参数处理失败(比如参数数量不合理),将报错。
位置参数
函数签名中,使用$开头的标量变量是位置参数。调用子程序传递参数时,会根据签名中的参数书写位置决定如何赋值。
例如,下面的函数签名表示接收两个参数,分别赋值给私有的标量变量$left $right。
sub f($left, $right){
return $left+$right;
}
位置参数是强制的,函数签名中有几个位置参数(形参),调用子程序时就必须传递几个实参数据。
如果想忽略传递的某个参数,使用不带变量名的$符号即可:
sub ff($first, $, $third){
say "$first, $third";
}
虽然ff()的第二个参数被忽略,但调用ff子程序时,也必须传递该位置参数。也即调用ff()时,必须要有三个参数。
可选参数:默认值参数
可以为位置参数设置默认值,带有默认值的参数也被称为非必须的可选参数:
sub ff($num1, $num2=10){
return $num1 + $num2;
}
此时调用ff子程序可以传递两个参数,也可以只传递一个参数,该参数将被分配给$num1,同时$num2采用默认值10。
注意,参数默认值是在调用子程序时处理参数的运行期间进行评估计算的,因此,某个参数的默认值可以是它前面的参数变量。另一方面,参数默认值只在缺失该参数时才评估。例如:
# 如果只传递一个参数,则默认$num2等价于$num1
sub ff($num1, $num2=$num1){
return $num1 + $num2;
}
# 如果传递两个参数,则不进行自增操作
my $auto_id = 0;
sub fff($name, $id=$auto_id++){
return "$name, $id";
}
可选参数(即默认值参数)必须放在位置参数的后面:
sub f($one, $two, $three=3){}
# 错
sub f($one, $two=2, $three){}
可使用多个默认值参数,此时将根据位置对应分配:
sub f($one, $two, $three=3, $four=4){}
f(11,22,33); # $three=33,$four=4
数组或hash:吸收多个参数
函数签名中可使用@前缀的参数变量,表示定义一个私有的数组变量,并吸收剩余所有参数,将这些参数保存到该数组变量中。
sub f($one, $two, @others){}
f(1,2,3,4,5,6);
#=> @others=(3,4,5,6,7)
上面的子程序中,如果只传递两个参数,则@others数组为空数组。
函数签名中的@也可以不跟名称,这样可以取消调用子程序时的参数数量,同时又无需处理多余参数:
# 可以传递两个或两个以上任意多的参数
sub f($one, $two, @){}
还可以使用%前缀的参数变量,表示定义一个私有的hash变量,并吸收剩余所有参数,将这些参数成对地保存到hash变量中。如果吸收的参数数量是奇数,则报错。将剩余参数保存为hash时,所有作为key的参数都将被转换为字符串,且如果key相同,则后出现的覆盖先出现的键值对。
例如:
sub f($one, %persons){}
同样,函数签名中的%可以不带名称,此时它可以用来检测它所吞掉的剩余参数数量是否是偶数个:
sub f($one, %){}
由于@和%会吞掉剩余所有参数,因此在函数签名中,它们必须放在签名的最后面。
my、our和local
my、our和local
在Perl中,my、our和local都可以用来声明变量:
my $a; my ($x, $y);
our $a; our ($x, $y);
local $a; local ($x, $y);
它们声明的变量在作用域内存活的时间以及操作的目标数据不同:
- my声明的变量和其指向的内存都在自己的作用域内生效,退出作用域后,变量失效,其指向的内存被回收
- our声明的变量是私有变量,但其操作的内存数据,或者说它指向的是同名全局变量对应的内存数据,退出作用域后,该私有变量失效,但在作用域内修改的全局数据会直接写入同名全局变量对应的内存并持久生效。
- 实际上,our声明的就是私有全局变量,如果已经存在our声明的全局变量,再次our声明该变量将给出警告
- local声明的变量是私有变量,但其操作的内存数据,或者说它指向的是同名全局变量对应的内存数据,它只是临时操作全局同名变量的数据。在作用域内修改全局数据时,其他地方(比如多线程时)也可以看到对该数据的临时修改,当退出作用域后,该私有变量失效,其临时操作的数据被全局原始数据重新覆盖
- 实际上,local会先找到全局同名变量,再建立它们的关系,如果找不到全局同名变量,将报错
因此:
## my
my $a = 33;
{
# 声明私有变量$a,但赋值表达式右边的$a是全局变量
my $a = $a + 1;
say "$a"; # 输出私有变量$a:34
}
say "$a"; # 输出全局变量$a:33
## our
our $b = 33; # 声明全局$b
{
our $b = $b + 1; # 给出警告,第二次声明全局$b,它们指向同一个位置
say "$b";
}
say "$b";
## local
local $c = 33;
my $d = 33;
our $e = 33;
{
local $c = $c + 1; # 报错,找不到全局$c变量
local $d = $d + 1; # 报错,找不到全局$d变量
local $e = $e + 1; # 正确,关联全局$e
say $e; # 34
} # 退出该作用域之前,任何地方看到的全局$e都是此处修改后的值
say $e; # 33
文件句柄和读写文件
Perl通过文件句柄(file handle)来处理文件数据:打开某文件时指定一个文件句柄,之后通过这个文件句柄来读写该文件的数据。例如:
# 读:打开/tmp/a.log文件,准备从/tmp/a.log文件中读取数据
open my $fh, "<", "/tmp/a.log";
my @lines = <$fh>; # 读取所有行保存到@lines数组中
# 写:打开/tmp/b.log文件,准备向/tmp/b.log文件中写入数据
open my $fh, ">", "/tmp/b.log";
print $fh "hello world\n"; # 向/tmp/b.log写入数据
从示例代码大概可以知道,文件句柄是一种特殊的标量变量。
在IO角度上看,文件句柄和操作系统的文件描述符(File Descriptor)类似,操作文件句柄是操作文件描述符更高层次的封装,它类似于C语言标准IO库的IO流(io stream)或其他语言标准IO库的文件对象。
Perl在文件句柄层次提供了比文件描述符层次更多的功能,比如数据缓冲功能、换行符识别处理功能,等等。如果关闭文件句柄的所有高级功能,则表示使用裸文件句柄,即等价于直接使用底层的文件描述符。
open打开文件
open打开文件
Perl使用open函数打开文件并指定稍后要操作该文件所对应的文件句柄。open函数的用法较为复杂,通常采用以下两种形式:
open FILEHANDLE,EXPR # 两参数的open
open FILEHANDLE,MODE,FILE # 三参数的open
两参数的open是比较古老的用法,它更简洁但不安全(比如可以注入删除所有文件的命令),三参数的open是推荐的用法。对于个人写的Perl脚本而言,如果能够确保自己知道不同用法的行为,那么可使用任何一种形式。
例如,打开/tmp/a.log文件以备后续读取其中内容:
open my $fh, "</tmp/a.log"; # 两参数形式
open my $fh, "<", "/tmp/a.log"; # 三参数形式
open的第一个参数my $fh表示声明一个标量变量作为文件句柄,如果之前已经声明好变量,则可以省略my关键字。
<表示以只读方式打开文件/tmp/a.log,这和Shell的输入重定向符号一样。实际上,Perl还使用>表示以覆盖写方式打开文件,>>表示以追加写方式打开文件,这都和Shell中的重定向语法一致。
# 覆盖写方式打开/tmp/x.log:将先清空文件
open my $fh, ">", "/tmp/x.log"; # 三参数形式
open my $fh, ">/tmp/x.log"; # 两参数形式
# 追加写方式打开/tmp/y.log
open my $fh, ">>", "/tmp/y.log";
open my $fh, ">>/tmp/y.log";
< > >>等符号表示打开文件的模式:以只读、覆盖写或者追加写模式打开文件。如果省略打开模式,则默认以只读方式打开文件。因此,下面两种写法等价:
open my $fh, "<", "/tmp/a.log";
open my $fh, "/tmp/a.log";
打开文件有时候会失败,比如文件不存在、没有权限打开文件、打开文件的数量达到了上限,等等。当open打开文件失败时,将返回布尔假值,同时将操作系统的报错信息设置到特殊变量$!中。很多时候,open会结合or die一起使用,表示打开文件失败时直接报错退出:
open my $fh, "<", "/tmp/a.log" or die "open file failed: $!";
# 或者换行书写:
open my $fh, "<", "/tmp/a.log"
or die "open file failed: $!";
另外需要注意,无论是(类)Unix系统还是Windows系统,文件路径都使用/作为路径分隔符。例如,打开Windows系统C分区路径下的一个文件:
open my $fh, "<", "C:/a/b/c.txt";
操作文件句柄后,如果可以确定不再使用该文件句柄来读写数据,则需要使用close函数关闭文件句柄。这样可以尽快回收资源,否则如果存在大量未关闭的文件句柄,可能会达到操作系统设置的文件打开数量上限。
open my $fh, "<", "/tmp/a.log" or die "can't open file: $!";
...
close $fh or die "close failed";
幸运的是,Perl会在离开作用域时自动回收文件句柄,这使得写Perl代码时可以不用太过于关注关闭文件句柄这件事情。更详细的细节将在后面的章节展开描述。
{
open my $fh, "<", "/tmp/a.log" or die "can't open file: $!";
...
} # 离开作用域时自动关闭文件句柄$fh
非变量形式的文件句柄
除了标量变量形式的文件句柄,Perl还允许使用大写的裸字(bareword)文件句柄,这种文件句柄是比较古老的用法,目前仍然支持,且有一部分预定义的文件句柄仍然采用这种形式的文件句柄,比如名为DATA的文件句柄。
例如:
open FH, "<", "/tmp/a.log";
这表示打开/tmp/a.log文件,并指定名为FH的文件句柄与之关联。
在某些场景下,这种写法比较简洁,只要看到是大写的裸字,基本上可以推断它是一个文件句柄。但这种用法有时候不安全,因为这种裸字文件句柄是全局的,退出作用域后Perl不会自动关闭回收这种文件句柄,而且可能会影响程序的其他地方或受其他地方的影响。
例如:
{
open FH, "/tmp/a.log" or die;
} # 退出作用域后,文件句柄仍然可用
理解文件IO的读写偏移指针
当在Perl中使用open函数打开文件时,Perl会请求操作系统的open系统调用,由操作系统的open系统调用来打开文件,操作系统会为本次open操作分配一个文件描述符并反馈给perl。在Perl层次上,perl会维护指定的文件句柄与该文件描述符的关系。
操作系统打开文件时,操作系统还会为本次open操作维护一个文件的IO偏移指针,IO偏移指针决定了下次读、写操作从哪个位置开始。例如,某次操作后IO偏移指针的位置在第100个字节处(第99字节后第100字节前的中间位置),那么下一次读取或写入操作将从第100个字节处开始读取,如果读取或写入了10个字节,则更新偏移指针到109字节位置处,再下次的读取或写入将从第109字节位置处开始。
需要记住的是,以不同方式打开文件时,IO偏移指针初始放置的位置不同:
-
以只读方式打开文件时,偏移指针初始时被放置在文件开头,即第1个字节前,使得下次读取操作可以从第一个字节开始读取
-
以覆盖写方式打开文件时,会先清空文件,并将偏移指针放置在文件开头,使得下次写入操作会从第一个字节处开始写入
-
以追加写方式打开文件时,不会清空文件,而是直接将偏移指针放置在文件的尾部,即最后一个字节之后,使得下次写入操作会将数据追加在文件的最尾部
需要注意,每一次open操作都有属于自己的IO偏移指针,open同一个文件两次,操作系统会分别为这两次open维护两个IO偏移指针,这两个偏移指针互不影响。比如在Perl中读写文件句柄1,只会更新文件句柄1对应的IO偏移指针,不会影响文件句柄2对应的IO偏移指针。
但是,打开同一个文件多次并通过多个文件句柄操作同一个文件时,可能会让读写的数据变得混乱。例如,两次以追加写方式打开文件,初始时它们的文件偏移指针都在文件的尾部,比如在100字节位置处,当通过文件句柄1写入10字节数据,这只会更新文件句柄1对应的偏移指针到109字节处,文件句柄2对应的偏移指针仍放置在100字节处,如果此时通过文件句柄2写入8个字节,之前写入的10字节数据的前8个字节将被覆盖。
打开文件句柄:读取数据
打开文件句柄:读取数据
Perl中使用一种特殊的菱形操作符<>来读取文件句柄中的数据:<$fh>表示从文件句柄$fh中读取数据。
例如:
open my $fh, "<", "/tmp/a.log" or die "open file failed: $!";
my @lines = <$fh>;
print "$lines[0]";
上面打开文件/tmp/a.log后,使用<$fh>从文件句柄$fh中读取数据保存到数组@lines中,最后输出数组第一个元素,即输出文件中第一行数据。
<>操作符是一种按行读取的迭代器:
- 如果是在列表上下文读取数据,则一次性读取文件中所有剩下的行,每行数据作为列表的一个元素
- 如果是在标量上下文读取数据,则只读下一行数据
- 如果是在空上下文读取数据,则只读下一行数据,并丢弃该行数据
例如:
open my $fh, "<", "/tmp/a.log" or die "open file failed: $!";
my $line1 = <$fh>; # 读取第一行保存到$line1变量
my $line2 = <$fh>; # 读取第二行保存到$line1变量
my $line3 = <$fh>; # 读取第三行保存到$line1变量
<$fh>; # 读取第四行数据并丢弃
my @lines = <$fh>; # 读取第五行开始的剩余所有行,保存到数组@lines
更多时候是在while循环中按行读取数据:
while(my $line = <$fh>){...}
while的条件部分是标量上下文,因此上述代码表示:每次读取一行数据,然后执行一次循环体,直到读取完所有行。当达到文件尾部没有更多数据可读时,<>操作符返回undef,while循环条件为假,循环退出。
在此需要注意,<>操作符如果读取到一个数值0或空字符串,它赋值给变量时返回的也表示布尔假,但不会导致while循环退出。这是因为Perl会自动识别并处理while结合<>的情况,它会转变为下面这种安全的循环代码:
while(defined (my $line = <$fh>)){...}
不仅如此,while结合<>操作符时,会将每次所读取的行自动赋值给默认变量$_。但若不在while中,空上下文<>所读取的行将被丢弃:
while(<$fh>){print $_;}
不建议在for或foreach中读取文件数据。如下:
for(<$fh>){
print $_;
}
因为for或foreach在列表上下文,它会一次性读取文件所有数据放进内存,然后迭代列表的每一个元素(即每一行数据),这意味着可能会一次性消耗很多内存来容纳文件的所有数据。而使用while来循环读取数据,则每次只消耗一行数据的内存来保存每次循环过程中所读取的那一行数据。当然,for遍历文件每一行数据在效率上要稍微高一些些,因为它是一次性读取,其缺点是可能会消耗大量内存。
读取文件内容的常规操作
读取文件内容时,通常采用如下步骤:
while(my $line = <$fh>){
chomp $line;
...
}
# 更简化的代码
while(<$fh>){
chomp;
...
}
# 或者读取的所有数据保存到数组时
my @lines = <$fh>;
chomp @lines;
之所以读取每一行之后要使用chomp处理一次,是因为<$fh>读取的每一行数据会保留每一行的尾部换行符。大多数情况下,尾部换行符不利于数据的处理。比如将读取的行划分为多个字段时,最后一个字段将带有换行符。再例如下面直接输出每一行:
while(<$fh>){
say $_;
}
# 输出:
#hello world 1
#
#hello world 2
#
#hello world 3
#
输出的每一行内容后都有一个空行。
再例如,直接输出保存了每行数据的数组:
my @lines = <$fh>;
say "@lines";
# 输出:
#hello world 1
# hello world 2
# hello world 3
#
上面代码输出的每一行(除了第一行)前都有一个空格。
因此读取每一行之后的第一步通常是去除尾部换行符,并在需要的时候手动加上尾部换行符。
while(<$fh>){
chomp;
say; # 或者print "$_\n";
}
区分记录和行
前文一直在说,<$fh>会按行读取每一行内容,这种说法不严谨。
严格来说,<$fh>是根据记录分隔符(由特殊变量$/控制记录分隔符)从文件中每次读取一条记录(record),每次读取文件数据时,会逐字符从前先后扫描文件的每一个字符,直到遇到$/所指定的记录分隔符才停止扫描,这部分数据(包括记录分隔符)是本次读取的一条记录。
例如,修改$/的值,使每次读取到空格为止:
open my $fh, "<", "/tmp/a.log";
$/ = " ";
my $word = <$fh>; # 只读取一个单词
默认情况下,$/的值是换行符,即每次读取在遇到换行符时停止,因此一条记录就是一行数据,此时按记录读取和按行读取是同一个概念。
如果将$/设置为文件中不存在的字符,<$fh>在读取过程中直到文件尾部也找不到记录分隔符,这意味着会一次性读取文件的所有数据。
特殊地:
- 如果将
$/设置为undef,则一次性读取文件所有数据 - 如果将
$/设置为空字符串,则按段落读取,每次读取一段。连续空行将被压缩为单个空行并属于前一段落
例如,/tmp/a.log文件的内容如下:
$ cat /tmp/a.log
line 1
line 2
line 3
line 4
按段落读取/tmp/a.log文件:
open my $fh, "<", "/tmp/a.log" or die "open file failed: $!";
$/ = "";
while(<$fh>){
print $_;
say "----------";
}
直接修改$/变量会影响全局,比较安全的做法是在一个独立的作用域内临时设置$/变量(使用local修饰),这样离开作用域后会自动恢复为原来的记录分隔符:
open my $fh, "<", "/tmp/a.log" or die "open file failed: $!";
{
local $/ = "";
while(<$fh>){
print $_;
say "----------";
}
}
值得注意的是,chomp函数也是根据$/去除字符串尾部字符的,默认情况下$/的值是换行符,因此chomp默认去除字符串尾部换行符,如果将$/设置为空格,则chomp去除的将是尾部空格。
打开文件句柄:写入数据
打开文件句柄:写入数据
以可写方式(覆盖写方式或追加写方式)打开文件后,可使用print、printf或say来向指定的文件句柄中写入数据。
# 以追加写方式打开文件
open my $fh, ">>", "/tmp/a.log";
# 通过文件句柄向文件尾部追加一行数据,不带换行符
print $fh "hello world 1";
# 再次使用printf向文件中追加一行数据
printf $fh "%s\n", "hello world 2";
# 使用say追加一行数据
say $fh "hello world 3"
使用非变量文件句柄写入数据也是一样的:
open FH, ">", "/tmp/b.log";
# 覆盖写入
print FH "hello world 1";
printf FH "%s\n", "hello world 2"; # 追加到行尾
say FH "hello world 3" # 追加到行尾
需要注意,以覆盖写方式打开文件时,只会在打开的时候清空文件,之后的每次写入都根据文件偏移指针的位置来写入,而不是每次写入都会覆盖之前已经写入完成的数据。
此外,使用标量变量方式的文件句柄进行写入时,容易产生歧义。例如,下面的print操作是向终端输出$fh的值还是向$fh文件句柄中写入空字符串数据呢?
print $fh;
为了解决这种歧义,Perl允许使用大括号包围print/printf/say后的文件句柄:
print {$fh} "hello world 1";
say {FH} "hello world 2";
默认的输出文件句柄
如果print/printf/say没有指定要向哪个文件句柄写入数据,默认是向STDOUT输出。即,下面是等价的:
print "hello world";
print STDOUT "hello world";
STDOUT是perl中一个预定义的文件句柄,它代表标准输出。默认的标准输出的目标是终端屏幕,因此,print/printf/say默认会将要输出的数据打印在屏幕之上。
可使用perl提供的select函数来选择其他文件句柄作为默认输出的文件句柄:
# 选择$fh作为默认的输出文件句柄
select $fh;
# 向$fh写入数据
print "hello world";
select在选择默认文件句柄时,会返回当前的默认文件句柄。因此,下面的代码表示设置默认的文件句柄为$fh,同时备份当前默认的文件句柄:
my $oldfh = select($fh);
修改默认文件句柄后,在一些操作之后,通常会恢复原来的默认文件句柄。惯例的操作为:
my $oldfh = select($fh); ... ; select($oldfh);
特殊的文件句柄
特殊的文件句柄
Perl支持一些特殊的、已经预定义的文件句柄,包括:STDIN、STDOUT、STDERR、ARGV和DATA。
其中:
- STDIN、STDOUT和STDERR分别代表标准输入、标准输出以及标准错误
- ARGV代表由perl命令行参数列表各文件组成的文件句柄
- DATA代表perl脚本程序文件内位于
__END__或__DATA__之后的内容组成的文件句柄
特殊地,Perl还支持菱形操作符内不指定任何文件句柄的读取操作<>,这表示空文件句柄。
STDIN
STDIN是预定义的标准输入文件句柄,STDIN是只读文件句柄,不能向STDIN写入数据。
当使用<STDIN>时,表示从标准输入中读取数据。
while(<STDIN>){
chomp;
say $_;
}
标准输入的数据默认来自于用户在终端的输入,也可能来自于shell中的管道、shell的标准输入重定向,等等。例如,对于名为a.pl的Perl脚本,代码内容如上,运行它:
# 等待用户在终端输入
$ perl a.pl
# 来自于管道的标准输入
$ echo "hello world" | perl a.pl
# 来自于shell标准输入重定向
$ perl a.pl <a.log
STDOUT
STDOUT是预定义的标准输出文件句柄。print/printf/say的输出默认都是写入STDOUT。
# 写向标准输出,两者等价
print "hello world\n";
print STDOUT "hello world\n";
默认情况下,标准输出的输出目标是终端屏幕,但可以在shell中改变标准输出的输出目标。例如,输出给管道、输出到文件等等。
# 标准输出的目标是管道
$ perl a.pl | cat
# 标准输出的目标是文件
$ perl a.pl >/tmp/a.log
ARGV
ARGV代表当前正在读取的来自命令行参数的文件对应的文件句柄,它是只读文件句柄。
例如,perl a.pl a.log b.log,如果在a.pl中使用了ARGV文件句柄,那么在处理a.log文件时,它对应的是a.log文件对应的文件句柄,当处理b.log时,它对应的是b.log文件对应的文件句柄。
通常,<ARGV>会简写成不带任何字符的<>,但注意,它们不等价,参考前文对<>的解释。
例如,从命令行指定的参数文件中读取数据:
#!/usr/bin/env perl
while(<ARGV>){
print "line number: $., content: $_";
}
执行:
$ seq 3 5 >a.log
$ seq 6 10 >b.log
$ perl a.pl a.log b.log
line number: 1, content: 3
line number: 2, content: 4
line number: 3, content: 5
line number: 4, content: 6
line number: 5, content: 7
line number: 6, content: 8
line number: 7, content: 9
line number: 8, content: 10
从结果可以看出,<>或<ARGV>在切换文件时,是不会自动切换行号的。如果想要在切换文件时重置行号,官方文档给出了一个方案:
while(<>){
print "$.\t$_";
} continue {
close ARGV if eof;
}
也可以很容易地自己实现,遍历@ARGV即可,因为它保存了所有的命令行参数:
for(@ARGV){
open my $file, $_;
$. = 1;
while(<$file>){
print "$.\t$_";
}
}
注意,要区分几种ARGV表达的不同含义:
@ARGV:保存了所有的命令行参数,是一个数组$ARGV[n]:表示访问@ARGV数组的第n+1个元素ARGV:当前正在处理的命令行参数文件(即@ARGV中的元素)对应的文件句柄$ARGV:当前正在处理的命令行参数文件(即@ARGV中的元素)对应的文件句柄对应的文件名
push(@ARGV, 'a.log');
push(@ARGV, 'b.log');
while(<>){ # 将自动打开a.log,读完a.log后自动打开b.log
if(eof){
say "$.: $ARGV"; # 分别输出a.log和b.log
close ARGV;
}
}
空文件句柄
默认情况下,空文件句柄读取操作<>表示读取标准输入,此时<>等价于<STDIN>。
例如,读取标准输入中的所有数据并输出行号和内容:
while(<>){
print "$.\t$_";
}
但<>不总是等价于<STDIN>。实际上,如果给定了命令行参数,空文件句柄读取操作<>将优先打开命令行参数代表的各个文件,此时<>等价于<ARGV>。
$ perl a.pl a.log b.log
也就是说,如果指定了命令行参数时(严格来说是@ARGV数组不为空时),<>将等价于<ARGV>,表示从命令行参数对应的文件中读取数据,即使此时向标准输入中传递了数据,也不会读取标准输入。
如果指定了命令行参数的同时,也想要读取标准输入,此时应该在命令行参数合理的位置上使用-来代表标准输入的文件名。
# <>将先读取标准输入,再读取a.log,再读取b.log
$ perl a.pl - a.log b.log
# <>将先读取a.log,再读取标准输入,再读取b.log
$ perl a.pl a.log - b.log
DATA
DATA是一个伪文件句柄。
Perl允许直接在当前源代码文件的最尾部定义数据,这些数据要么是用来测试,要么是临时数据。定义的方式如下:
... some perl code ...
# 从__DATA__或__END__开始的数据都将被DATA文件句柄读取,直到文件结尾
__DATA__
...一些待读取数据...
当perl编译器遇到__DATA__或__END__了,就知道这个源文件的代码部分到此结束,下面的数据都将作为当前文件内有效的DATA文件句柄的数据流。
例如:
#!/usr/bin/perl
while(<DATA>){
chomp;
print "read from DATA: $_\n";
}
__DATA__
first line in DATA
second line in DATA
third line in DATA
last line in DATA
Inline::Files
DATA伪文件句柄的一个缺点是从遇到__DATA__或__END__起直到文件的尾部,都属于DATA文件句柄的内容,也就是说在源代码文件中只能定义一个伪文件句柄。
在CPAN上有一个Inline::Files模块,它可以在同一个源代码文件中定义多个伪文件句柄。需要先安装:
cpan install Inline::Files
例如:
use Inline::Files;
use 5.010;
say "@main::FILE1";
say "@main::FILE2";
while(<FILE1>){
say "$_";
}
while(<FILE2>){
say "$_";
}
__FILE1__
first line in FILE1
second line in FILE1
third line in FILE1
__FILE2__
first line in FILE2
second line in FILE2
third line in FILE2
它像ARGV一样,在运行程序初始阶段就打开这些虚拟文件句柄,并将每个虚拟文件句柄保存到@<PACKNAME>::<HANDLE>中。例如,上面的是示例是在main包中定义了FILE1和FILE2两个文件句柄,那么这两个文件句柄将保存到@main::FILE1和@main::FILE2中,并在处理某个文件句柄的时候,将其保存到标量$main::FILE1或$main::FILE2中。
可以同时定义多个名称相同的虚拟文件系统。例如:
__FILE1__
...
__FILE2__
...
__FILE1__
...
这时在@<packname>::FILE1数组中就保存了两个元素,当处理第二个FILE1的时候,将自动重新打开这个文件句柄。
一般来说,这些就够了,更多详细的用法请参见官方手册:Inline::Files。
理解输出时的块缓冲和行缓冲
理解输出时的块缓冲和行缓冲
使用print和printf输出数据时,如果输出的内容不带换行符,则默认会等待一段时间后才输出:等待换行符的出现,或者等待文件句柄被关闭,或者其他情况。
# 两秒后print输出的内容才会显示出来
print "hello world 1";
sleep 2;
# print输出的内容带有换行符,直接输出而不等待
print "hello world 2\n";
sleep 2;
之所以会有这样的现象,是因为print/printf/say等函数输出的内容会先被缓冲在perl为文件句柄维护的缓冲空间(io buffer)内,当达到一定条件后,缓冲空间中准备输出的内容才会交给操作系统,由操作系统负责最终的写入操作。
Perl文件句柄的IO缓冲方式分为三种:
- 按行缓冲:输出的数据先写入缓冲空间,直到写入换行符,才将缓冲空间的内容刷出交给操作系统
- 按块缓冲:输出的数据先写入缓冲空间,直到写入缓冲空间的数据达到一定字节数量(perl默认缓冲空间大小是8K),才将缓冲空间的内容刷出交给操作系统
- 无缓冲:输出的数据不经过缓冲空间,每次写入操作都直接交给操作系统
按行缓冲和按块缓冲时,除了满足以上列出的换行符条件和字节数量条件,在Perl种还有其他情况会立即输出:
- 缓冲空间已满(即达到8K)时,会立即输出
- 关闭文件句柄时(包括退出perl程序时自动关闭文件句柄的情况),会立即输出
- 手动执行flush操作时,会立即刷出给操作系统
默认情况下:
- 输出到标准输出的终端数据是按行缓冲的,即写入STDOUT文件句柄的数据在遇到换行符之前不会输出
- 输出到标准错误的数据是无缓冲的,这样可以立即输出错误信息,即写入STDERR文件句柄的数据会立即输出
- 输出到管道、文件、套接字的数据是块缓冲的,直到缓冲一定数量的数据之后才会输出。但输出到管道和套接字的数据往往不应该按块缓冲
回到上面的示例,print输出不带换行符的数据时会缓冲等待一段时间,输出带换行符的数据时会立即输出。原因就在于这两个print操作都是向STDOUT写入输出,而写入STDOUT的数据默认是按行缓冲的,这意味着遇到换行符之前、缓冲空间满之前、关闭STDOUT之前(包括退出程序时的自动关闭)、手动flush之前,数据都会先缓冲在buffer中。
再例如,下面向某个文件中写入少量数据,由于写入文件的操作默认是按块缓冲,因此数据会一直缓冲在该文件句柄的io buffer中,直到程序退出(程序退出时会自动关闭所有打开的文件句柄):
# 写入文件的操作,10秒后退出程序前才会写入到文件中
open my $fh, ">>", "/tmp/a.log";
say $fh "hello world";
sleep 10;
在Perl中,可通过修改特殊变量$|来设置文件句柄的缓冲模式:
- 该变量设置为非0数值,表示无缓冲
- 设置为数值0(默认值),表示按块缓冲
设置$|时要求先使用select选择该文件句柄作为默认输出文件句柄。因此,通常的操作步骤如下:
my $oldfh = select($fh); $| = 1; select $oldfh;
或者,使用IO::Handle提供的面向对象语法来设置缓冲模式:
# Perl v5.14版及之后的版本可不用use导入IO::Handle
use IO::Handle;
$fh->autoflush(1);
例如,下面的两个print操作将会立即输出,而不会等待10秒后才输出:
$| = 1; # 或:STDOUT->autoflush(1);
print "hello world";
print "WORLD";
sleep 10;
目录句柄
目录句柄
目录句柄和文件句柄类似,可以打开它,并读取或迭代目录中的文件列表。只不过需要使用:
- opendir替换open函数
- 使用readdir来替换readline,readdir在列表上下文返回一个文件列表,在标量上下文则迭代读取下一个文件名
- readdir不会递归到子目录中
- readdir取得的文件名不包含父目录自身,只包含它所读取目录内的文件名部分
- 使用closedir来替代close
- 注意每个Unix的目录下都包含两个特殊目录
.和..
注:除了打开目录句柄读取目录中的文件名外,还可以通过通配模式来匹配或迭代文件。
例如:
$dir = "/usr/local/java";
opendir JAVAHOME, $dir
or die "Can't open dir: $!";
foreach $file (readdir JAVAHOME){
say "filepath: $dir/$file";
}
closedir JAVAHOME;
从Perl v5.012版本开始,可以直接在while循环中使用readdir。例如:
use 5.012;
$dir = "/usr/local/java";
opendir(my $dh, $dir) || die "Can't open $dir: $!";
while (readdir $dh) {
say "filepath: $dir/$_";
}
closedir $dh;
如果想要跳过.和..这两个特殊的目录,需要加上判断:
use 5.012;
$dir = "/usr/local/java";
opendir(my $dh, $dir) || die "Can't open $dir: $!";
while (readdir $dh) {
next if $_ =~ /^\.{1,2}$/;
say "filepath: $dir/$_";
}
closedir $dh;
通配模式
通配模式
Perl中使用glob函数来通配文件,支持的通配语法如下:
\ 转义下一个通配元字符
[] 字符类,可通配中括号中的单个字符,可使用范围模式
{} 多模式,例如`a{a,b}c`可通配aac和abc
* 匹配任意长度的字符(无法通配文件名开头的点)
? 匹配任意单个字符(无法通配文件名开头的点)
~ 家目录
例如,glob("*.sh")将匹配当前目录下的所有sh脚本文件。
glob函数在列表上下文中返回所有通配成功的文件列表,在标量上下文则迭代每个被通配成功的文件名,迭代完成后返回undef值。
# 当前目录下所有文件(不会递归子目录)
while(glob("*")){
say $_;
}
注意,glob内部使用的是Csh通配规则,因此会识别通配表达式中的空格,并根据空格划分token。例如,glob("*.c .*.c")是两个通配表达式,表示通配c文件和以点开头的c文件,它们是逻辑或的关系。glob("* .*")表示通配当前目录所有文件(包括.和..)。
如果想明确表示通配表达式中的空格是通配表达式中的一部分,而不是将其作为分隔符,需要将通配表达式整体进行引用包围。例如glob('"*e f*"')或者glob(q("*e f*"))。
因此,当通配符中使用了变量时,最好将它使用引号包围起来,避免变量值中包含空格。
glob通配时不会递归到子目录中去通配,如果也想要搜索子目录中的文件,可考虑使用find而不是通配。
通配操作也并非总是用来通配,它的{}通配语法也可以用来生成字符串:
$ perl -E '@arr = glob("a{b,c}d{e,f}h");say "@arr"'
abdeh abdfh acdeh acdfh
<>中的通配语法
<>除了可以用来读取文件句柄,还可以用来进行通配操作。
当perl发现<>中的不是一个标量变量(如$fh)或不是一个裸句柄变量(如STDIN/ARGV),就会将<>中的东西当作通配符进行文件通配。
while(<"*">){ # 通配当前目录的所有非隐藏文件
say "$_";
}
注意,<>中的通配符不像glob()一样会因为空格而划分通配表达式,<>中的通配表达式在转换为内部的glob通配表达式时,默认会在外层加上一层引号。因此,<>中的通配表达式总是单个表达式整体。
# 错误的写法
# 含义是匹配文件名中带有空格和点的文件名
while(<"* .*">){}
File::Glob
默认情况下,glob函数使用的是Csh的通配规则,<>方式的通配内部使用的也是glob,因此也是csh通配。
但有时候,使用csh通配功能会比较受限,如果想要使用功能更丰富的通配,可以使用File::Glob模块。File::Glob模块提供了csh_glob和bsd_glob,csh_glob即核心模块中原始的glob函数,bsd_glob功能则更丰富,它支持为通配规则指定修饰符,比如不区分大小写、家目录扩展等修饰符。
需注意的是,<>方式的通配是根据当前的通配规则来生成文件路径的,因此导入File::Glob的功能时,可能会对<>产生影响,例如导入:nocase属性,将使得<>中的通配不区分大小写,导入:glob将覆盖原始的glob函数,使得<>中的通配采用File::Glob中:glob规则。
使用File::Glob方式很简单:
#!/usr/bin/env perl
use 5.010;
use File::Glob qw(:bsd_glob :csh_glob :globally :nocase);
# 导入:nocase后,通配将不区分大小写
# `<>`方式的通配将不区分大小写
while(<*.LOG>){ say $_; }
# 明确表示使用globally通配,它等价于原生的glob函数
for(globally("*.LOG")){ say $_; }
# 明确表示使用bsd_glob通配
for(bsd_glob("*.LOG")){ say $_; }
# 明确表示使用csh_glob通配
for(csh_glob("*.LOG")){ say $_; }
csh_glob和原始的glob一样,会将通配表达式中的空格识别为分隔符。bsd_glob则不会分隔为多个通配表达式,而是将通配表达式看作是整体。因此,如果想要在bsd_glob中指定多个通配模式,只能使用{}语法,例如bsd_glob("{a*,b*}")等价于csh_glob("a* b*")。
bsd_glob允许指定两个参数,一个是必选的通配表达式,第二个参数是可选的通配修饰符:
my $homedir = bsd_glob('~jrhacker', GLOB_TILDE | GLOB_ERR);
if (GLOB_ERROR) {
# An error occurred expanding the home directory.
}
Perl文件句柄的一些高级话题
Perl文件句柄的一些高级话题
open函数除了> >> <这三种最基本的文件句柄模式,还支持更丰富的操作模式,例如管道。其实bash shell支持的重定向模式,perl都支持,即使是2>&1这种高级重定向模式,perl也有对应的模式。
打开管道文件句柄
Perl程序内部也支持管道,以便和外部命令进行交互。例如,将perl的输传递给cat命令,或者将cat命令执行结果输出给perl程序内部。所以,perl有2种管道句柄模式:句柄到管道、管道到句柄。
例如,将perl print语句的输出,交给cat -n命令来输出行号:
open my $fh, "| cat -n"
or die "Can't open: $!";
say {$fh} "hello world";
say {$fh} "HELLO WORLD";
再例如,将cat -n命令的执行结果通过管道交给perl文件句柄:
open my $fh, "cat -n a.log |"
or die "Can't open: $!";
while(<$fh>){
print "from pipe: $_";
}
虽然只有两种管道模式,但有3种写法:
- 命令(管道)输出到文件句柄模式:
-| - 文件句柄输出到命令(管道)模式:
|- |写在左边,表示句柄到命令(管道),等价于|-,|写在右边,等价于命令(管道)到句柄,等价于-|,可以认为-代表的就是外部命令
上面第三点|的写法见上面的例子便可理解。而|-和-|是作为open函数的模式参数的,以下几种写法是等价的:
open my $fh, "|tr '[a-z]' '[A-Z]'";
open my $fh, "|-", "tr '[a-z]' '[A-Z]'";
open my $fh, "|-", "tr", '[a-z]', '[A-Z]';
open my $fh, "cat -n '$file'|";
open my $fh, "-|", "cat -n '$file'";
open my $fh, "-|", "cat", "-n", $file;
管道还可以继续传递给管道:
open my $fh, "|tr '[a-z]' '[A-Z]' | cat -n";
以读写模式打开
默认情况下:
- 以
>模式打开文件时,会先截断文件,也就是说无法从此文件句柄关联的文件中读取原有数据,且还会清空原有数据 - 以
>>模式打开文件时,会将指针指向文件末尾以便追加数据,但无法读取该文件数据,因为数据在偏移指针的前面
如何以【既可写又可读】的模式打开文件句柄?在Perl中可以在模式前使用+符号来实现。
结合+的模式有3种,都用来实现读写更新操作。含义如下:
+<:read-update,如open FH, "+<$file"提供读写行为。如果文件不存在,则open失败(以read为主,写为辅),如果文件存在,则文件内容保留,但IO的指针放在文件开头,也就是说无论读写操作,都从开头开始,写操作会从指针位置开始覆盖相同字节数量的数据+>:write-update,如open FH, "+>$file"提供读写行为。如果文件不存在,则创建文件(以write为主,read为辅)。如果文件存在,则截断文件,因此这种方式是先将文件清空然后写数据+>>:append-update,如open FH, "+>>$file"提供读写行为。如果文件不存在,则创建(以append为主,read为辅),如果文件存在,则将IO指针放到文件尾部
一般来说,要同时提供读写操作,+<是最可能需要的模式。另外两种模式,如果要读取数据,需要在执行读取操作之前,先将文件偏移指针跳转(使用seek函数)到某个字节位置处,再从指针位置处开始向后读取。
例如,使用+<打开可供读、写、更新的文件句柄,但不截断文件。
open my $fh, "+<", "/tmp/test.log"
or die "Couldn't open file: $!";
open打开STDOUT和STDIN
如果想要打开标准输入、标准输出,那么可以使用二参数格式的open,并将-指定为文件名。例如:
open LOG, "-"; # 打开标准输入
open LOG, "<-"; # 打开标准输入
open LOG, ">-"; # 打开标准输出
没有类似的直接打开标准错误输出的方式。如果有一个文件名就是-,这时想要打开这个文件而不是标准输入或标准输出,那么需要将-文件名作为open的第三个参数。
open LOG, "<", "-";
创建临时文件
如果将open()函数打开文件句柄时的文件名指定为undef,表示创建一个匿名文件句柄,即临时文件。这个临时文件将创建在/tmp目录下,创建完成后将立即被删除,但是perl进程会持有这个临时文件对应的文件句柄直到文件句柄关闭。这样,这个文件就成了看不到却仍被进程使用的临时文件。
什么时候才能用上打开就立即删除的临时文件?只读或只写的临时文件都是没有意义的,只有同时能读写的文件句柄才是有意义的,所以open的模式需要指定为+<或+>。
例如:
#!/usr/bin/perl
use strict;
use warnings;
use 5.010;
# 创建临时文件
open my $tmp_file, '+<', undef or die "open filed: $!";
# 设置自动flush
select $tmp_file; $| = 1;;
# 这个临时文件已经被删除了
system("lsof -n -p $$ | grep 'deleted'");
# 写入一点数据
say {$tmp_file} "Hello World1";
say {$tmp_file} "Hello World2";
say {$tmp_file} "Hello World3";
say {$tmp_file} "Hello World4";
# 指针移动到临时文件的头部来读取数据
seek($tmp_file, 0, 0);
select STDOUT;
while(<$tmp_file>){
print "Reading from tmpfile: $_";
}
执行结果:
perl 22685 root 3u REG 0,2 0 108086391056997277 /tmp/PerlIO_JHnTx1 (deleted)
Reading from tmpfile: Hello World1
Reading from tmpfile: Hello World2
Reading from tmpfile: Hello World3
Reading from tmpfile: Hello World4
内存文件
如果将open()函数打开文件句柄时的文件名参数指定为一个标量变量的引用,也就是不再读写具体的文件,而是读写内存中的变量,这样就实现了一个内存IO的模式。
#!/usr/bin/perl
my $text = "Hello World1\nHello World2\n";
# 打开内存文件以便读取操作
open my $mem_file, "<", \$text or die "open failed: $!";
print scalar <mem_file>;
# 提供内存文件以供写入操作
$log = ""
open mem_file, ">", \$log;
print mem_file "abcdefg\n";
print mem_file "ABCDEFG\n";
print $log;
如果内存文件操作的是STDOUT和STDERR这两个特殊的文件句柄,如果需要重新打开它们,一定要先关闭它们再重新打开,因为内存文件不依赖于文件描述符,再次打开文件句柄不会覆盖文件句柄。例如:
close STDOUT;
open(STDOUT, ">", \$variable)
or die "Can't open: $!";
现在,写向标准输入的数据,都将保存到变量variable中。
Perl的高级重定向
在shell中可以通过>&和<&实现文件描述符的复制(duplicate)从而实现更高级的重定向。在Perl中也同样能实现,符号也一样,只不过复制对象是文件句柄。
例如:
open $fh, ">&STDOUT"
open $fh, ">&", "STDOUT"
open $fh, ">&", "\*STDOUT"
都表示将写入$fh文件句柄的数据重定向到STDOUT所对应的目标文件(可能是普通文件,也可能是终端、管道等)中。
注意第三种写法,不能省略\*STDOUT前面的\*,这是一种比较古老且不推荐的写法,但目前还存在,且有时候必须使用。简单解释一下\*STDOUT的含义,裸字文件句柄(如STDOUT/STDIN)是一种globs符号(symbol),它相当于是一种字符串,和不带引号的裸字符串的含义是类似的。在裸字串前面加上*表示从perl内部的符号表中通配搜索名为STDOUT的符号,如果能搜索成功,那么*BAREWORD代表的就是一种值,它所保存的值,此时*BAREWORD这种写法相当于一种是引用变量的写法$var。前面加上\表示这种特殊变量的引用,此时它和前面示例的\$fh是同一种概念。
注:复制文件句柄时,默认会在内部复制文件描述符,并让新的文件句柄关联这个新的文件描述符。如果只是单纯的想复制文件句柄而不复制底层的文件描述符,使用
>&=语法。如open(ALIAS, ">&=HANDLE"); open ALIAS, ">&=", fileno HANDLE;
shell中很常用的一个用法是&>FILENAME或>FILENAME 2>&1,它们都表示标准错误和标准输出都输出到FILENAME中。在Perl中实现这种功能的方式为:(注意dup目标使用\*的方式,且不加引号)
open my $fh, ">", "/dev/null" or die "Can't open: $!";
open STDOUT, ">&", \$fh or die "Can't dup:$!";
open STDERR, ">&", \$fh or die "Can't dup: $!";
或者简写一下:
open STDOUT, ">", "/dev/null" or die "Can't dup:$!";
open STDERR, ">&STDOUT" or die "Can't dup: $!";
测试下:
open my $fh, ">", "/tmp/a.log" or die "Can't open: $!";
open STDOUT, ">&", $fh or die "Can't dup LOG:$!";
open STDERR, ">&", $fh or die "Can't dup STDOUT: $!";
say "hello world stdout default";
say STDOUT "hello world stdout";
say STDERR "hello world stderr";
会发现所有到STDOUT和STDERR的内容都追加到/tmp/a.log文件中。
如果在同一perl程序中,STDOUT和STDERR有多个输出方向,那么dup这两个文件句柄之前,需要先将它们保存起来。需要的时候再还原回来:
# 保存STDOUT和STDERR到$oldout和$olderr
open(my $oldout, ">&STDOUT") or die "Can't dup STDOUT: $!";
open(my $olderr, ">&STDERR") or die "Can't dup STDERR: $!";
# 实现标准错误、标准输出都重定向到foo.out的功能,即"&>foo.out"
open(STDOUT, '>', "foo.out") or die "Can't redirect STDOUT: $!";
open(STDERR, ">&STDOUT") or die "Can't dup STDOUT: $!";
# 还原回STDOUT和STDERR
open(STDOUT, ">&", $oldout) or die "Can't dup \$oldout: $!";
open(STDERR, ">&", $olderr) or die "Can't dup \$olderr: $!";
IO相关变量
IO相关变量
对应的官方手册:http://perldoc.perl.org/perlvar.html#Variables-related-to-filehandles。
默认情况下:
$/:输入行的分隔符以换行符为单位,可以使用$/指定$\:print输出行的分隔符为undef,可以使用$\指定,例如指定换行符\n$,:print输出列表(也就是每个逗号分隔的部分)的字段分隔符为undef,可以使用$,指定,例如指定空格$":默认在双引号上下文中,数组被输出的时候是使用空格作为分隔符的,可以使用$"指定列表分隔符$.:当前处理到的行号$.。它是一个行号计数器。文件句柄关闭时会重置行号- 由于空文件句柄读取操作
<>从不会显式关闭文件句柄,所以从命令行读取文件时,行号会不断增加
- 由于空文件句柄读取操作
$|:控制写入或输出数据时是否先放进缓冲再刷入文件句柄- 值为0时,表示先缓存,缓冲了一段数据之后再刷入文件句柄通道
- 值为非0时,表示直接刷入文件句柄通道
- 在使用管道、套接字的时候,建议设置为非0值,以便数据能立刻被处理
- 该变量只对写数据或输出有效,对读取操作无效
注意:输出的分隔符只适用于print,不适用say。
操作文件和目录
本章介绍在Perl中如何执行文件和目录相关的操作,包括:
- 通配文件(已经在上一章节介绍过)
- 文件属性测试
- 文件和目录的创建、删除
- 文件和目录的复制、移动、重命名
- 修改文件属性(权限、所有者和所属组、atime/mtime/ctime等)
- 搜索文件
文件属性测试和获取(stat)
文件测试和stat
在Shell中,经常会通过中括号或test命令来测试文件是否存在、是否可读可写可执行等。Perl作为【高级Shell】脚本语言,也可以进行文件测试,并且测试语法和Shell的测试方式非常相似,比如都可以用-e "file"测试file文件是否存在。
文件测试符
Perl中的测试操作都通过一些特殊的测试符进行,测试符均以短横线开头,后面是一个字母。例如-e "file"。在可能产生歧义的情况下,这些测试符可以用括号包围,例如:(-e "a.log")。
在介绍支持的操作符之前,先了解一些测试符的注意事项。
- 测试操作的返回值:
- 返回1表示测试结果为真
- 返回空字符串表示测试结果为假
- 返回undef值表示文件不存在或无法测试,此时会将错误信息设置到
$! - 部分测试符返回具体值,例如测试文件大小的
-s,它返回文件字节数量,空文件时返回0,也可表示布尔假
- 测试符可省略参数,此时默认测试
$_对应的文件名-t测试除外,因为它测试的总是句柄,-t省略参数时默认测试STDIN- 省略参数时很容易出错,因为它们可能会把后面第一个非空白字符串当作测试参数。例如
-s / 1024本意是获得文件大小的KB数量,但却测试了/。如果一定要省略,建议使用小括号包围测试符(-s)/1024
-l测试符测试是否是软链接,它会追踪软链接,如果是软链接但不是有效的软链接,比如目标不存在,将返回undef并报错
Perl支持下面这些操作符,详细说明可参考手册:perldoc -f -X。
| 符号 | 含义 |
|---|---|
| -e | 测试file文件是否存在 |
| -z | 测试file文件是否存在且是否为空,测试目录永远假,因为目录永不为空 |
| -s | 测试file文件是否存在,返回文件字节大小 |
| -f | 文件是否为普通文件 |
| -d | 文件是否为目录文件 |
| -l | 文件是否为软链接(字符链接) |
| -b | 文件是否为块设备 |
| -c | 文件是否是字符设备文件 |
| -p | 文件是否为命名管道 |
| -F | 文件是否为socket文件 |
| -t | 测试文件句柄是否是一个已打开的终端设备 |
| -r | 对effective uid/gid而言,文件是否可读 |
| -w | 对effective uid/gid而言,文件是否可写 |
| -x | 对effective uid/gid而言,文件是否可执行 |
| -o | effective uid是否是文件的所有者 |
| -R | 对real uid/gid而言,文件是否可读 |
| -W | 对real uid/gid而言,文件是否可写 |
| -X | 对real uid/gid而言,文件是否可执行 |
| -O | real uid是否是文件的所有者 |
| -u | 文件是否设置了setuid |
| -g | 文件是否设置了setgid |
| -k | 文件是否设置了sticky |
| -M | 最后一次修改(mtime)距离目前的天数 |
| -A | 最后一次访问(atime)距离目前的天数 |
| -C | 最后一次inode修改(ctime)距离目前的天数 |
| -T | 文件看起来像文本文件 |
| -B | 文件看起来像二进制文件(和-T相反) |
上面-M/-A/-C会计算天数,它是(小时数/24)来计算的。例如,6小时前修改的文件,它的天数就是0.25天。例如:
# 修改文件mtime时间为6小时前
$ touch -m -t "6 hours ago" /tmp/b.log
下面的代码将输出0.25:
print (-M "/tmp/b.log"); # 0.250162037037037
优化测试
每一次测试操作,都是在执行一次stat系统调用,它可能会访问磁盘来获取文件的各种元数据信息(共十三种信息),因此速度很慢。
如果要测试大量文件,且需要测试每个文件的多种属性,重复多次测试将会使效率非常低。例如,要从包含100W个小文件的目录中找出具有可读可写且3天内未修改过的文件(运维的常事),就需要多次对同一个文件进行测试。
每一次测试都是请求stat系统调用,一次stat系统调用本身就会返回文件的所有元数据信息,这些信息可以缓存下来以供后续使用,因此,如果需要测试同一个文件的多个属性,建议只测试一次该文件,并在之后访问缓存下来的该文件信息。
perl每次测试文件时,非常人性化地将文件信息缓存下来了,下次测试该文件时,直接对特殊的测试目标下划线_进行测试即可,这会访问缓存中的信息。
# 测试可读且可写
say "xxx" if -w "a.log" and -r "a.log"; # 不推荐
say "xxx" if -w "a.log" and -r _; # 推荐
_的缓存周期可以延续到下一次对具体文件的测试。例如,下面第三条语句测试的是b.log是否可读。
print "xxx" if -w "a.log";
print "xxx" if -w "b.log";
print "xxx" if -r _;
另一种优化多次测试的方式是连写测试符。
测试符连写
可以将多个测试操作符连在一起写。
- 连写的时候,从右向左依次执行,并按照and逻辑运算符判断真假,即所有测试都为真才返回真
- 对于返回真/假值的测试符,连写的测试符前后顺序不会影响结果
- 对于返回非真/假值的测试符(即
-s/-M/-A/-C),强烈建议不要连写
例如下面两个语句,它们在最终测试结果上是等价的。第一个语句先测试可写性,再测试可读性,只有两者均为真时if条件才为真。
print "xxx" if -r -w "a.log";
print "xxx" if -w -r "a.log";
但是,返回非真/假值的测试符,需要小心小心再小心。例如,-s返回的是文件字节数而非布尔值:
while(<*>){
if (-s -f $_ < 512){ # 这里的结果会出乎意料
print "${_}'s size < 512 bytes\n";
}
}
上面的if条件子句等价于(-f $_ and -s _) < 512,它会输出小于512字节的普通文件,以及所有非普通文件。由于and是短路运算的,如果测试的目标$_不是一个普通文件,而是一个目录,-f $_就会返回假,并结束测试,由于 布尔假对应数值0,使得和512的大小比较永远返回真。
所有,对于返回非真/假值的测试符,应该避免测试符连写:
while(<*>){
if (-f $_ and (-s _) < 512){
print "${_}'s size < 512 bytes\n";
}
}
stat函数和lstat函数
Perl除了支持上面各种测试符来测试文件属性,还支持stat函数获取文件的元数据信息,它们都会发起stat系统调用。
stat函数返回共13项属性信息,这13项属性先后顺序分别是(可随时通过perldoc -f stat查看):
use 5.010;
$filename=$ARGV[0];
my @arr = ($dev,$ino,$mode,$nlink,$uid,$gid,$rdev,$size,
$atime,$mtime,$ctime,$blksize,$blocks)
= stat($filename);
say '$dev :',$arr[0];
say '$inode :',$arr[1];
say '$mode :',$arr[2];
say '$nlink :',$arr[3];
say '$uid :',$arr[4];
say '$gid :',$arr[5];
say '$rdev :',$arr[6];
say '$size :',$arr[7];
say '$atime :',$arr[8];
say '$mtime :',$arr[9];
say '$ctime :',$arr[10];
say '$blksize :',$arr[11];
say '$blocks :',$arr[12];
输出结果:
$dev :2050
$inode :67326520
$mode :33188
$nlink :1
$uid :0
$gid :0
$rdev :0
$size :12
$atime :1533544992
$mtime :1533426824
$ctime :1533426824
$blksize :4096
$blocks :8
各项属性的含义:
| 属性 | 含义 |
|---|---|
| dev | 文件所属文件系统的设备ID |
| inode | 文件inode号 |
| mode | 文件类型和文件权限(两者都是数值表示) |
| nlink | 文件硬链接数 |
| uid | 文件所有者的uid |
| gid | 文件所有者的gid |
| rdev | 文件的设备ID(只对特殊文件有效,即设备文件) |
| size | 文件大小,单位字节 |
| atime | 文件atime的时间戳(从1970-01-01开始计算的秒数) |
| mtime | 文件mtime的时间戳(从1970-01-01开始计算的秒数) |
| ctime | 文件ctime的时间戳(从1970-01-01开始计算的秒数) |
| blksize | 文件所属文件系统的block大小 |
| blocks | 文件占用block数量(块大小一般是512字节,可通过stat -c "%B"命令获取块大小) |
需要注意的是,$mode返回的是文件类型和文件权限的结合体,且文件权限并非直接的8进制权限值,要计算出Unix系统中直观的权限数值(如0755、0644),需要和0777做位与运算。
# 将返回0644、0755类型的八进制权限值
printf "perm :%04o\n",$mode & 0777;
也可以直接从stat结果中取出某项属性的值:
my $mode = (stat($filename))[2];
以下是stat函数的其它一些注意事项:
- stat函数测试成功时,返回属性列表,测试失败时返回空列表
- stat测试成功时,会缓存为
_ - 如果省略stat函数的参数,则默认测试
$_
对于软链接文件,stat会追踪到链接的目标,如果软链接是无效链接(目标不存在),将报错。如果不想追踪,则使用lstat函数替代stat,lstat在测试非软链接以及目标不存在的软链接时,返回空列表。
文件和目录的创建、删除
文件路径处理
Perl没有内置函数可以获取当前工作目录,需要使用其他模块提供的功能。例如Cwd模块(current work directory)提供了cwd函数和getcwd函数可获取当前工作目录的绝对路径,可随便选择使用哪个:
use Cwd;
print cwd();
print getcwd();
Cwd模块还提供了路径处理的功能:abs_path或realpath可获取绝对路径,它们是别名关系。要使用这两个功能,需要手动导入:
use Cwd qw(:abs_path);
print abs_path('../code');
使用chdir()内置函数可以切换当前工作目录:
chdir("/tmp/test/");
但是chdir内置函数不能将~扩展为家目录,并且chdir的切换是全局的,意味着在某处切换会直接影响全局。
File::chdir提供了可局部切换工作路径的方式,建议使用。
先安装:
$ cpan install File::chdir
使用File::chdir的示例:
use File::chdir;
# 全局切换到/var/log/apt目录
$CWD = "/var/log/apt";
say getcwd();
{
# 局部作用域内切换到/tmp
local $CWD = '/tmp';
say getcwd;
}
# 外面仍然是/var/log/apt内
# 可直接修改变量来切换工作目录
# 切换到/tmp/log/apt
$CWD =~ s/var/tmp/;
say cwd;
创建和删除文件
没有直接创建文件的函数,但可以通过open以写模式打开文件再关闭文件的方式来创建文件。
sub touch {
my $path = shift;
return if -e $path;
open my $fh, '>', $path
or die "create file failed: $!";
# close $fh; 退出函数,可省略close操作
}
touch "/tmp/a.log";
删除文件使用unlink函数:
unlink FILE # 删除单个文件
unlink LIST # 删除列表中的所有文件
unlink # 删除$_对应的文件
unlink返回删除成功的数量,如果想要知道哪些文件删除失败,应该迭代遍历然后逐个删除并查看$!获取删除失败的原因。
unlink '/tmp/a.log';
unlink @filelists;
unlink glob('*'); # 删除当前目录下所有非隐藏文件
注意,unlink不能删除目录。
下面是两个示例:使用Perl创建大量小文件,和删除目录中大量小文件。
在当前目录下创建大量随机大小的小文件:
# 第一个参数是要创建的小文件数量
# 第二个参数是小文件的随机大小(kb)
sub create_many_small_files {
my $n=shift;
my $max_size=1024 * shift;
for(1..$n){
open my $f, ">", "$_.txt" or die "open failed: $!";
print {$f} "0" x int(rand($max_size));
close $f or die "close failed: $!";
}
}
# 例如,创建50W个随机0-8K大小的小文件
create_many_small_files 500000, 8
删除大量小文件:
$ perl -e 'unlink <"*.log">'
创建和删除目录
使用mkdir函数来创建目录,创建目录时可指定权限属性。如果创建失败,将返回false并设置$!变量。
mkdir "/tmp/test1";
mkdir; # 等价于mkdir "$_"
mkdir "/tmp/test2", 0755 # 权限不能加引号包围,它是8进制数值
or die "Can't create directory: $!";
mkdir不会递归创建缺失的目录,如果要同时创建缺失的目录,使用File::Path模块中的mkpath函数。稍后再介绍该模块的用法。
删除目录使用rmdir函数,但是rmdir函数只能删除空目录:
rmdir "/tmp/test";
File::Path提供了递归创建缺失目录和删除非空目录的方式:
- mkpath和别名make_path:递归创建缺失的上级目录
- rmtree和别名remove_tree:删除目录树,即删除非空目录
对于mkpath,用法如下:
make_path(dir1,dir2,...,{opts})
#opts可以是以下几种:
mask => NUM # mask和mode是同义词,NUM指定八进制权限值,
mode => NUM # 这种方式指定权限值受umask影响,若目录已存在,则不修改
chmod => NUM # 直接赋予一定权限值,不受umask影响,若目录已存在,则不修改
verbose => $bool # 是否输出详细信息,默认不输出
error => \$err
owner => $owner # 这3条都表示为创建的目录设置所有者,如果已存在,则不设置
user => $user # 可以使用username,也可以使用uid,但如果username无法
uid => $uid # 映射为uid,或者uid不存在,或者无权限的时候,将报错
group => $group # 设置所属组,处理方式和上面所有者的处理方式一样
例如:
use File::Path qw(make_path);
make_path "/test/foo/bar"; # 一次性创建3级目录
make_path "/test/foo1/bar1",{
chmod => 0777,
verbose => 1
}
对于rmtree,用法如下:
rmtree($dir1, $dir2,..., \%opt)
#opts可以是以下几种:
verbose => $bool # 是否显示删除信息,默认不显示
safe => $bool # 删除时跳过无法删除的目标。例如/proc下很多无法删除
keep_root => $bool # 是否保留顶级目录,即只删除子文件和子目录,目录自身不删除
result => \$res
error => \$err
例如:
use File::Path qw(rmtree);
# foo1整个被删除
rmtree '/test/foo1', {verbose => 1};
# foo2的子目录和子文件被删除,foo2被保留
rmtree '/test/foo2', {verbose => 1, keep_root => 1};
文件和目录的复制、移动、重命名
文件和目录的复制、移动
文件拷贝
Perl中使用File::Copy模块的copy函数或cp函数进行文件的拷贝,它不支持目录的拷贝。
该模块中的copy和cp的用法相同,但行为有所不同:copy不会保留源文件的属性,而是遵循目标位置的默认属性,cp会尝试保留源文件属性。
use File::Copy qw(copy cp);
copy '/tmp/a.pl', '/mnt/g/桌面/a.pl' or warn 'copy failed: $!';
cp '/tmp/a.pl', '/mnt/g/桌面/a.pl' or warn 'copy failed: $!';
copy和cp拷贝时,有以下几个注意事项:
- copy和cp拷贝时,是打开源文件获取其中内容,然后在目标位置创建文件并填充内容。因此,copy和cp可以跨文件系统拷贝文件
- 如果目标文件已存在,则会直接覆盖目标文件,不会给出提示信息,除非它是只读文件
- 如果目标位置不存在,比如父目录不存在,则报错
- 如果给定的目标位置是目录,则文件将被拷贝到该目录下
如果要拷贝目录,使用File::Copy::Recursive模块,稍后会给出介绍。
文件移动
File::Path模块还提供了move和mv函数(别名关系)用来实现文件的移动,同样,它们不支持目录的移动。
use File::Copy qw(move mv);
move("/dev1/sourcefile", "/dev2/destinationfile");
mv("/dev1/sourcefile", "/dev2/destinationfile");
mv("/dev1/sourcefile" => "/dev2/destinationfile");
move或mv移动文件时,有以下几个注意事项:
- 只能移动文件,不能移动目录
- 如果目标位置和源文件位置在同一个文件系统,则只是简单的重命名,速度非常快
- 如果不在同一个文件系统,则是拷贝操作,并在拷贝完成后删除源文件,如果拷贝的过程中被中断,源文件和不完整的目标文件都将被保留
- 如果目标位置是一个目录,则文件被移动到这个目录,如果目标位置是一个文件,则移动后将使用该名称作为文件名
- 如果目标位置父目录不存在,则报错
- 它们都会尝试保留源文件的属性
文件重命名
Perl内置了一个rename函数用来文件重命名,它功能比较有限,无法做复杂的重命名,无法跨文件系统重命名,但可以移动文件和目录。
rename '/tmp/empty', '/home/abc/not_empty'
or warn 'rename failed: $!';
虽然自带的rename函数功能受限,但可以使用File::Rename提供的重命名功能:
use File::Rename qw(rename); # hide CORE::rename
# rename( FILES, CODE [, VERBOSE])
rename \@ARGV, sub { s/\.pl\z/.pm/ }, 1;
rename \@ARGV, '$_ = lc';
File::Rename::rename的参数:
- 第一个参数必须是一个数组的引用
- 第二个参数要么是字符串,要么是子程序引用,只要在这部分代码里修改
$_的值,就意味着修改文件名称 - 第三个可选参数表示是否输出详细信息
File::Rename还提供了一个Perl版本的rename命令,重命名的功能非常强,可支持正则替换,支持多表达式。例如:
$ rename 's/\.bak$//' *.bak
$ rename 'y/A-Z/a-z/' *
$ rename 'y/A-Z/a-z/;s/^/my_new_dir\//' *.*
$ rename -E 'y/A-Z/a-z/' -E 's/^/my_new_dir\//' *.*
Perl版本的rename命令可能已经安装好了,可通过man rename来查看rename是不是perl版本的。如果没有安装,可手动安装:
$ cpan install File::Rename
File::Copy::Recursive
File::Copy模块提供的copy和move函数,都无法针对目录进行操作,如有需要,可使用File::Copy::Recursive来拷贝。
use File::Copy::Recursive qw(rcopy rmove
rcopy_glob
rmove_glob);
# 可拷贝文件或目录
rcopy($orig, $new) or die $!;
rmove($orig, $new) or die $!;
# 支持通配的拷贝和移动,采用File::Glob::bsd_glob()的通配规则
rcopy_glob("orig/stuff-*", $trg) or die $!;
rmove_glob("orig/stuff-*", $trg) or die $!;
它们都会尝试保留源文件或源目录的属性。
修改文件和目录属性
获取文件属性
使用stat函数获取文件属性,包括文件权限、所有者、所属组、atime/mtime/ctime、大小等,stat函数前面已经介绍过,可参考前面内容。
修改文件权限
使用内置函数chmod修改权限:
- 可修改单个文件或文件列表内所有文件的权限
- 修改失败时,会设置
$! - 返回成功设置的权限的文件数量
- 只接受8进制的权限值,不允许使用rwx字符串格式的权限字符
例如,设置目录、文件的权限:
chmod 0700, qw(/test/foo /test/foo1/a.log);
chmod 0700, '/test/foo', '/test/foo1/a.log';
修改文件owner、group
使用内置函数chown修改文件的所有者和所属组信息。
chown UID, GID, FILENAME
chown UID, GID, LIST
其中:
- chown可以同时修改单个文件或目录的所有者、所属组,也可以同时修改列表内所有文件或目录的所有者、所属组
- 修改失败时,会设置
$! - 返回成功修改的数量
- chown只接受uid和gid作为参数,不接受username和groupname
- 可使用getpwnam和getgrnam函数将username/groupname映射为uid/gid
- 在uid或gid的参数位置上指定特殊值
-1,表示该位置的所有者或所属组属性保持不变
例如:
chown 1001, 1001, glob '*.log'; # 第一个1001是user位,第二个1001是group位
chown -1, 1002, 'a.log'; # uid不变
如果想按照用户名、组名来设置,使用getpwnam和getgrnam函数:
my $uid = getpwnam 'longshuai' or die "bad user";
my $gid = getgrnam 'longshuai' or die 'bad group';
chown $uid, $gid, glob '*.log';
修改文件时间戳属性:atime/mtime
在Unix系统中,要求操作系统维护atime/mtime/ctime三种文件的时间戳属性:
- atime:access time,文件最近一次被访问时的时间戳
- mtime:modify time,文件内容最近一次被修改时的时间戳
- ctime:inode change time,文件inode数据最近一次被修改的时间戳
touch命令可以修改atime和mtime,ctime是操作系统自身维护的,无法通过上层命令工具直接修改。
Perl的utime函数也可以修改文件时间戳,语法如下:
utime(Atime, Mtime, FILE_LIST)
- 只能修改atime和mtime属性
- 会直接发起系统调用,所以失败时会设置
$! - atime和mtime可以同时定义为undef,表示修改为当前时间
- 但如果只有一个undef,则对应位置的时间戳会设置为1970年
- 它的返回值是成功修改的文件数量
- 如想保持某项时间戳不变,可用stat函数取出当前时间戳值保存下来
例如,下面修改一堆文件的atime为当前时间,mtime为前一小时时间:
my $atime=time;
my $mtime=$atime - 60*60;
utime $atime, $mtime, glob '*.log';
实现touch文件的等同功能:将文件时间戳设置为当前时间:
utime undef, undef, 'a.txt'
or die "touch file failed: $!";
如果只想修改atime,不想修改mtime,则使用stat函数先将当前的mtime属性值取出保存下来:
my $mtime = (stat('a.txt'))[9];
utime time, $mtime, 'a.txt'
or die "touch failed: $!";
其中stat(FILE)[9]对应的属性是mtime,stat(FILE)[8]对应的属性是atime。
find搜索文件
Find搜索文件
Perl的glob通配操作无法递归目录搜索文件,如果要递归搜索,使用File::Find模块或者更友好一些的File::Find::Rule模块。此处仅介绍File::Find模块的用法。
File::Find模块有两个函数find()和finddepth(),后者是前者的一种特殊用法。
use File::Find;
find({ wanted => \&proc, follow => 1 }, @dirs_to_search);
find(\&wanted, @dirs_to_search);
sub wanted { ... }
finddepth(\&wanted, @dirs_to_search);
sub wanted { ... }
find()有两种用法:
- (1).在第一个参数位置指定hash选项,并在hash中指定搜索行为
- (2).在第一个参数位置指定子程序引用,这种方式表示采用默认行为
在wanted子程序中,有三个特殊的变量:
$File::Find::name:保存了当前搜索到的文件的完整路径(并非绝对路径,而是从初始搜索目录开始的路径)$File::Find::dir:保存了当前搜索到的文件的目录部分$_:保存了当前搜索到的文件的文件名部分
在wanted子程序中,有几个注意事项:
- 可使用return来跳过当前文件不处理
- 可设置
$File::Find::prune=1来跳过整个子目录 - 子程序中可能会多次测试文件的属性,可使用缓存的文件句柄
_进行文件属性测试
以find()第二种用法为例,演示find的常规用法。
示例一:搜索某目录内的txt文件。
use File::Find;
my @files;
my @dirpath=qw(/home/user1/);
# 搜索txt文件
find(sub {
if (-f $File::Find::name and /\.txt$/){
push @files, $File::Find::name;
}
}, @dirpath);
print join "\n", @files;
# 或者
sub wanted {
push @files, $File::Find::name if (-f $File::Find::name and /\.txt$/);
}
find(\&wanted, @dirpath);
# 或者
sub wanted {
return unless -f; # 测试$_
return unless /\.txt$/;
push @files, $File::Find::name;
}
find(\&wanted, @dirpath);
示例二:搜索某目录内的子目录文件。
my @files;
my @dirpath=qw(/home/user1);
find(sub {
push @files, $File::Find::name if (-d);
}, @dirpath);
print join "\n",@files;
示例三:搜索最近一天内修改过的文件。
sub wanted {
return unless -f;
return unless int(-M _) < 1; # 测试对$_缓存下来的文件句柄
push @files, $File::Find::name;
}
示例四:搜索最近30分钟内修改过的文件。
sub wanted {
return unless -f;
return unless (-M _) < 0.5/24;
push @files, $File::Find::name;
}
示例五:跳过某子目录。
sub wanted {
$File::Find::prune = 1 if /some_name/;
push @files, $File::Find::name;
}
再回头来看find()的第一种用法。
采用find()第一种方法时,常见的hash选项如下:
- no_chdir:如果搜索到的是子目录,决定是否要进入子目录
- no_dir=1:表示不进入子目录,此时,
$File::Find::name、$File::Find::dir、$_的值是从初始目录开始的完整路径 - no_dir=0:默认值,表示进入子目录,此时
$File::Find::name是完整路径,$File::Find::dir是从初始目录开始到该子目录为止的路径、$_的值文件名(basename)
- no_dir=1:表示不进入子目录,此时,
- wanted:指定每次搜索到文件时执行的操作,是一个子程序的引用
- bydepth:找到子目录时,表示先处理目录内的文件,最后才来处理该子目录自身。
finddepth等价于指定了bydepth=1的find - preprocess:开始搜索每个初始目录前执行的操作,是一个子程序引用
- postprocess:在搜索完每个初始目录之后执行的操作,是一个子程序引用,常用来统计报告所搜索目录的总文件大小
- follow:是否要跟踪软链接,默认follow=0,即不跟踪
关于no_chdir时三个变量的值,参考如下示例数据:
# $File::Find::name $File::Find::dir $_
# no_chdir=>0 / / .
# /etc / etc
# /etc/x /etc x
#
# no_chdir=>1 / / /
# /etc / /etc
# /etc/x /etc /etc/x
日期时间处理
本章介绍在Perl中如何操作日期和时间,比如如何将字符串转换为日期时间来比较。
内容大概包括:
- Perl内置函数time、localtime、gmtime
- Perl更高精确度的标准库
Time::HiRes(可精确到纳秒) - Perl日期时间标准库模块
Time::Piece - Perl最常用功能最丰富的日期时间处理模块
DateTime
time、locatime和gmtime
time
perl内置的time函数获取从1970-01-01 00:00:00开始到现在流逝的秒数,即epoch时间。
$ perl -E 'say time'
1625729583
# date -d@1625729583 +"%F %T" => 2021-07-08 15:33:03
time只能精确到秒级别,如果想要获取更低精度的时间,可使用Time::HiRes模块。稍后再介绍这个模块的用法。
localtime
perl内置的localtime函数,根据给定的epoch时间参数计算对应的时间,如未给定参数,则以当前时间点的epoch作为参数:
- 在列表上下文,返回对应时间的各个日期时间部分
- 在标量上下文直接返回对应的时间点,返回的时间格式为操作系统所默认的格式(即和date命令返回的结果一样)
例如,在标量上下文:
$ perl -E '$a=localtime;say $a'
Thu Jul 8 15:49:01 2021
$ date
Thu Jul 8 15:49:01 CST 2021
在列表上下文:
# 2021-07-08 15:52:11
$ perl -E 'say "@{[localtime]}"'
11 52 15 8 6 121 4 188 0
# 2015-10-20 12:30:22
$ perl -E 'say "@{[localtime(1445315422)]}"'
22 30 12 20 9 115 2 292 0
在列表上下文,localtime返回共9项信息,它们的顺序分别是:
# 0 1 2 3 4 5 6 7 8
my ($sec,$min,$hour,$mday,$mon,$year,$wday,$yday,$isdst) = localtime(time);
即:秒、分、时、日(月中日)、月、年、周中日、年中日、是否夏令时。主要使用的是前6项。
需注意几个事项:
- mon月份的范围是0-11,0表示1月,11表示12月
- year年份的值是从1900年开始的整数值,因此它是2位数或3位数,如果要四位数表示,加上1900
- wday表示的周几,0表示周日,6表示周六
通过localtime得到时间的各部分后,如果要将它格式化为某种格式的日期时间字符串,可考虑使用printf。
my ($S, $M, $H, $d, $m, $y) = localtime;
printf "%04d-%02d-%02d %02d:%02d:%02d\n",1900+$y,1+$m,$d,$H,$M,$S;
但是不推荐这么啰嗦的格式化方式,可引入POSIX中提供的strftime函数来格式化时间:
use POSIX qw(strftime);
strftime("%F %T", localtime); # 2021-07-08 16:00:39
更多日期时间的操作,可使用Time::Piece模块或DateTime模块。
gmtime
gmtime和localtime的用法完全一致,唯一的区别是gmtime将给定的时间参数当作UTC时间,而不是本地时间。
Time::HiRes模块
Time::HiRes模块
Perl内置的time、sleep函数都只能精确到秒,Time::HiRes模块提供了更高精度的相关函数,此外还提供了stat、utime、lstat等函数来提供更高精度的文件属性。
这个模块无需安装,已经内置成为标准模块,但如果要使用里面提供的函数,则需要手动导入。例如:
use Time::HiRes qw(utime usleep sleep gettimeofday);
下面介绍该模块提供的几个常用函数。
-
gettimeofday:获取当前时间点,在标量上下文返回epoch秒和微秒组成的浮点数,在列表上下文返回epoch秒和微秒两个元素。use Time::HiRes qw(gettimeofday); # 标量上下文 my $t0 = gettimeofday; say $t0; # 1625732664.42617 # 列表上下文 say "@{[gettimeofday]}"; # 1625732664 426361 # 可用来衡量某些操作耗时多久,可精确到微秒级 my $start = gettimeofday; ...do something... say getimeofday - $start; -
time:获取当前时间点,返回精确到微秒的浮点数。即等价于标量上下文的gettimeofday。use Time::HiRes qw(time); # 覆盖默认的内置time函数 say time; # 1625732928.18472 -
sleep和usleep和nanosleep:提供可精确到毫秒、微秒、纳秒的睡眠行为。use Time::HiRes qw(sleep usleep nanosleep); # 覆盖默认的内置sleep函数 sleep 3.2; # 睡眠3.2秒 usleep 20000; # 睡眠0.2秒(20000微秒) nanosleep 1000;#睡眠1000纳秒,即1微秒 nanosleep 0; # 效果类似于Thread yield,即直接放弃cpu等待下次调度 -
tv_interval:计算两个时间点的时间差,主要用来计算gettimeofday返回的值的时间差,接收的两个参数均是数组的引用。use Time::HiRes qw(tv_interval gettimeofday); my $t0 = [gettimeofday]; # do bunch of stuff here my $t1 = [gettimeofday]; # do more stuff here say tv_interval $t0, $t1;
Time::Piece模块
Time::Piece模块
Time::Piece提供了一些操作日期时间的方法,用法非常简单,也已经内置到标准库中。如果有Time::Piece不方便解决或无法解决的更复杂的需求,可使用DateTime模块。
注:某些32位计算机中,
Time::Piece最大只能支持2038年,如果需要处理2038年之后的时间,使用DateTime模块。另外,64位则无此限制。
导入Time::Piece模块之后,内置的localtime和gmtime函数将被覆盖,它们将返回一个Time::Piece对象。此外,Time::Piece自身也提供了一个new方法创建Time::Piece对象。
use Time::Piece;
my $t = localtime;
my $t1 = Time::Piece->new;
my $t2 = Time::Piece->new(1625732928);
得到Time::Piece对象后,可以使用一大堆的和日期时间相关的方法:
$t->sec # 获取秒,别名:$t->second
$t->min # 获取分钟,别名:$t->minute
$t->hour # 获取小时(24小时制)
$t->mday # 获取天,即几月几号的几号,别名:$t->day_of_month
$t->mon # 获取月份,1代表一月
$t->_mon # 获取月份,0代表一月
$t->monname # 获取月份简称,如二月是Feb
$t->month # 同上,也是获取月份简称
$t->fullmonth # 获取月份全称,如二月是February
$t->year # 获取4位数的年份
$t->_year # 获取从1900年开始算的年份,如2000年时的值是100
$t->yy # 获取2位数的年份
$t->wday # 获取周几,1代表周日
$t->_wday # 获取周几,0代表周日
$t->day_of_week # 同上,获取周几,0代表周日
$t->wdayname # 获取周几简称,如Tue代表周二
$t->day # 同上
$t->fullday # 获取周几全称,如Tuesday代表周二
$t->yday # 获取一年中的第几天,0代表1月1号,别名:$t->day_of_year
$t->isdst # 是否是夏令时,别名:$t->daylight_savings
$t->hms # 获取小时分钟秒,格式`12:34:56`
$t->hms(".") # 获取小时分钟秒,格式`12.34.56`
$t->time # 同$t->hms
$t->ymd # 2000-02-29
$t->date # 同$t->ymd
$t->mdy # 02-29-2000
$t->mdy("/") # 02/29/2000
$t->dmy # 29-02-2000
$t->dmy(".") # 29.02.2000
$t->datetime # 2000-02-29T12:34:56 (ISO 8601)
$t->cdate # Tue Feb 29 12:34:56 2000
"$t" # same as $t->cdate
$t->epoch # epoch
$t->tzoffset # 时区偏移值,timezone offset in a Time::Seconds object
$t->week # 一年中的第几周(ISO 8601)
$t->is_leap_year # 是否是闰年
$t->month_last_day # 本月的最后一天是几号,值范围:28-31
$t->time_separator($s) # 设置时间分隔符,默认":"
$t->date_separator($s) # 设置日期分隔符,默认"-"
$t->day_list(@days) # 设置周几的默认显示值,周日应作为列表的第一个元素
$t->mon_list(@days) # 设置月份的默认显示值,一月应作为列表的第一个元素
$t->strftime(FORMAT) # 将日期时间格式化为字符串
$t->strftime() # "Tue, 29 Feb 2000 12:34:56 GMT"
$t->truncate # 将日期时间截断到指定单位处。修改的是拷贝的对象。
# 例如$t->truncate(to => 'day')将使时间部分全部为0
# 支持的截断目标:year, quarter, month, day, hour, minute和second
# 根据给定格式,将字符串解析为日期时间对象
Time::Piece->strptime(STRING, FORMAT)
例如:
use Time::Piece;
# 2021-07-08 16:28:48
my $t = Time::Piece->new(1625732928);
say $t->year; # 2021
say $t->hms; # 16:28:48
say $t->ymd; # 2021-07-08
say $t->epoch; # 1625732928
# 设置周和月的默认显示名称
Time::Piece::day_list(qw(周日 周一 周二 周三 周四 周五 周六));
Time::Piece::mon_list(qw(一月 二月 三月 四月 五月 六月 七月 八月 九月 十月 十一月 十二月));
say $t->wdayname(); # 周四
say $t->monname(); # 七月
# 将日期时间格式为字符串
say $t->strftime("%F %T"); # 2021-07-08 16:28:48
# 将字符串根据指定格式解析为日期时间对象
my $t1 = Time::Piece->strptime(1625732928, "%s");
my $t2 = Time::Piece->strptime("2021-07-08 16:28:48", "%F %T");
say $t1->datetime; # 2021-07-08T08:28:48
say $t2->datetime; # 2021-07-08T16:28:48
my $t3 = $t2->truncate(to => 'day');
say $t3->datetime; # 2021-07-08T00:00:00
Time::Piece对象还能进行一些算术运算(仅支持加减秒、月和年以及计算时间差)以及进行大小比较(< > <= >= <=> == !=)。
例如:
# 加减秒、月、年
$t1 - 42; # returns Time::Piece object
$t1 + 533; # returns Time::Piece object
$t = $t->add_months(6);
$t = $t->add_years(5);
# 计算时间差
$t1 - $t2; # returns Time::Seconds object
注意,计算时间差时返回的是Time::Seconds对象,Time::Seconds模块提供了一些秒转换的时间常量(如常量ONE_DAY代表一天的秒数),以及几个简单的时间转换方法(如60秒转换为1分钟)。
# Time::Seconds提供的常量
ONE_DAY
ONE_WEEK
ONE_HOUR
ONE_MINUTE
ONE_MONTH
ONE_YEAR
ONE_FINANCIAL_MONTH
LEAP_YEAR
NON_LEAP_YEAR
# Time::Seconds对象的方法
my $val = Time::Seconds->new(360); # 360秒
$val->seconds; # 360
$val->minutes; # 6
$val->hours; # 0.1
$val->days; # 0.00416666666666667
$val->weeks; # 0.000595238095238095
$val->months; # 0.00013689544435102
$val->financial_months; # 固定30天的月,0.000138888888888889
$val->years;
$val->pretty; # 6 minutes, 0 seconds
通过Time::Seconds提供的常量,可以轻松地对Time::Piece对象加减任意单位的时间。例如:
use Time::Piece;
use Time::Seconds;
# 三天后的时间
my $t = localtime;
my $t1 = $t + 3 * ONE_DAY;
say $t1->datetime;
DateTime模块
DateTime模块
Perl中的一些技巧性语法收集
Perl中的一些技巧性语法收集
Perl中不少常规语法有特殊用法,使得有很多【少为人知】的技巧性写法。本文收集了一些,欢迎大家提供文中未涉及的技巧,感谢。
部分操作符技巧性用法总结:perl secret。
Perl Shell
Perl没有像Python、Ruby一样自带交互式的Shell接口,有时候做些简短的测试没有交互式的Shell不是很方便。但实现起来也很方便:
while(print ">> ") {
chomp ($_ = <>);
/^q$/ && last; # 输入q退出,此外last或exit也可以退出
say "=> ", (eval $_) // "undef";
}
可以设置一个shell命令的命令别名,方便地启动这个简陋但方便的Perl Shell:
alias ipl='perl -E'\''while(print">> "){chomp($_=<>);/^q$/&&last;say"=> ",(eval$_)//"undef";}'\'
可省略token之间的空白
如果两个相邻的token之间连在一起不会产生歧义,那么可以省略这两个token之间的空白分隔符。
print"abc","def\n"; #-> print "abc","def\n"
print$var; #-> print $var
my$var="abc"; #-> my $var
print~~length$var #-> print length $var
但下面写法会被错误解析,它会当作调用print1函数并传递参数3来解析(注意参数是3而不是+3,参见+符号)。
print1+3;
+符号
在某些省略函数调用括号时,为了避免可能产生的歧义,可在第一个参数前使用+,表示让后面的表达式作为函数参数,相当于加了函数调用的括号。
print(3+4)*4; # (1).输出7
print ((3+4)*4); # (2).输出28
print +(3+4)*4; # (3).输出28,等价于(2)
~~强制转换为标量上下文
有些地方需要标量上下文,但可能处于列表上下文环境,可以使用scalar来强制转换为标量上下文,也可以使用~~强转为标量上下文。单个~表示位取反,且要求标量上下文,两个~表示位取反两次,相当于没有取反,因此将上下文强转为标量上下文,但却不影响计算结果。
my @arr = qw(a b c d);
say ~~@arr; # 4
say scalar @arr; # 4
标量上下文中的列表赋值
Perl中的赋值语句有返回值,结合上下文的用法,Perl的赋值操作非常非常灵活。
例如,最简单的赋值语句:
$a = 33; # 赋值语句直接返回所赋值
标量上下文中的列表:
# 变量被赋值为列表最后一个元素
# 赋值语句也返回最后一个元素的值
$a = (11,22,33);
$a = qw(11,22,33);
列表上下文中的列表:
($a, $b) = (11,22,33); # (1)
($a) = (11,22,33); # (2)
($a,$b,$c,$d) = (11,22,33); # (3)
上面这种赋值语句将前后对应逐个赋值,左边多出的变量被赋值为undef,右边多出的数据被丢弃。
但是注意,这种列表上下文中的列表赋值语句的返回值:在列表上下文中返回左边列表,在标量上下文中返回右边列表的长度。
# 赋值语句在列表上下文:
@arr = ($a, $b) = (11,22,33); # @arr = (11,22)
say (($a, $b) = (11,22,33)); # 输出:1122
# 赋值语句在标量上下文
$len = () = (11,22,33); # $len = 3
say ~~(($a, $b) = (11,22,33)); # 输出:3